Jazyk DAX má dve podobné funkcie – DISTINCT a VALUES – ktoré na prvý pohľad robia to isté – vrátia zoznam unikátnych hodnôt. Prečo sú v jazyku DAX ale 2 funkcie? A aký je medzi nimi naozajstný rozdiel?
V tomto prípade je medzi týmito dvoma funkciami nielen jeden rozdiel, ale hneď dva. Prvý zistíte už zo syntaxe, a druhý až tak zjavný nebude.
Keď sa teda pozrieme na syntax týchto dvoch funkcií, tak funkcia DISTINCT má takúto syntax:
DISTINCT(stĺpecAleboTabuľka)
…kde výsledok závisí od toho, či ste na parameter zadali stĺpec alebo tabuľku. Ak ste zadali stĺpec, tak táto funkcia vráti stĺpec, v ktorom budú iba unikátne hodnoty z toho zadaného stĺpca. A ak ste zadali tabuľku, tak výsledkom bude pôvodná tabuľka bez duplicitných riadkov.
Funkcia VALUES má takúto syntax:
VALUES(stĺpec)
Funkcia VALUES vracia stĺpec, v ktorom sú iba unikátne hodnoty z toho zadaného stĺpca.
Prvý rozdiel medzi týmito funkciami je teda zjavný už z ich syntaxe. Jedna berie na vstupe aj stĺpec aj tabuľku, a druhá iba stĺpec.
Keď však zadáte DISTINCT(stĺpec) alebo VALUES(stĺpec), tak podľa definície by mali vrátiť to isté. A dokonca dlhý čas oficiálna dokumentácia spomínala to isté. Prečo by však Microsoft robil na prvý pohľad zbytočne dve funkcie?
Odpoveďou je to, že tieto dve funkcie sa líšia v jednom drobnom detaile – funkcia VALUES za určitých podmienok vracia aj prázdnu hodnotu BLANK, ktorú však nemáte v dátach. A teraz sa pozrieme, kedy sa to môže stať.
Pre demonštráciu si znova zoberieme náš vzorový súbor PowerPivotu, resp. Power BI. A v ňom si vytvoríme buď novú linkback tabuľku (ak ste v Exceli), alebo novú vypočítanú tabuľku. Tá tabuľka bude obsahovať iba unikátne hodnoty z vybraného stĺpca – raz pomocou funkcie DISTINCT, a potom pomocou funkcie VALUES.
Dáme si teda vytvoriť tabuľku, ktorá bude obsahovať iba unikátne hodnoty zo stĺpca CalendarYear z tabuľky Čas. Použijeme teda takýto vzorec:
- v prípade Excelu vytvorte linkback tabuľku so vzorcom: EVALUATE DISTINCT(‚Čas'[CalendarYear])
- v prípade Power BI vytvorte vypočítanú tabuľku so vzorcom: Unikátne roky = DISTINCT(‚Čas'[CalendarYear])
Výsledok bude vyzerať takto:
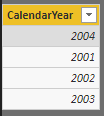
Ako vidíte, vrátilo to stĺpec s unikátnymi rokmi zo stĺpca ‚Čas'[CalendarYear]. Poradie položiek nemusí byť rovnaké ako v pôvodnom stĺpci, a väčšinou to z pohľadu analýz ani nevadí.
Keď teraz zmeníte ten vzorec vyššie na funkciu VALUES(‚Čas'[CalendarYear]), tak výsledok bude rovnaký:
Na prvý pohľad je teda funkcia VALUES zbytočná. Ale nie je.
Vyskúšame to teda na inom stĺpci. Tentokrát na stĺpci ProductCategoryName v tabuľke Kategórie. Použijeme teda takýto vzorec:
- v prípade Excelu vytvorte linkback tabuľku so vzorcom: EVALUATE DISTINCT(‚Kategórie'[ProductCategoryName])
- v prípade Power BI vytvorte vypočítanú tabuľku so vzorcom: Unikátne kategórie = DISTINCT(‚Kategórie'[ProductCategoryName])
Výsledok bude vyzerať takto:
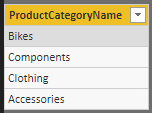
Výsledok je taký, aký sme očakávali – zoznam unikátnych názvov kategórii produktov. Vymeňte však teraz vo vzorci funkciu DISTINCT za funkciu VALUES, dostanete takýto výsledok:
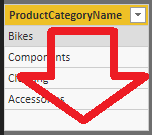
Všimnite si, že tentokrát funkcia VALUES vrátila o jednu prázdnu položku dlhší výsledok. A práve toto je ten rozdiel medzi funkciami DISTINCT a VALUES.
Kde sa však nabrala tá prázdna hodnota? Keď sa pozriete do tabuľky Kategórie, tak tam nie je žiadna prázdna hodnota v stĺpci ProductCategoryName:
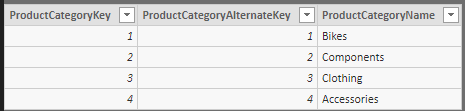
Funkcia VALUES však nejakú prázdnu hodnotu vracia. A nerobí to len tak zo srandy.
Dôvod je v tom, že na túto tabuľku sú prepojené ďalšie tabuľky v smere 1:N, a to: Podkategórie,Produkty a Objednávky. A v objednávkach je jedna objednávka, ktorá odkazuje na neplatný produkt:

Spôsob, ako na to dôjsť, nájdete napr. v tomto staršom článku.
Táto objednávka odkazuje na produkt č. 1001, ktorý neexistuje v tabuľke Produkty, na ktorú je prepojená cez tento stĺpec. A PowerPivot nepovoľuje neplatné odkazy medzi tabuľkami. Aby však PowerPivot vedel dať dohromady aj takéto dáta s neplatnými odkazmi, tak si dopomôže tým, že v každej tabuľke, ktorá je od tohto neplatného odkazu v smere N:1, si vyrobí umelý skrytý riadok s prázdnymi hodnotami vo všetkých stĺpcoch. Na tento umelý riadok potom namapuje všetky neplatné odkazy z pôvodnej tabuľky, ktorá na ňu odkazuje. A takýto umelý riadok sa potom zobrazuje aj v kontingenčke, resp. reporte, s hodnotou „(blank)“ alebo „(prázdne)“. Tento riadok sa však nezobrazuje v dátovom zobrazení PowerPivotu, a väčšinou ani nie je započítavaný do štatistiky počtu riadkov. A ignoruje ho aj väčšina analytických funkcií jazyka DAX.
Čiže v našom prípade si PowerPivot na tajnáša vytvorí v tabuľke Produkty jeden umelý riadok, na ktorý sa budú odkazovať riadky z Objednávok s neplatnými číslami produktov. A pokračuje potom v smere N:1 na ďalšie prepojené tabuľky, a vytvorí takýto umelý riadok aj v tabuľke Podkategórie, aj v tabuľke Kategórie. Keď potom zavoláte funkciu VALUES(‚Kategórie'[ProductCategoryName]), tak funkcia VALUES vráti aj tú umelú hodnotu BLANK. Funkcia DISTINCT však túto umelú hodnotu BLANK nevracia.
A toto je ten druhý rozdiel medzi funkciami DISTINCT a VALUES. Funkcia DISTINCT nevracia tú umelú hodnotu BLANK, a funkcia VALUES ju vracia. Neberte to však tak, že funkcia DISTINCT nevracia BLANK. Ak tam totižto tá hodnota BLANK je, a nebola umelo vyrobená PowerPivotom – čiže bola už v zdrojových dátach – tak funkcia DISTINCT takúto hodnotu BLANK vráti. Preto jediný rozdiel medzi týmito funkciami je v tom, že jedna z nich vracia umelo vyrobený BLANK (funkcia VALUES), a druhá ho nevracia (funkcia DISTINCT). Pôvodné hodnoty zo stĺpcov však vracajú obe, bez ohľadu na to, či je to hodnota BLANK alebo nie.
Toto sú teda rozdiely medzi funkciami DISTINCT a VALUES. Na prvý pohľad nepodstatný rozdiel, ale pri hľadaní problému vo vzorci pri pokročilej analytike to príde vhod. A vždy je lepšie to vedieť dopredu, ako to potom niekoľko hodín hľadať 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.