V marci nám do jazyka DAX po relatívne krátkom čase pribudli nové funkcie. Niektoré z nich sú iba skratkovité funkcie, iné mierne uľahčia niektoré analýzy. Preto sa na ne pozrieme teraz bližšie.
Všetky tieto funkcie boli pridané do najnovšieho PowerPivotu. Sú preto dostupné zatiaľ iba v Power BI, a v Azure Analysis Services. Ostatné verzie PowerPivotu snáď budú niekedy nasledovať tiež.
Vo všetkých ukážkach nižšie je použitý náš vzorový súbor Power BI.
Nová syntax funkcie ALL
Ako prvá bola pridaná nová syntax funkcie ALL. O nej som písal podrobne už v predchádzajúcom článku.
Nová syntax funkcie LOOKUPVALUE
Funkcia LOOKUPVALUE v jazyku DAX je ekvivalentom excelovského presného VLOOKUP-u. Do tejto funkcie bol pridaný ďalší parameter, ktorým viete určiť, či táto funkcia pri nájdení viacnásobnej zhody vyhodí chybu, alebo nie. Štandardne sa to doteraz správalo tak, že ak našla zhodu, a v zhodných riadkoch vo výslednom stĺpci boli viaceré jedinečné hodnoty, tak spadla na chybe, a bolo potrebné ju zabaliť napr. do funkcie IFERROR. Po novom je syntax tejto funkcie doplnená o nepovinný parameter alteratívnyVýsledok na konci, a je takáto:
LOOKUPVALUE(výslednýStĺpec; hľadanýStĺpec; hľadanáHodnota [; hľadanýStĺpec2; hľadanáHodnota2; … [; alternatívnyVýsledok]])
Táto funkcia funguje rovnako ako fungovala doteraz funkcia LOOKUPVALUE, resp. ako funguje presný excelovský VLOOKUP. Keď funkcia nenašla žiadnu zhodu, tak vrátila ako výsledok hodnotu BLANK. Odteraz je tam však ten parameter alternatívnyVýsledok. A keď táto funkcia nenájde zhodu, alebo nájde viacero zhôd s viac ako jednou jedinečnou hodnotou vo výslednom stĺpci, tak vráti ako výsledok hodnotu parametra alternatívnyVýsledok.
Čiže napr. ak ste predtým mali toto merítko, ktoré hľadalo ID regiónu pre krajinu s názvom „United States“:
ID regionu := LOOKUPVALUE(‚Regióny'[SalesTerritoryKey]; ‚Regióny'[Krajina]; „United States“)
…a dali ste ho zobraziť, tak ste dostali takéto chybové hlásenie:
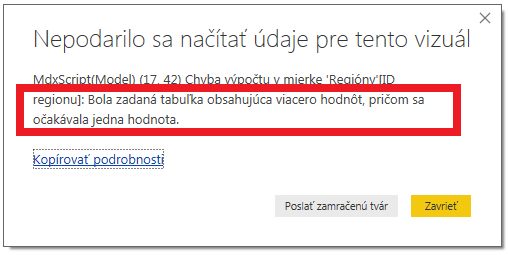
Je to preto, pretože v našom dátovom modeli máme až 5 regiónov pre krajinu „United States“:

Po novom to ide ošetriť napr. takto, že vrátime posledné ID regiónu zo zhodných riadkov:
ID regionu := LOOKUPVALUE(‚Regióny'[SalesTerritoryKey]; ‚Regióny'[Krajina]; „United States“; MAX(‚Regióny'[SalesTerritoryKey]))
Ako alternatívny výsledok totižto viete zadať ľubovoľný daxový vzorec. A čo nie je uvedené v dokumentácii, ale zjavne funguje, je to, že tento vzorec sa vyhodnotí v kontexte iba tých zhodných riadkov. A vďaka tomu ten MAX nevrátil hodnotu 11, ale 5 – najväčšie ID pre hľadaný región pre krajinu „United States“:

Nové analytické funkcie
Jednou z nových funkcií je funkcia DistinctCountNoBlank. Resp., podľa názvových konvencií jazyka DAX, je to správne DISTINCTCOUNTNOBLANK. Jej syntax je nasledovná:
DISTINCTCOUNTNOBLANK(stĺpec)
Táto funkcia spočíta počet jedinečných hodnôt v zadanom stĺpci, pričom odignoruje prázdne BLANK hodnoty. Čiže funguje rovnako ako funkcia DISTINCTCOUNT, ale neberie do úvahy prázdne hodnoty.
Keď ju zavoláme napr. nad stĺpcom ListPrice v tabuľke Produkty, aby sme zistili počet jedinečných cien zo všetkých produktov, tak po starom sme mohli zavolať iba DISTINCTCOUNT:
Počet unikátnych cien := DISTINCTCOUNT(Produkty[ListPrice])
…a vráti to takýto výsledok:
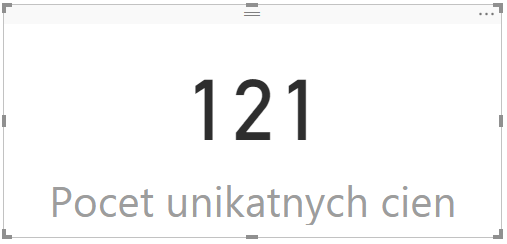
To však započíta aj prázdnu cenu ako 1 položku. Keď ju nechceme, tak namiesto toho zavoláme DISTINCTCOUNTNOBLANK:
Počet unikátnych cien := DISTINCTCOUNTNOBLANK(Produkty[ListPrice])
…čo po novom vráti výsledok o 1 nižší, lebo tam už nie je započítaná aj tá prázdna cena:
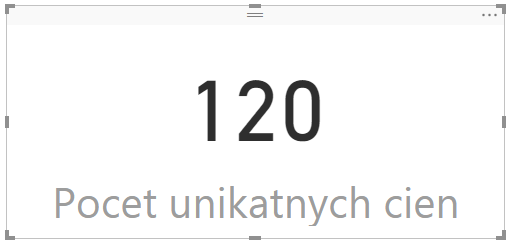
Čo tiež príde vhod. Ak by ste to potrebovali nasimulovať v staršej verzii DAX-u, tak to pôjde napr. takto:
Počet unikátnych cien := COUNTROWS(FILTER(DISTINCT(Produkty[ListPrice]); [ListPrice] <> BLANK()))
Nové skratkovité funkcie
Posledné 2 nové funkcie sú funkcie pre prácu s textom. Konkrétne funkcie ContainsString a ContainsStringExact. Na prvý pohľad sú to iba skratkovité funkcie k funciám FIND a SEARCH, ale je tam jedna drobnosť, takže sa na to pozrieme trochu lepšie.
Čo sa týka týchto dvoch funkcií, tak obidve funkcie majú rovnakú syntax:
CONTAINSSTRING(prehľadávanýText; hľadanýText)
CONTAINSSTRINGEXACT(prehľadávanýText; hľadanýText)
Obe funkcie vrátia pravdu (hodnotu TRUE), ak sa hľadanýText nachádza v prehľadávanomTexte. A nepravdu v opačnom prípade. Obe funkcie podporujú aj zadávanie masky v hľadanomTexte (hviezdička – * – pre ľubovoľnú postupnosť znakov, a otáznik – ? – pre výskyt ľubovoľného 1 znaku). Rozdiel medzi nimi je ten, že tá prvá nerozlišuje medzi veľkými a malými písmenami (je case-insensitive), a tá druhá rozlišuje (je case sensitive).
Na prvý pohľad sú to teda iba skratkovité funkcie k funkciám FIND a SEARCH. Sú tam však ešte 2 rozdiely:
- funkcia FIND nepodporuje zadávanie masky v hľadanomTexte. To podporuje iba funkcia SEARCH,
- ak funkcia FIND alebo SEARCH nenájde hľadanýText v prehľadávanomTexte, tak vráti chybu. Funkcie CONTAINSSTRING a CONTAINSSTRINGEXACT vrátia nepravdu (hodnotu FALSE).
Príklady použitia sú zjavné asi aj z tohto popisu, takže dáme si iba jeden. Nasledujúce merítko otestuje, či sa v texte „Toto je pekný deň“ nachádza slovo, ktoré začína na „p“ a končí na „ý“:
Nachádza sa tam := CONTAINSSTRING(„Toto je pekný deň“; „p*ý“)
…čo vráti vo výsledku pravdu:

A ako to nasimulovať v staršom DAX-e?
Funkciu CONTAINSSTRING napíšete aj takto:
= IFERROR(SEARCH(„p*ý“; „Toto je pekný deň“) > 0; FALSE())
…a funkciu CONTAINSSTRINGEXACT napíšete po starom napríklad aj takto, ak nepotrebujete zadávať masky v hľadanom texte:
= IFERROR(FIND(„pekný“; „Toto je pekný deň“) > 0; FALSE())
A ak chcete mať aj podporu masiek v hľadanom texte, tak si to skúste napísať sami. Neviem presne, či to pôjde napísať cez staršie daxové funkcie, ale ak by sa vám to podarilo, tak to prípadne napíšte sem do komentárov. Mne to už v túto nočnú hodinu nemyslí 🙂
Na záver
Toto je teda prehľad aktuálne najnovších funkcií v jazyku DAX. Pevne verím, že sa raz objavia aj v ostatných verziách PowerPivotu. Dovtedy je potrebné vystačiť si s náhradnými riešeniami. Napríklad s tými uvedenými v tomto článku. Čo väčšinou nie je problém. Aspoň si trochu viac precvičíte DAX 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.