Power BI, a po novom aj SSAS Tabular 2019, priniesli obrovskú novinku za posledné roky – natívnu podporu pre prepojenia many-to-many pre tabuľky v dátovom modeli, resp. M:N. To znamená, že už v nich viete priamo prepojiť naozaj ľubovoľné tabuľky, bez rôznych trikov. Ako som už viackrát spomínal v starších článkoch, tak tieto prepojenia many-to-many však fungujú mierne odlišne, ako klasické prepojenia 1:N alebo 1:1 v PowerPivote. Preto sa na ne teraz pozrieme bližšie.
Prečo prepojenia many-to-many
Podpora prepojení typu many-to-many bola pridaná kvôli tomu, čo už 10 rokov trápilo všetkých používateľov všetkých verzií PowerPivotu. Ak ste totižto chceli prepojiť 2 tabuľky v dátovom modeli, tak ste museli splniť hneď niekoľko podmienok. A tá najotravnejšia bola taká, že aspoň na jednej strane prepojenia musel byť stĺpec s jedinečnými hodnotami – tzn. s hodnotami, ktoré sa v tom stĺpci neopakujú viackrát. Takáto podmienka nerobila problém, ak ste mali pripravené dáta v dátovom sklade. To však takto mal pripravené len zlomok užívateľov PowerPivotu. Všetci ostatní si buď museli takto upraviť dáta v tabuľkách, alebo použiť na prepojenie medzitabuľku s unikátnym stĺpcom a občas aj daxovými vzorcami. Alebo niektorým z iných spôsobov, o ktorých píšem napr. v mojej knihe o Power BI v texte o prepojeniach typu M:N. A to bolo dosť otravné. A najmä veľakrát to aj skomplikovalo kopec ďalších vecí v dátovom modeli.
Od júla minulého roku ale máme prepojenia typu many-to-many v Power BI, a od marca tohto roku aj v preview verzii SSAS Tabularu 2019 (ktorý poháňa na pozadí Power BI, aké to prekvapenie). Keď teraz máte 2 tabuľky, ktoré potrebujete v modeli prepojiť, ale nespĺňajú tú podmienku s jedinečnými hodnotami v jednom zo stĺpcov, tak ich jednoducho prepojíte týmto novým typom prepojenia. Power BI Vám však vyhodí takéto upozornenie, keď sa o to pokúsite:
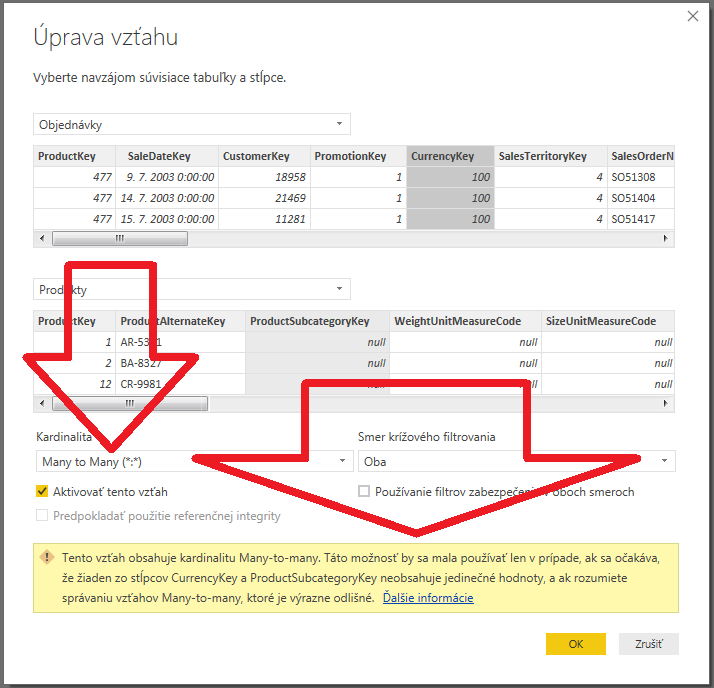
V tom okne sa vás to snaží upozorniť, že tento typ prepojenia použite iba vtedy, ak „rozumiete správaniu vzťahov many-to-many, ktoré je výrazne odlišné“. Väčšina užívateľov to samozrejme prehliadne, pretože to nijak nezabraňuje vytvoreniu prepojenia – kľudne aj medzi stĺpcami s rôznymi dátovými typmi, napr. text na dátum. Ale potom sa neskôr divia, prečo im nesedia niektoré výsledky. Preto sa teraz pozrieme na to, v čom sú tieto prepojenia odlišné, a čo najmä od toho môžete očakávať.
Príklad
Ukážeme si to na extrémne jednoduchom príklade. Majme takéto dve tabuľky:
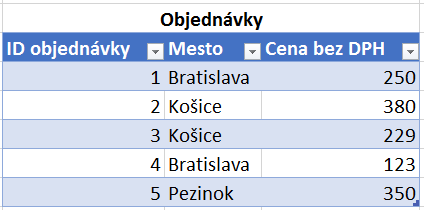
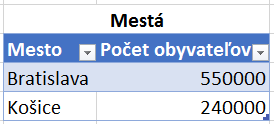
V prvej tabuľke sú objednávky, v druhom je zoznam miest. A teraz tie tabuľky prepojíme cez mestá medzi sebou. Išlo by to aj s klasickým prepojením 1:N, ale my ich schválne prepojíme prepojením many-to-many, a s nastavením obojsmerného filtrovania, nech vidíte rozdiel:
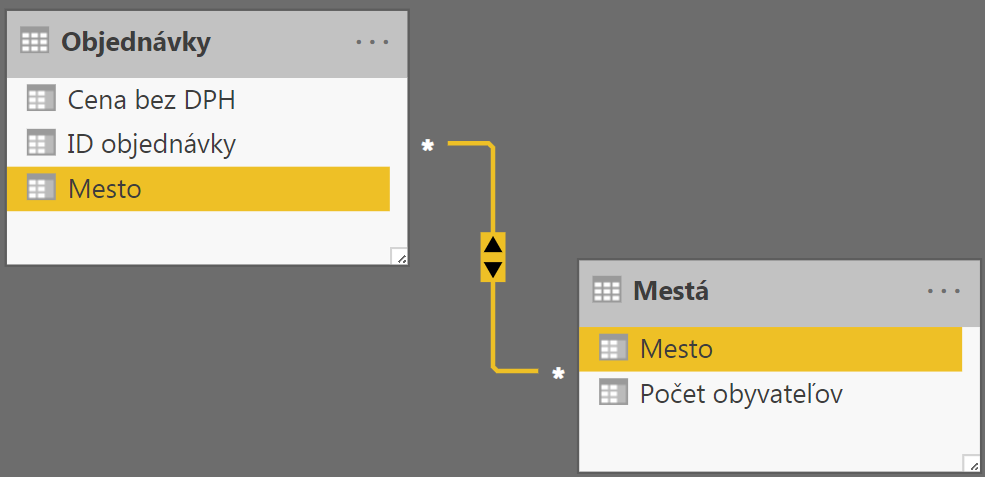
Všimnite si, že medzi tabuľkami je obojsmerná šípka, a zároveň na oboch koncoch prepojenia je hviezdička. Tie hviezdičky na oboch koncoch signalizujú prepojenie typu many-to-many.
Následne si spravíme jednoduchú kontingenčku v reporte, kam pridáme:
- stĺpec Mesto z tabuľky Mestá,
- stĺpec „Počet obyvateľov“ z tabuľky Mestá,
- stĺpec „Cena bez DPH“ z tabuľky Objednávky.
Výsledok bude vyzerať takto:
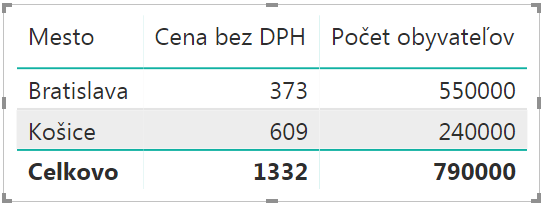
Na prvý pohľad to funguje, ale po bližšom preskúmaní dát a výsledkov tam nájdete hneď 2 chyby:
- v zozname miest chýba Pezinok,
- celkový súčet v stĺpci „Cena bez DPH“ nesedí s číslami, ktoré vidíte v kontingenčke.
Ak by ste tie tabuľky prepojili klasickým prepojením typu 1:N, tak by výsledky boli správne:
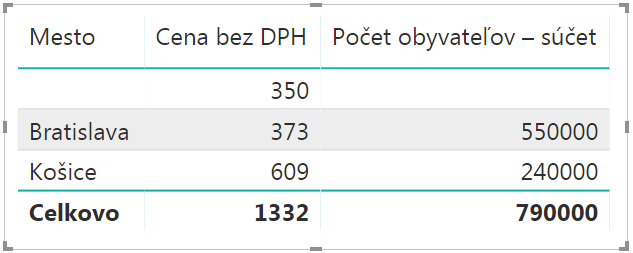
Mesto Pezinok sa síce stále nezobrazuje, pretože nie je tabuľke Mestá, ale namiesto neho sa zobrazuje prázdny riadok. Čo je z pohľadu PowerPivotu správne – viac o tom v tomto článku. To by ste vedeli opraviť tým, že namiesto stĺpca Mesto z tabuľky Mestá by ste do kontingenčky dali stĺpec Mesto z tabuľky Objednávky. Dokonca aj v prípade toho prepojenia many-to-many. Problém však je v tom, že ak si to nevšimnete, alebo neviete o tom, z ktorej tabuľky tam pridať ten stĺpec (čo väčšina užívateľov tak či tak nevie), tak máte problém.
Prečo prepojenia many-to-many tak fungujú
Vrátime sa teda ku kontingenčke, ktorú sme mali vytvorenú na začiatku, a kde boli podkladové tabuľky prepojené pomocou prepojenia many-to-many:
A prečo to vlastne nezobrazuje ten Pezinok, ale v celkovom súčte je započítaná suma všetkých objednávok, čiže aj za Pezinok?
Je to tým, ako fungujú prepojenia many-to-many. Na rozdiel od klasických prepojení, prepojenia many-to-many potrebujú mať 100%-nú referenčnú integritu medzi tabuľkami, aby fungovali tak, ako očakávate. To znamená, že všetky hodnoty v prepájaných stĺpcoch na oboch stranách prepojenia musia mať všetky hodnoty z toho stĺpca na opačnej strane prepojenia. A teda žiaden z tých 2 stĺpcov nesmie obsahovať neplatné odkazy na ten druhý stĺpec. Zatiaľ čo klasické prepojenia sa s neplatnými odkazmi vysporiadali tak, že PowerPivot vytvoril na druhej strane prepojenia skrytý prázdny riadok, na ktorý napojil všetky tieto neplatné hodnoty (tak ako o tom píšem v tomto článku), tak prepojenia many-to-many to tak nerobia. Namiesto toho – veľmi zjednodušene povedané – v prípade detailných dát takéto riadky ignorujú a vôbec ich nezobrazia v kontingenčke/grafe/vizuáli, ale v prípade celkového súčtu ich započítajú do celkových súčtov.
Keď sa pozriete na tabuľku Mestá, tak sú tam iba 2 mestá – Bratislava a Košice. A v tabuľke Objednávky máme 3 mestá – s Pezinkom navyše. Keďže sme do kontingečky dali stĺpec Mesto z tabuľky Mestá, a tam sú iba 2 mestá – Bratislava a Košice – a je to prepojenie many-to-many – tak to na riadkoch kontingečky zobrazí iba tieto 2 mestá. Vďaka tomu, že Pezinok neexistuje v tejto tabuľke, tak ho ani nezobrazí v kontingenčke. Klasické prepojenie 1:N by v takomto prípade v kontingenčke zobrazilo jeden prázdny riadok spoločne pre všetky mestá, ktoré neexistujú v tabuľke Mestá, ale sú v tabuľke Objednávky. Prepojenia many-to-many takúto prázdnu položku nevytvárajú, a ak sa práve nepočíta celkový súčet, tak takéto neplatné položky ignorujú. Preto sa v kontingenčke nezobrazil ani Pezinok, ani prázdny riadok.
Keď sa však počíta celkový súčet, tak tam sa započítajú všetky riadky z tabuliek. Preto je tam celkový súčet v našom prípade 1332, aj keď sú nad ním 2 riadky so sumami 373 a 609, ktoré nedávajú súčet 1332. Rozdiel je práve tá objednávka z Pezinka. Z pohľadu PowerPivotu je to takto správne, ale z pohľadu užívateľa nie. Preto aj to upozornenie na začiatku pri vytváraní prepojenia many-to-many, aby ste si to radšej rozmysleli.
Dôvodom tohto celého je, ako interne funguje PowerPivot pri použití prepojenia many-to-many. Interne to funguje tak, že ak používate klasické prepojenie 1:N, tak si PowerPivot najprv zistí zoznam všetkých miest v riadkoch kontingenčky (resp. na osi budúceho grafu), a potom hromadne pre všetky naraz zistí čiastkové súčty. Čiže to celé spraví v 2 krokoch. Môže si to dovoliť, pretože z jeho pohľadu má vždy dodržanú referenčnú integritu – pretože pre neplatné odkazy na 1-strane prepojenia má vytvorenú tú skrytú prázdnu položku.
Pri prepojeniach many-to-many to funguje inak. Prvý krok je rovnaký – PowerPivot si najprv zistí zoznam všetkých miest v riadkoch kontingenčky (resp. na osi budúceho grafu). Keďže sa však prázdne položky v tomto prípade nevytvárajú, a nemôže teda predpokladať 100%-nú referenčnú integritu, tak nemôže pre všetky mestá naraz zistiť tie jednotlivé súčty. Preto iteruje po jednotlivých mestách, a po jednom spočítava súčty príslušných objednávok. Čo je veľakrát niekoľko násobne pomalšie, ako klasické prepojenia. Tím Analysis Services síce už v posledných mesiacoch spravil nejaké optimalizácie, aby to nebolo až také pomalé, ale bohužiaľ s tým ešte musíte počítať. Minimálne z metodického hľadiska. Jeden čas to dokonca bolo vidieť aj pri debugovaní cez DAX Studio.
Pri celkových súčtoch potom už nie je rozdiel medzi prepojeniami 1:N a many-to-many. Tento krok sa robí už identicky pri oboch typoch prepojení. Má sa spočítať suma celého stĺpca „Cena bez DPH“, a na celú štatistiku je potrebné pristupovať iba do stĺpca „Cena bez DPH“ v tabuľke Objednávky. Takže jednoducho zosumuje celý tento stĺpec bez ohľadu na referenčnú integritu. Preto je v oboch prípadoch celková suma rovnaká.
Toto je teda celá záhada, prečo prepojenia many-to-many fungujú odlišne. A zároveň dosť silný argument na to, aby ste si rozmysleli, či naozaj chcete používať tieto prepojenia, alebo radšej tie klasické prepojenia. S luxusom ľahšieho prepojenia tabuliek totižto občas treba zaplatiť takúto cenu.
Ďalšie rozdiely
Keď sa ešte pozriete do oficiálnej dokumentácie, ktorá vám nepovie o moc viac ako tento článok, tak tam nájdete ešte ďalšie 2 rozdiely:
- pri použití prepojenia many-to-many nemôžete použiť funkciu RELATED na dotiahnutie hodnôt z iných tabuliek cez toho prepojenie, pretože – logicky – na oboch stranách sa môžu nachádzať viaceré príslušné riadky. Preto treba používať funkciu RELATEDTABLE,
- funkcia ALL nefunguje pri odstraňovaní filtrov na opačnej strane prepojení many-to-many. Keď napríklad chcete spočítať celkové predaje – aby ste napr. vedeli spočítať percentuálny podiel predajov v danom meste na celkových predajoch, tak takéto klasické merítko vám nemusí zafungovať:
Celkové predaje = CALCULATE(SUM(‚Objednávky'[Cena bez DPH]); ALL(‚Mestá'[Mesto]))
Namiesto toho je potrebné použiť buď novú syntax funkcie ALL s prázdnymi zátvorkami, alebo funkciu ALLCROSSFILTERED.
A ako z toho von?
Dvoma spôsobmi – buď použitím klasických prepojení, alebo opravením referenčnej integrity. Čiže v našom prípade doplnením Pezinka do tabuľky Mestá. Tento druhý spôsob je síce ideálny, ale nepredpokladám, že je ľahko pre užívateľov dosiahnuteľný. Máme síce Power Query a kopec nástrojov okolo toho, ale aj tak. Pohodlnosť je pohodlnosť… Takže ak nemáte 100% správne dáta a všetky hodnoty v prepájaných stĺpcoch sa nenachádzajú na oboch stranách prepojenia, tak radšej použite klasické prepojenia a jedno z náhradných riešení, o ktorom píšem v mojej knihe o Power BI. Výrazne si tým uľahčíte život.
Tak či tak, prepojenia many-to-many sú skvelá a veľmi vítaná funkcionalita v PowerPivote. Za predpokladu, že máte správne dáta, tak uľahčia prepájanie tabuliek, a aj zjednodušia dátový model, aby v ňom nemuseli byť zbytočne prepájacie medzitabuľky. Pretože to bol hlavný dôvod ich pridania do PowerPivotu. Aby ste si mohli zjednodušiť život. A teraz, keď už viete, ako fungujú, a na čo si dať pozor, tak viete presne zvážiť, či ich bezpečne môžete použiť aj vo vašich reportoch, alebo radšej siahnuť po starých dobrých riešeniach 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.