Na internete sa šíri jeden z mýtov, že vypočítané stĺpce sú rýchlejšie ako merítka. Najmä preto, že vo vypočítaných stĺpcoch sú už predpočítané hodnoty, a merítka sa musia po každom kliknutí v reporte prepočítať. Pravda je však samozrejme zasa niekde inde. A závisí to od viacerých faktorov.
Hlavný rozdiel medzi vypočítanými stĺpcami a merítkami je v tom, že vypočítané stĺpce sú predpočítané dopredu. Až na pár výnimiek zaberajú miesto v pamäti aj na disku rovnako ako aj „obyčajné“ stĺpce. Naproti tomu merítka sú iba vzorce, ktoré si len tak sedia v dátovom modeli, a nikdy sa nepredpočítavajú dopredu. A okrem samotného vzorca v pamäti nič nezaberajú. Musia sa však vypočítať odznova vždy, keď sa použijú v reporte, alebo keď niečo zmeníte v reporte. Rozdielov je ešte viac, ale tie teraz nie sú podstatné. Podstatné je teraz to, že keď je raz niečo predpočítané, tak by to malo byť predsa rýchlejšie ako niečo, čo predpočítané nie je, že?
Toto možno platí v iných systémoch, ale v PowerPivote tomu tak nie je. A v niektorých prípadoch platí presný opak. A hlavným dôvodom je tentokrát opäť to, že PowerPivot – a jeho všetky verzie ako napr. Power BI, SSAS Tabular či Azure Analysis Services – sú stĺpcovými databázami. Kde každý stĺpec je v pamäti uložený osobitne, a vo väčšine prípadov ešte aj skomprimovaný. Zjednodušene som už písal o tom v tomto článku. Silno odporúčam si ho prečítať, ak ešte nepoznáte internú organizáciu dátového modelu, pretože bez toho tomu ďalej nepochopíte.
Spravme si úplne jednoduchý príklad. Opäť využijeme náš vzorový súbor PowerPivotu, resp. Power BI.
V dátovom modeli máme v tabuľke Objednávky stĺpec „Cena objednávky“, ktorý teraz prehlásime za cenu bez DPH. Teraz by sme chceli vypočítať cenu s DPH, a chceli by sme porovnať, či je to rýchlejšie zobrazené v reporte, keď je to vypočítaný stĺpec, alebo merítko.
Spravíme si teda takýto vypočítaný stĺpec s názvom „Cena bez DPH“, v tabuľke Objednávky:
Cena s DPH = ‚Objednávky'[Cena objednávky] * 1,2
…a potom takéto merítko:
Cena s DPH meritko := SUMX(‚Objednávky‘; ‚Objednávky'[Cena objednávky] * 1,2)
Ktorá z týchto dvoch variánt bude rýchlejšia? Tá predpočítaná vo vypočítanom stĺpci, alebo tá nepredpočítaná s merítkom?
Všetky nasledujúce testy sú spúšťané s vymazanou cache, aby výsledky boli objektívne porovnateľné.
Dáme si v DAX Studiu spustiť tieto 2 dotazy:
EVALUATE
ROW(„test“, SUM(‚Objednávky'[Cena s DPH]))
EVALUATE
ROW(„test“, [Cena s DPH meritko])
Prvý z nich počíta sumu nad tým vypočítaným stĺpcom, a druhý počíta tú istú sumu cez merítko. V prvom prípade dotaz zbehne za 2 ms, v druhom za 3 ms. V tomto prípade teda bolo merítko o 50% pomalšie.
Teraz však prepíšeme vzorec merítka na tento, pretože z logického hľadiska je to to isté:
Cena s DPH meritko := SUM([Cena objednávky]) * 1,2
Keď spustíme znova hore uvedený dotaz na toto merítko, tak v tomto prípade zbehne už iba za 2 ms. Pretože sme eliminovali násobenie každého riadku konštantou 1,2, a namiesto toho sme to spravili naraz na konci.
A na tomto prípade vidíte, že vypočítaný stĺpec aj merítko môžu byť rovnako rýchle. S tým rozdielom, že v prípade merítka ste práve ušetrili drahocennú pamäť. A mierne urýchlili aktualizáciu dát v dátovom modeli, ktorá teraz pôjde o niečo rýchlejšie, keď nemusí počítať ten vypočítaný stĺpec.
Ak by sme išli na to z inej strany, tak vypočítané stĺpce môžu byť aj pomalšie ako merítka. Pretože v prípade použitia obyčajných aj vypočítaných stĺpcov rýchlosť výpočtov závisí od veľkosti stĺpca v pamäti. A keď viete napísať merítko, ktoré berie dáta z nejakého iného menšieho stĺpca, tak táto varianta môže byť oveľa rýchlejšia ako vypočítaný stĺpec.
Spravme si teraz ďalší jednoduchý príklad, kde budeme spočítavať počet riadkov objednávok. V prípade využitia stĺpca si najprv potrebujeme vytvoriť stĺpec s jedinečným identifikátorom riadku, a teda vytvoríme takýto vypočítaný stĺpec, kde spojíme dokopy číslo objednávky, a číslo položky objednávky:
ID riadku objednávky = ‚Objednávky'[SalesOrderNumber] & „/“ & [SalesOrderLineNumber]
Nad týmto stĺpcom potom už iba zavoláme funkciu COUNT, a máme spočítaný počet riadkov. Môžeme to však rovno spraviť aj bez toho, s takýmto merítkom:
Počet riadkov objednávok merítko := COUNTROWS(‚Objednávky‘)
A ktorá z týchto variánt bude rýchlejšia? Opäť spustíme dotazy v DAX Studiu – najprv pre ten vypočítaný stĺpec, a potom pre merítko:
EVALUATE
ROW(„test“, COUNT(‚Objednávky'[ID riadku objednávky]))
EVALUATE
ROW(„test“, [Počet riadkov objednávok merítko])
V tomto prípade výpočet zbehne v prvom prípade za 3 ms, a v druhom prípade za 1 ms. Čiže v tomto prípade je merítko 3x rýchlejšie. A je to spôsobené 2 vecami:
- stĺpec „ID riadku objednávky“ zaberá v pamäti podľa Power BI Analyzera 4 141 kB:
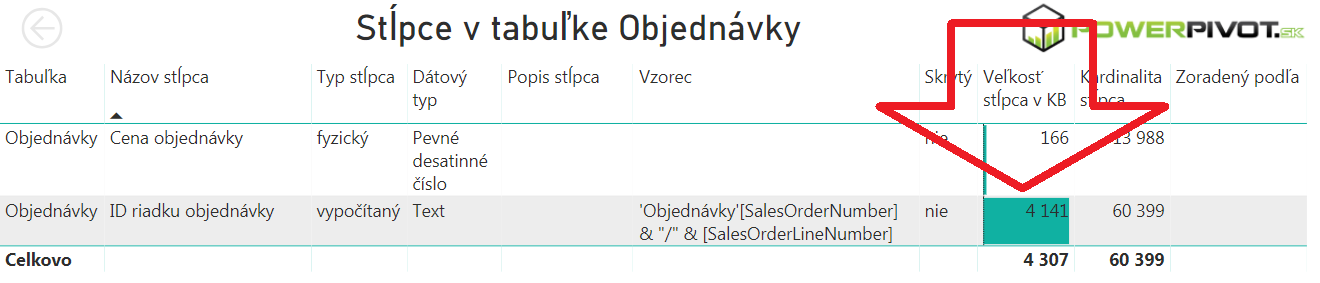
Pritom celá tabuľka zaberá v pamäti okolo 7 MB, a väčšina z toho je tento stĺpec, a stĺpec SalesOrderNumber. Ostatné stĺpce sú oveľa menšie – rádovo iba zopár až zopár desiatok kB – a teda výpočet cez ne by išiel oveľa rýchlejšie. - merítko „Počet riadkov objednávok merítko“ nemuselo čítať žiaden stĺpec, ale využilo interné štruktúry databázy, a prečítalo si to rovno odtiaľ.
Ak by sme štatistiku rozbili podľa rokov, napr. týmito dotazmi:
EVALUATE
ADDCOLUMNS(VALUES(‚Čas'[CalendarYear]), „Počet“, CALCULATE(COUNT(‚Objednávky'[ID riadku objednávky])))
EVALUATE
ADDCOLUMNS(VALUES(‚Čas'[CalendarYear]), „Počet“, [Počet riadkov objednávok merítko])
…tak výsledky sú 3-4 ms v prípade vypočítaného stĺpca, a 3 ms v prípade merítka. Čo je v podstate rovnaký čas, občas v mierny neprospech vypočítaného stĺpca (asi keď potrebuje viac porozmýšľať). Na veľkých dátach sa to samozrejme prejaví viac. Ale v tomto prípade je to viac-menej zajedno. Len v prípade merítka sme nemuseli vytvárať vypočítaný stĺpec, a zbytočne dávať nabobtnať dátový model v pamäti na dvojnásobok.
Vypočítané stĺpce však nie sú nutne zlé. Majú svoje použitia, ktoré sa dajú spraviť iba cez ne. Len ich netreba vytvárať v slepej viere, že ak je to predpočítané, tak to musí byť rýchlejšie. Ako vidíte, nemusí. Môže to byť aj rýchlejšie, aj pomalšie, aj rovnako rýchle. Len si to treba vedieť najprv predstaviť, a potom aj otestovať. A potom to netlačiť do dátového modelu, keď to tam nutne nemusí byť. Pretože do pamäte môžete natlačiť len obmedzené množstvo dát. A o to markantnejšie to je, keď ten model má miliardy riadkov, a nasadíte ho na server do SSAS Tabularu, prípade na cloudové Azure Analysis Services. Tam zrazu takéto drobné rozdiely poskočia z milisekúnd na minúty, alebo rovno timeouty. Alebo na nedostatok pamäte pri spracovaní či aktualizácii dát v dátovom modeli.
Preto nevytvárajte nutne iba vypočítané stĺpce, a skúste svoj výpočet spraviť aj merítkami. Otestujte rýchlosť a potom sa rozhodnite. A následne odstráňte z modelu tie vypočítané stĺpce, kde daný výpočet viete spraviť aj merítkom, v rovnakom, porovnateľnom, alebo dokonca rýchlejšom čase. Tak ušetríte drahocennú pamäť, a veľakrát aj urýchlite a zmenšíte dátový model. Len si nezabudnite pred finálnym otestovaním vymazať cache 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.