Dáta, ktoré občas dostanete na analýzu, nie sú zrovna v najvhodnejšom formáte. Jeden z najhorších prípadov je, keď sú síce dáta v tabuľkách správne, ale dostanete ich v úplne denormalizovanej forme. A nasleduje ukrutný dlhý proces normalizácie dát do dimenzných a faktových tabuliek, aby ste to vôbec vedeli pospájať a zanalyzovať. V niektorých prípadoch však existuje oveľa ľahšie riešenie. A tým je technika s kódovým označením monštrózna dimenzia.
Prečo monštrózna dimenzia
Monštrózna dimenzia je technika prípravy dát, keď potrebujete dať dohromady a zanalyzovať dáta z dvoch a viac denormalizovaných tabuliek. Je oveľa výhodnejšia ako klasický proces normalizácie, najmä ak tie dáta potrebujete použiť len na 1-2 reporty. A výsledný produkt je aj z užívateľského hľadiska oveľa ľahšie použiteľnejší.
Ukážeme si to na takomto príklade. Povedzme, že sme dostali zanalyzovať dáta v 2 tabuľkách – Objednavky a Faktury:
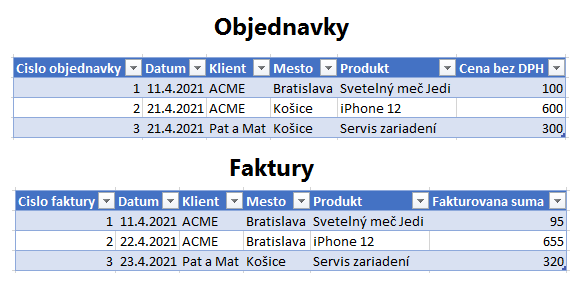
Užívateľ si ich chce dať dokopy v jednom reporte, či už v Power BI alebo v excelovskom PowerPivote. Napríklad preto, aby porovnal, čo bolo objednané s tým, čo bolo vyfakturované.
Klasické riešenia a problémy s nimi
Klasické riešenia spadajú do týchto 2 typov:
- vytvorí sa na obidvoch stranách zlúčený stĺpec zo všetkých stĺpcov, podľa ktorých chceme analyzovať dáta (v tomto prípade stĺpce Datum, Klient, Mesto, Produkt), a cez tento zlúčený stĺpec sa prepoja tabuľky,
- pre každý zoskupovací/filtrovací stĺpec sa vytvorí samostatný číselník, v ktorom budú unikátne hodnoty z pôvodného stĺpca, a cez všetky takéto číselníky sa prepoja tieto 2 pôvodné tabuľky.
Obe riešenia sú fajn, ak tých stĺpcov nie je veľa. A obe majú svoje klady aj zápory. Napríklad v prípade prvého riešenia je problém v tom, že nie vždy viete prepojiť takto tabuľky – výsledný zlúčený stĺpec častokrát nebýva unikátny, a teda treba použiť rôzne náhradné riešenia či neslávne prepojenia typu many-to-many. Ak sa vám to aj podarí, tak užívateľ býva častokrát zmätený, z ktorej tabuľky má vybrať dané pole, napríklad stĺpec Mesto.
Druhé riešenie má zasa problém v tom, že vám to v ponuke dátového modelu či kontingenčky vyrobí viacero tabuliek len s 1 stĺpcom. Čo ani zďaleka nebude vyzerať pekne. Plus, ak zabudnete poskrývať stĺpce v pôvodných tabuľkách, tak máte znova rovnaký problém ako v predchádzajúcom prípade – užívateľ nebude vedieť, z ktorej tabuľky má vybrať dané pole, napr. stĺpec Mesto. A v tomto prípade bude mať na výber až 3 možnosti. A ako naschvál ho to bude nutkať vyberať ho stále z tej nesprávnej tabuľky. Jedno lepšie ako druhé.
Obe riešenia však ešte majú ďalší neblahý efekt – čo keď takýchto stĺpcov v tabuľkách nemáme len 3, ale povedzme 20? Keby sme aj použili riešenia vyššie, tak kto má odvahu povedať užívateľovi, že si má vyrobiť 20 osobitných tabuliek v dátovom modeli, či rovno navrhnúť a vytvoriť vlastný dátový sklad? Len preto, aby jednorazovo zanalyzoval 2 obyčajné tabuľky?
Riešením v tomto prípade môže byť práve monštrózna dimenzia. Ktorá aj z pohľadu užívateľa bude vo výsledku lepšia.
Monštrózna dimenzia
Princíp monštróznej dimenzie je v tom, že zo všetkých stĺpcov, podľa ktorých budeme chcieť vo výslednom reporte zoskupovať alebo filtrovať dáta, vytvoríme spoločnú číselníkovú tabuľku (v dátovom modelovaní nazývanú „dimenzia“). Následne tieto stĺpce z pôvodných tabuliek vyrežeme a nahradíme odkazom na túto novú tabuľku, a cez tento odkaz to prepojíme.
V tomto našom prípade, v prvom kroku „vyrežeme“ stĺpce Datum, Klient, Mesto a Produkt z oboch tabuliek:
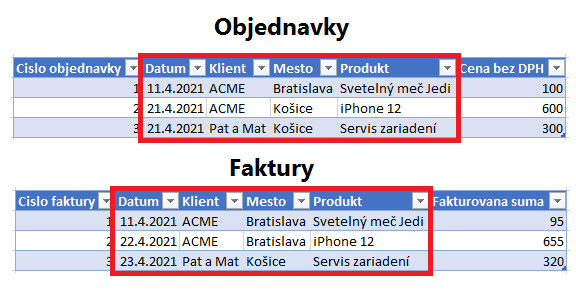
…a z týchto dvoch výrezov vytvoríme novú tabuľku tak, že ich dáme pod seba (zunionujeme ich):
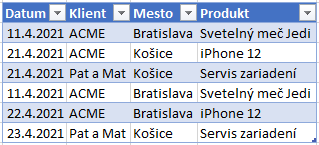
Túto tabuľku nazveme napríklad Polia. Alebo nejakým tvorivejším názvom.
Potom je dobré z tabuľky odstrániť duplicitné riadky. Nie všetky nástroje vám to však dovolia, a ak aj áno, tak to pri väčších dátach môže dlho trvať, nemusí byť na to dostatok voľnej pamäte, a pod.. Takže tento krok nutne nemusíte robiť. Iba v ideálnom prípade, ak si to môžete v danej situácii dovoliť. V našom prípade tento krok odstráni pôvodný 4. riadok, ktorý bol v takejto tabuľke duplicitný:

V ďalšom kroku vyrobíme ID-čka týchto riadkov. Napríklad tak, že ich jednoducho očíslujeme od 1 po N:
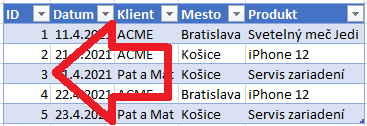
Toto bude naša monštrózna dimenzia. No a potom už len dosadíme tieto ID-čka do pôvodných tabuliek namiesto tých 4 stĺpcov, ktoré sme dali do monštróznej dimenzie:
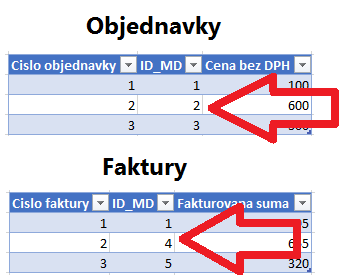
V poslednom kroku stačí tieto 2 tabuľky naimportovať do Power BI, PowerPivotu či ľubovoľného iného klonu PowerPivotu, prepojiť s monštróznou dimenziou cez tie ID-čka, a máme to hotové:
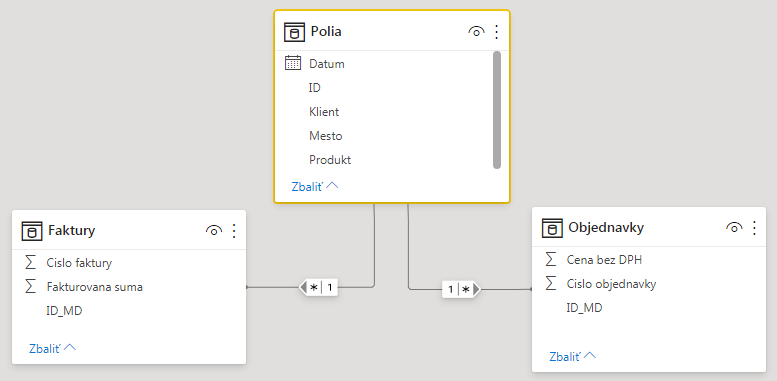
Ponuka takéhoto dátového modelu bude takáto jednoduchá a intuitívna pre užívateľa:
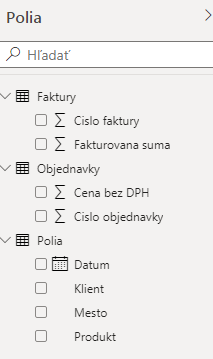
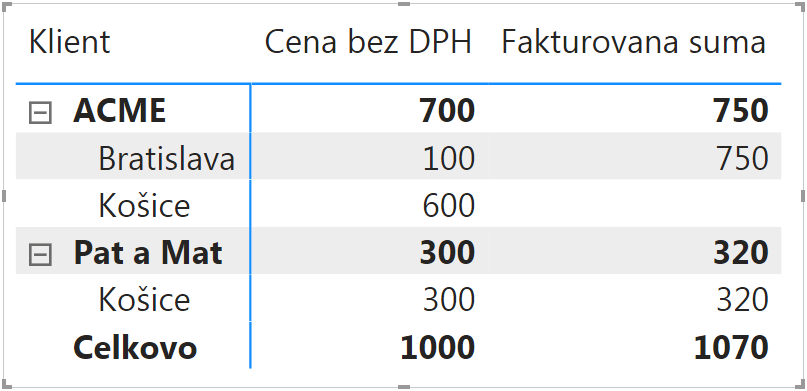
…a samozrejme aj kontingenčky či iné vizualizácie budú fungovať tak, ako majú – napríklad analýza podľa klienta a mesta:
Na záver
Na toto teda slúži monštrózna dimenzia. Na prvý pohľad nie úplne ideálne riešenie, ak by ste na tom chceli stavať veľké dátové sklady a podnikové riešenia. Na druhej strane to však príde vhod, keď dát nie je až tak veľa, potrebujete rýchlo z nich vyrobiť 1-2 reporty, a nechcete celé doobedie stráviť vytváraním 20 tabuliek a ich nekonečným prepájaním. Monštrózna dimenzia vám to vyrieši na pár krokov. Či už to spravíte v Power Query, alebo v inom ETL nástroji. A v tom je jej krása. Pretože nie vždy potrebujete riešiť veci ideálnym spôsobom. A ak sa chcete naučiť ďalšie takéto techniky, tak dôjdite na kurz návrhu dátových skladov. Vo výsledku tým ušetríte kopec času, a naučíte sa okrem ideálnych aj mnohé ďalšie takéto skratkovité riešenia 😉
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.