Vypočítané stĺpce a merítka sú fajn, ak potrebujete vypočítať ľubovoľné ukazovatele. Niekedy si však predtým ešte potrebujete dopomôcť výpočtami v rámci jednej tabuľky, aby vzorce pre Vaše ukazovatele neboli až tak veľmi komplikované. V tomto článku si ukážeme, ako vieme spraviť vypočítané stĺpce, ktoré budú sumovať hodnoty za celú skupinu riadkov v rámci jednej tabuľky, a prípadne aj rozpočítavať takúto sumu rovnomerne medzi všetky riadky v skupine. Tejto technike sa hovorí Výpočty za skupinu v rámci jednej tabuľky.
Pre účely tohto článku použijeme tabuľku s názvom Transakcie z jedného z predchádzajúcich článkov, ktorá obsahuje tabuľku s transakciami a tovarom:
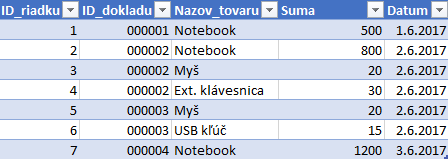
Tu by sme chceli doplniť 2 nové stĺpce:
- Sumu celého nákupu pre každý doklad
- Priemernú cenu položky v danom doklade
Sumu celého nákupu za daný doklad vypočítame pomocou funkcií SUMX, FILTER a EARLIER. Funkciou FILTER si vyfiltrujeme riadky, ktoré pôjdeme sumovať. Funkciu EARLIER využijeme na to, aby sme vyfiltrovali pre aktuálne počítaný riadok iba tie riadky, ktoré majú rovnaký identifikátor dokladu ako tento aktuálne počítaný riadok. Funkcia EARLIER totižto vracia hodnotu zo zadaného stĺpca v aktuálne počítanom riadku, a je ako stvorená pre takéto výpočty, resp. pre všetky výpočty, kde sa potrebujete odkazovať na aktuálne počítaný riadok. Nepýtajte sa ma, prečo Microsoft pomenoval túto funkciu EARLIER a nie napr. CURRENTROW alebo CURRENTVALUE, čo by bolo oveľa výstižnejšie. V dokumentácii DAXu je uvedené len to, že táto funkcia slúži na rekurzívne výpočty, a vracia hodnotu z predchádzajúcej iterácie. V realite sa ale používa skôr na nerekurzívne výpočty, a konkrétne na ten účel, ktorý si práve ukazujeme 🙂
Vytvoríme teda nový vypočítaný stĺpec v tejto tabuľke, nazveme ho „Suma za cely doklad“, a vzorec preňho bude nasledovný:
=SUMX(FILTER(Transakcie; [ID_dokladu] = EARLIER([ID_dokladu])); [Suma])
Alebo, tu je to pekne naformátované:
![]()
Tento vzorec sa, ako každý iný vzorec pre vypočítané stĺpce, spustí osobitne pre každú bunku tohto vypočítaného stĺpca. Keďže chceme zosumovať riadky, ktoré majú rovnaké číslo dokladu, tak si najprv funkciou EARLIER zistíme, aká hodnota sa nachádza v stĺpci ID_dokladu na aktuálne počítanom riadku. Potom si pomocou funkcie FILTER vyfiltrujeme z celej tabuľky Transakcie iba tie riadky, ktoré majú rovnaké číslo dokladu ako aktuálne počítaný riadok. Nakoniec v týchto riadkoch zosumujeme stĺpec Suma pomocou funkcie SUMX. Výsledok bude vyzerať takto:
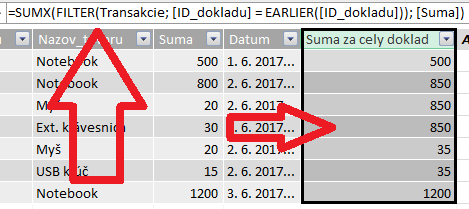
Toto je teda základ postupu pre výpočty za skupinu v rámci jednej tabuľky.
Podobným spôsobom zistíme aj druhé zadanie zo začiatku tohto článku – priemernú cenu položky v danom doklade. Buď nahraďte funkciu SUMX funkciou AVERAGEX:
=AVERAGEX(FILTER(Transakcie; [ID_dokladu] = EARLIER([ID_dokladu])); [Suma])
…alebo si najprv vypočítajte pre každý riadok počet položiek na príslušnom doklade a potom hore uvedenú celkovú sumu predeľte počtom riadkov v danom doklade. Počet riadkov vypočítame pre jednoduchosť do vypočítaného stĺpca s názvom „Pocet riadkov v celom doklade“ týmto vzorcom:
=COUNTROWS(FILTER(Transakcie; [ID_dokladu] = EARLIER([ID_dokladu])))
Potom už len vytvoríme ďalší vypočítaný stĺpec s názvom „Priemerná cena polozky v doklade“, kde predelíme celkovú sumu za doklad počtom položiek v doklade, a kvôli krajšiemu výsledku ju zaokrúhlime na celé číslo, pomocou tohto vzorca:
=ROUND([Suma za cely doklad] / [Pocet riadkov v celom doklade]; 0)
Výsledok bude vyzerať takto:
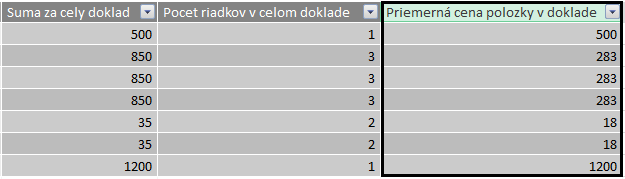
Podobným spôsobom sa výpočty za skupinu v rámci jednej tabuľky používajú na počítanie ďalších a ďalších ukazovateľov, ktoré závisia od ostatných, resp. okolitých riadkov, a prípadne si nimi pripravovať medzikroky k výpočtu zložitejších ukazovateľov, aby neboli až také zložité. A aby ste sa v tom hlavne aj Vy sami vyznali, ak to pol roka nebudete vidieť. Pretože nič neoceníte viac, ako superkomplikovaný vzorec, ktorým zabijete pol dňa, a v ktorom sa neskôr nevyzná ani divá sviňa 🙂 V tom je práve tá mágia toho, ako správne písať DAX-ové vzorce – aby výsledok bol nielen jednoducho napísaný, ale aby sa dal aj jednoducho upravovať a rozširovať. A pomocou tipov na tomto blogu a na našich školeniach sa k tomu viete časom dopracovať 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.
Možno by bolo zaujímavé porovnať toto riešenie s vytvorením novej tabuľky s „hlavičkami“ k týmto dokladom. Lebo dosť závisí od dôvodov, ktoré nás k týmto výpočtom vedú, lebo takýto typ výpočtov je väčšinou iba medzikrok k ďalším štatistikám a konečným vizualizáciám.
Samozrejme 🙂 V takomto prípade to ide spraviť ešte jednoduchšie, cez SUMX a RELATEDTABLE 🙂
DD, v čem že je rozdíl mezi tímhle: [ID_dokladu] = earlier ([ID_dokladu]) a tímhle: [ID_dokladu] ? Vždyť to přece vrací stejnou hodnotu.
Dobrý deň,
Rozdiel je v tom, že bez toho EARLIER by Vám to spočítalo všetky riadky v tabuľke. Funkcia EARLIER sa používa na odkazovanie sa do nadradenej iterácie. V tomto prípade to znamená to, že ju používame na to, aby sme zistili hodnotu na aktuálne počítanom riadku. A spolu s funkciou FILTER vyfiltrovali a pomocou SUMX zosumovali len také riadky, ktoré majú rovnaké číslo dokladu ako je na aktuálne počítanom riadku.
No jo vlastně. Bylo už na mě trochu pozdě 🙂 Každopádně to je perfektní jednoduchá funkce. Díky.