V niektorých prípadoch potrebujete vo svojich reportoch zobrazovať iné, prípadne žiadne čísla, ak ste v riadku s celkovým súčtom. Na to potrebujete najprv vedieť, ako detekovať túto úroveň celkového súčtu, resp. grand totalu, v jazyku DAX. Následná úprava príslušného riadku s celkovým súčtom je už potom hračka. Poďme sa teda pozrieť na to.
Riešenie si znova ukážeme na našom vzorovom súbore PowerPivotu, resp. Power BI
Povedzme, že máme takúto tabuľku v reporte, resp. kontingenčku:
- na riadkoch sú roky – stĺpec CalendarYear z tabuľky Čas,
- v stĺpcoch sú 2 merítka – Obrat a Obrat pred rokom.
Výsledná kontingenčka vyzerá takto, pričom si všimnite hodnotu v celkovom súčte pre merítko Obrat pred rokom:
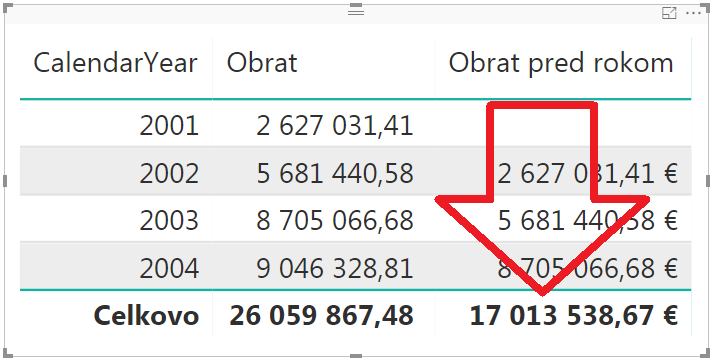
Je tam vypočítaná nejaká hodnota, ale má drobný logický problém – v celkovom súčte totižto nemá zmysel zobrazovať nič, lebo na tom riadku nie je žiaden rok. A teda nemá zmysel tam ani nič počítať. Preto tam ani my nechceme zobraziť nič. A na to budeme musieť najprv spraviť detekciu grand totalu, resp. to, že sme na úrovni celkového súčtu.
Keby ste mali v reporte len takúto tabuľku, kde by ste nič nemenili, tak by Vám stačilo takéto jednoduché merítko:
Je to GT := NOT(ISFILTERED(‚Čas'[CalendarYear]))
Po pridaní do reportu by sa vyhodnotilo takto:
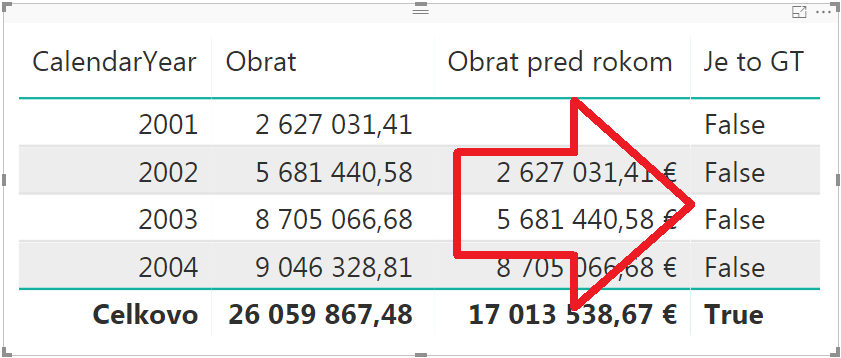
Čiže na prvý pohľad by to stačilo. Ale keby ste teraz v reporte vymenili stĺpec s rokom za iný, napr. za stĺpec Krajina z tabuľky Regióny, tak by to už vyzeralo takto:
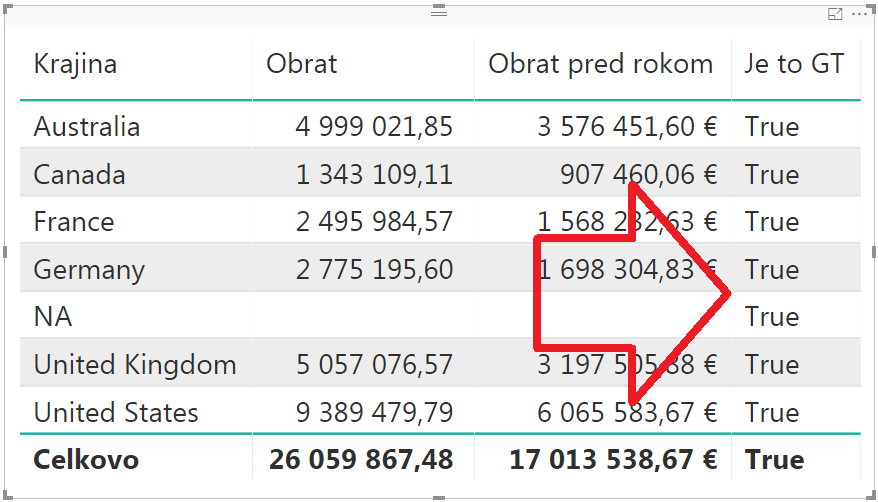
A to nie je zrovna správny výsledok. Takže si to budeme musieť spraviť univerzálnejšie.
Riešením je spraviť na prvý pohľad trochu dlhší vzorec, ale zvyčajne ho robíte v dátovom modeli len raz. Takže až také zlé to nebude 🙂 Problém je v tom, že kontext výpočtu pre celkový súčet je definovaný prázdnou množinou daxových filtrov. Čiže na úrovni celkového súčtu neexistujú žiadne daxové filtre. A to potrebujeme zapísať v jazyku DAX. Lenže na to by sme museli napísať také merítko, ktoré otestuje, že kontext výpočtu nie je filtrovaný žiadnym stĺpcom zo žiadnej tabuľky z celého dátového modelu. A ak sa nechceme upísať k smrti, a napísať X-krát podmienku s funkciou ISFILTERED pre každý jeden boží stĺpec v dátovom modeli (a aj pre tie, ktoré neskôr pridáme), tak namiesto funkcie ISFILTERED budeme musieť použiť funkciu ISCROSSFILTERED. Pretože si chceme skrátiť zápis celej tej obludy na minimum.
Funkcia ISCROSSFILTERED(stĺpec) vracia hodnotu true, keď je kontext merítka filtrovaný zadaným stĺpcom priamo alebo nepriamo. A keď do tejto funkcie dosadíte do parametra primárny kľúč tabuľky (resp. ten prepájací stĺpec, cez ktorý máte túto tabuľku prepojenú na hlavnú tabuľku), tak tým zabezpečíte to, že táto funkcia vráti vždy true, keď je aktuálny kontext merítka filtrovaný ľubovoľným stĺpcom z tejto tabuľky.
A túto funkciu ISCROSSFILTERED musíme takto zavolať postupne pre všetky tabuľky v dátovom modeli. A ak všetky vrátia hodnotu false, tak to znamená, že kontext výpočtu merítka nie je filtrovaný ničím, a teda že sme na úrovni grand totalu, resp. celkového súčtu. Čiže namiesto napísania ISFILTERED pre každý jeden stĺpec v dátovom modeli, stačí napísať funkciu ISCROSSFILTERED iba raz pre každú tabuľku. Čo sa už dá prežiť.
Pre náš vzorový súbor PowerPivotu, resp. Power BI, bude vyzerať výsledné merítko takto:
Je to GT := NOT(ISCROSSFILTERED(‚Čas'[DateKey]) || ISCROSSFILTERED(‚Kategórie'[ProductCategoryKey]) || ISCROSSFILTERED(Meny[CurrencyKey]) || ISCROSSFILTERED(‚Podkategórie'[ProductSubcategoryKey]) || ISCROSSFILTERED(Produkty[ProductKey]) || ISCROSSFILTERED(‚Regióny'[SalesTerritoryKey]))
V skratke – je tam funkcia NOT, do ktorej je zabalený zvyšok vzorca. A v ňom testujeme, či je kontext výpočtu filtrovaný ľubovoľným stĺpcom z tabuľky Čas, alebo z tabuľky Kategórie, atď., až takto prejdeme cez všetky tabuľky. Celé to po znegovaní funkciou NOT znamená, že ak kontext výpočtu nie je filtrovaný ničím, tak ten vzorec vráti hodnotu true.
V tomto vzorci som neuviedol ešte centrálnu tabuľku Objednávky. Je to preto, že v tomto prípade je to zbytočné, lebo táto tabuľka sa nepoužíva na filtrovanie dát – na to sú určené okolité číselníky. Keby ste ale potrebovali otestovať aj túto tabuľku, lebo ju používate na filtrovanie alebo pre slicery, alebo je to proste jediná tabuľka v celom vašom dátovom modeli, tak aj tu je riešenie. Do funkcie ISCROSSFILTERED dajte primárny kľúč z tejto tabuľky. Je to stĺpec, ktorý obsahuje unikátny identifikátor riadka v tejto tabuľke. A keby ste ho tam nemali, tak si ho vyrobte – v Power Query to ide spraviť na pár kliknutí myšou.
Výsledná kontingenčka s takýmto merítkom už bude vyzerať takto, pre ľubovoľnú kombináciu stĺpcov:
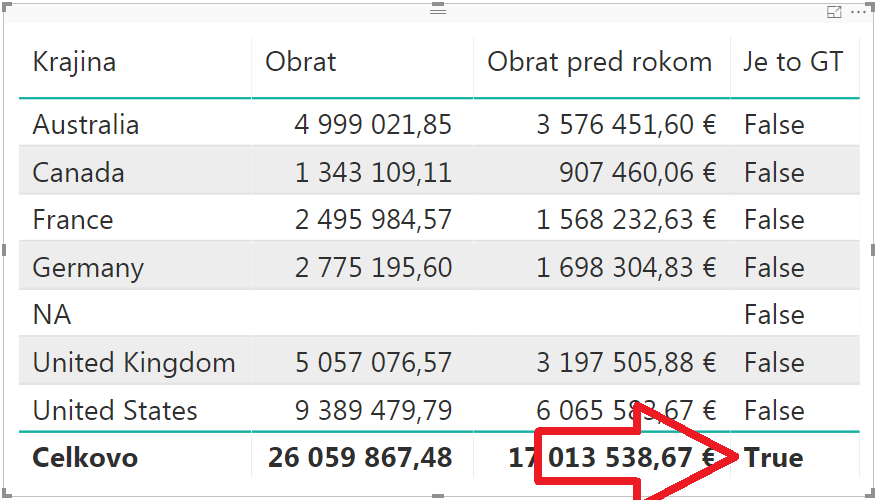
A takto jednoducho si viete detekovať grand total. Nie je to síce krátky vzorec, ale je relatívne jednoduchý. A stačí ho mať ako merítko v modeli iba raz. Takže ak sa vám zdá ťažký, tak si k nemu na chvíľu sadnite, a skúste ho pochopiť. A keby to náhodou aj bolo ťažké, tak si zapamätajte, že stačí nasypať za sebou funkcie ISCROSSFILTERED postupne pre každú tabuľku v dátovom modeli, a celé to znegovať cez NOT. A detekcia grand totalu je na svete 🙂
Na koniec stačí už iba vytvoriť takéto merítko, ktoré na úrovni celkového súčtu, resp. grand totalu, nebude zobrazovať nič, pre merítko Obrat pred rokom:
Obrat pred rokom opravený := IF([Je to GT]; BLANK(); [Obrat pred rokom])
A po dosadení do reportu namiesto pôvodného merítka Obrat pred rokom, to bude vyzerať takto:
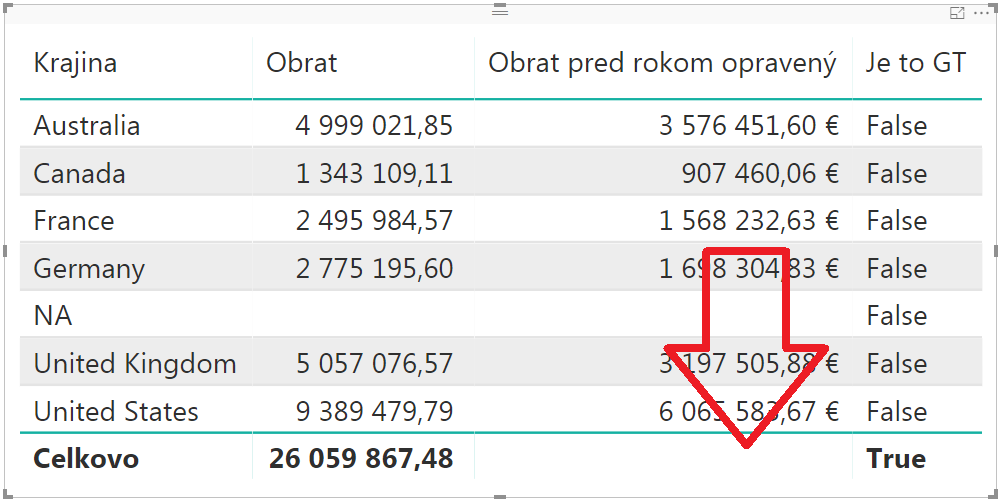
Následne si už len vyhodíme merítko „Je to GT“ z reportu preč, a máme takúto krásnu chrumkavučkú kontingenčku, po ktorej naše srdce plesalo už od začiatku:
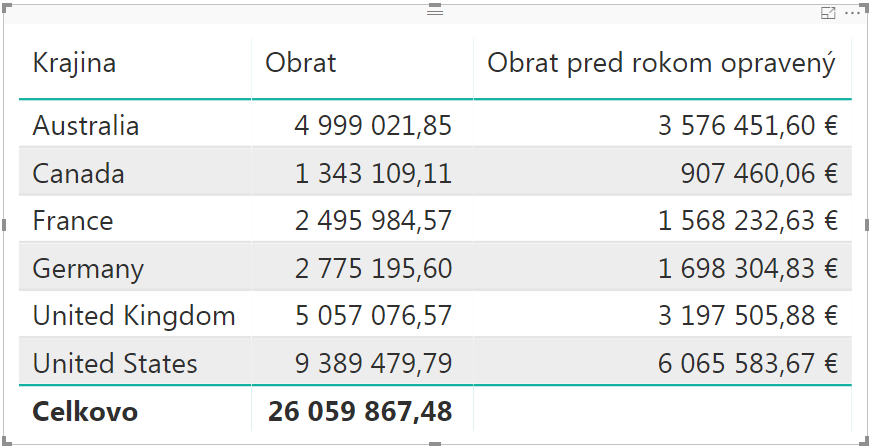
Pre krajiny tie čísla v poslednom stĺpci síce nemajú zmysel, ale ak znova nahradíte krajiny rokmi, tak to už bude správne:
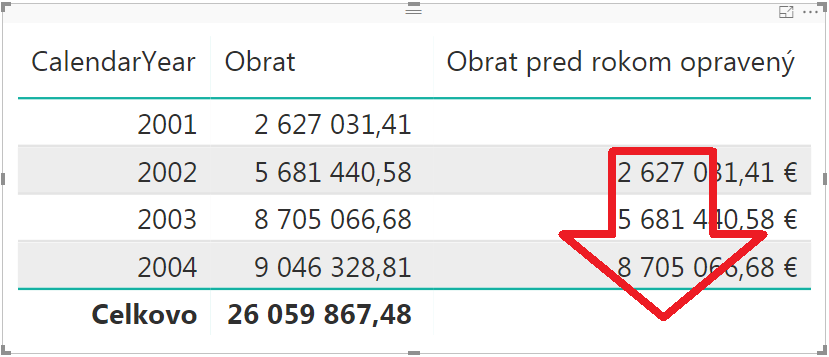
Samozrejme si tam potom ešte premenujte ten posledný stĺpec, resp. merítko, ale to už zvládnete sami 🙂
Takže takto si viete upraviť, či sa niečo vôbec zobrazí v riadku s celkovým súčtom, prípadne aby sa tam zobrazilo presne to, čo chcete. Miernou úpravou tejto techniky to viete použiť aj na jednotlivé úrovne medzisúčtov. A to vám už nechám za domácu úlohu 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.