Technológia PowerPivotu je dnes integrovaná nielen v Exceli, ale aj v Power BI, SSAS Tabulare, Azure Analysis Services, či ako columnstore indexy v SQL Serveri. A až na menšie rozdiely funguje všade takmer rovnako. Po vytvorení prvých dátových modelov však prichádza mierne vytriezvenie, keď sa pokusmi o analýzu väčších a väčších dát, tieto dáta už nezmestia do pamäte, alebo narazíte na limity technológie. Napr. pri Power BI v cloude. Vtedy musíte dátový model jednoducho zmenšiť, inak ho nemôžete používať. A my si ukážeme, ako to ide aj inak, ako len odfiltrovaním dát, či ich zoskupením. Čiže bez straty informácií v dátovom modeli.
PowerPivot je stĺpcová databáza, kde každý stĺpec je komprimovaný samostatne. Jej princípy som už vysvetlil v staršom článku. Niektoré stĺpce sú však komprimované viac, niektoré menej, a niektoré vôbec. A sú stĺpce, ktoré zaberajú v pamäti aj viac miesta, ako keby ste ich tam uložili nekomprimované. Ako si však s takýmito stĺpcami rady? A ako vôbec identifikovať, ktoré stĺpce zaberajú najviac miesta v pamäti?
Ako zistiť veľkosť stĺpcov
Veľkosť stĺpcov zistíte najrýchlejšie tak, že napojíte na svoj dátový model nástroj Power BI Analyzer. Viac o ňom, vrátane odkazu na stiahnutie a návod na použitie, nájdete v tomto článku. Takže tu to už nebudeme popisovať znova.
V našom prípade použijeme náš vzorový súbor Power BI. Tento súbor otvoríme v Power BI Desktope, a necháme voči nemu spustiť Power BI Analyzer. Keď to za pár sekúnd zbehne, tak sa zobrazí výsledný report. Tam prejdite na záložku „Tabuľky“, kde nájdete zoznam všetkých tabuliek v dátovom modeli. Tam hneď uvidíte, že najväčšou tabuľkou v dátovom modeli je tabuľka Objednávky, ktorá zaberá 2,6 MB:
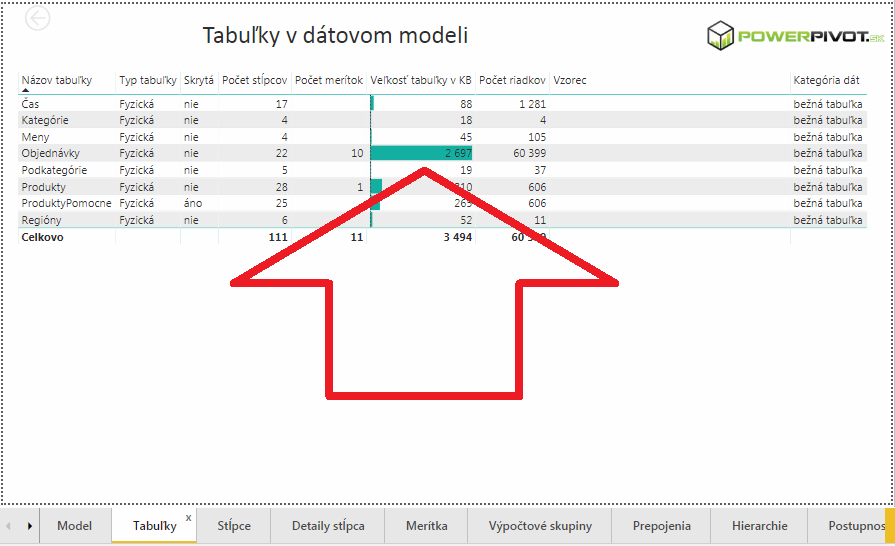
Potom si dajte zobraziť informácie o stĺpcoch v tejto tabuľke. Kliknite pravým tlačítkom myši na názov tej tabuľky, a potom kliknite na „Podrobná analýza“ => „Stĺpce“:
Zobrazí sa základný prehľad stĺpcov v tabuľke, zoradený od najväčšieho po najmenší stĺpec. Tam hneď uvidíte, že v tejto tabuľke suverénne najviac miesta zaberá stĺpec SalesOrderNumber, čiže číslo objednávky:
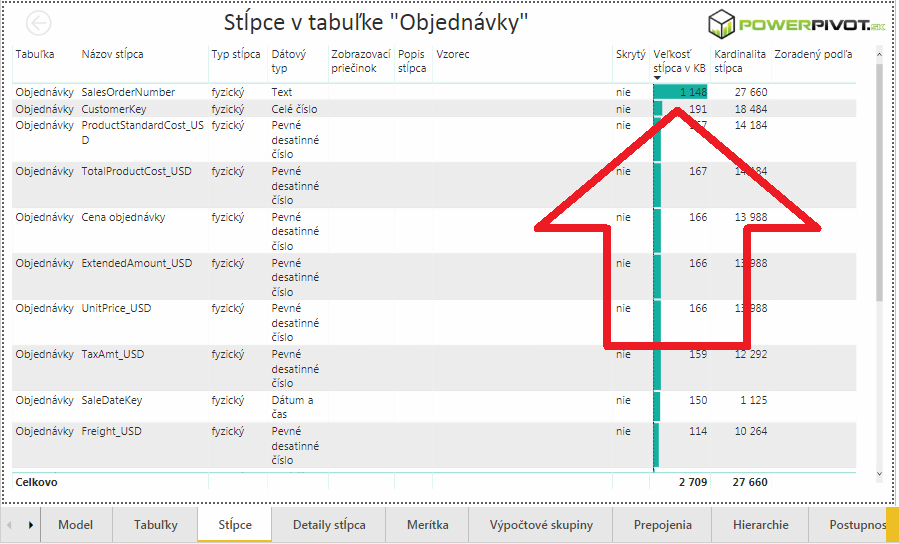
Tento stĺpec zaberá zhruba 50% miesta v pamäti v pomere k celkovej veľkosti tabuľky. Pričom je tam 20 ďalších stĺpcov, ktoré dokopy zaberajú toľko isto. Takže tento jeden stĺpec je vhodným kandidátom na zmenšenie dátového modelu.
Ako zmenšiť dátový model
Dátový model viete zmenšiť niekoľkými stratégiami. Najčastejšie z nich sú tieto:
- načítať menej dát do dátového modelu,
- načítať do modelu zoskupené dáta, ktoré zvyčajne zaberajú oveľa menej miesta ako pôvodné detailné dáta,
- odstrániť nepotrebné stĺpce a tabuľky,
- zlepšiť kompresiu stĺpcov,
- nahradiť stĺpce merítkami.
V našom prípade stratégiu 1 a 2 nemôžeme použiť, pretože znížia množstvo informácií v dátovom modeli, a to nechceme. Chceme v modeli ponechať všetky potrebné informácie. A číslo objednávky je bez diskusie jednoducho potrebné. Stratégiu 3 použiť nemôžeme tiež, pretože stĺpec SalesOrderNumber potrebujeme.
Zostávajú teda stratégie 4 a 5. A my ich teraz použijeme dokopy.
Ako však zlepšiť kompresiu stĺpca, kde sú na každom riadku unikátne hodnoty? V tomto prípade je síce v tabuľke 60 399 riadkov, a v tom stĺpci 27 660 unikátnych hodnôt, ale môžete to brať ako keby všetky tie hodnoty boli unikátne. Výsledok bude veľmi podobný.
Pomôžeme si prieskumom stĺpca, a pozrieme sa najprv na hodnoty v ňom. Hodnoty vyzerajú nejak takto:
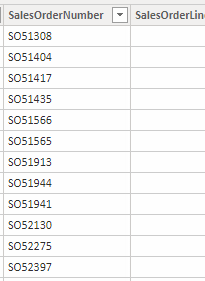
Tam si všimnite, že sú to textové hodnoty, a že všetky sú vo formáte „SO“ + 5-miestne číslo. A od toho sa odrazíme ďalej.
Detaily kompresných algoritmov nie sú presne známe, lebo sú vraj obchodným tajomstvom Microsoftu. A teraz až tak potrebné nebudú. My využijeme fakt, že PowerPivot vie oveľa lepšie komprimovať čísla ako reťazce. A skúsime, čo to spraví v našom prípade.
Vytvoríme si teda nový stĺpec v dátovom modeli, na začiatok pre otestovanie ako vypočítaný stĺpec. Keď to nezafunguje, tak stĺpec zmažete, a ak to zafunguje, tak ho vytvoríte buď v Power Query, alebo priamo v dátovom zdroji.
Vytvoríme ho tak, že z toho pôvodného stĺpca odstránime prefix „SO“, a zvyšok prekonvertujeme na celé číslo:
Nový stĺpec = INT(VALUE(MID([SalesOrderNumber]; 3; 5)))
V stĺpci bude stále 27 660 unikátnych hodnôt, čo na prvý pohľad nevyzerá, že by nejak malo zlepšiť kompresiu. Keď si však aktualizujeme dáta v Power BI Analyzeri, tak tam uvidíte, že tento nový stĺpec zaberá v pamäti iba 227 kB, namiesto pôvodných 1 148 kB:

Čo je takmer 5-násobná úspora pamäte. A tabuľku sme práve zmenšili na polovicu. Resp. bude zmenšená, keď to dokončíme a odstránime stĺpec SalesOrderNumber.
Ako však zobrazíme pôvodné číslo objednávky?
Veľmi jednoducho – vytvoríme si merítko, v ktorom tú hodnotu zrekonštruujeme. A keďže merítko nezaberá skoro žiadnu pamäť, tak nám to ani nezväčší dátový model.
Povedzme, že si predtým v reporte vytvoríme kontingenčku, kde je na riadkoch ten nový stĺpec (aby bolo vôbec z čoho vyrábať riadky v kontingenčke), a vedľa neho stĺpec „Cena objednávky“:
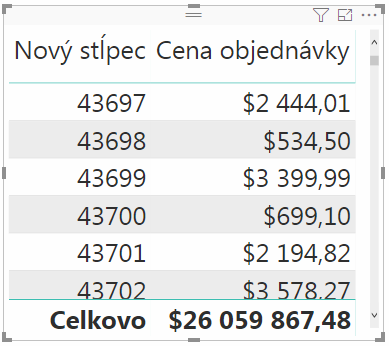
Do takejto kontingenčky stačí pridať ono merítko, ktoré si najprv vytvoríme týmto vzorcom:
Číslo objednávky := „SO“ & MAX(‚Objednávky'[Nový stĺpec])
…a po dosadení do kontingenčky to bude vyzerať takto:
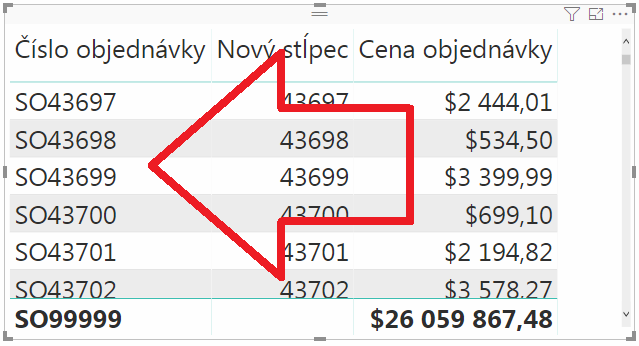
Ten stĺpec „Nový stĺpec“ potom môžete buď skryť, alebo mu nastaviť šírku na 1 pixel, podľa toho, ako vám to dovolí daný report. A práve ste dosiahli to, že užívateľ vidí svoje čísla objednávok v reporte, a vám sa po odmazaní pôvodného stĺpca SalesOrderNumber zmenší veľkosť tabuľky Objednávky na polovicu. Len potom nezabudnite vytvoriť ten optimalizovaný stĺpec „Nový stĺpec“ v dátovom zdroji, pretože teraz ho tam máte ako vypočítaný stĺpec, a po odmazaní stĺpca SalesOrderNumber prestane fungovať.
Ako zmenšiť dátový model znížením kardinality stĺpcov
Ak by ste však chceli ušetriť ešte viac pamäte, tak funguje ešte druhá, stará známa stratégia, vďaka ktorej zvýšite šancu na ešte väčšiu kompresiu stĺpcov. A to je rozdelenie stĺpca, ktorý obsahuje veľa hodnôt, na 2 a viac stĺpcov. Tým zo štatistického hľadiska prudko poklesne počet unikátnych hodnôt v každom dieliku z pôvodného stĺpca. A čím menej unikátnych hodnôt, tým viackrát sa tie hodnoty opakujú na tom istom počte riadkov. Čo znamená, že sa takéto dáta vo väčšine prípadov podarí viac skomprimovať.
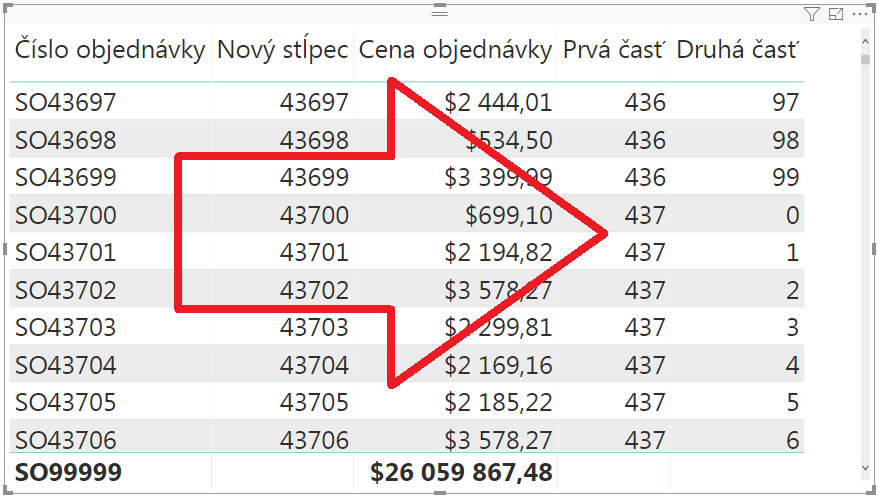
Rozdelíme teda náš optimalizovaný stĺpec „Nový stĺpec“ ešte na ďalšie 2 vypočítané stĺpce:
Prvá časť = INT(‚Objednávky'[Nový stĺpec] / 100)
Druhá časť = MOD(‚Objednávky'[Nový stĺpec]; 100)
Do prvej časti dáme prvé 3 číslice z pôvodného stĺpca, a do druhej časti dáme zvyšné 2 číslice z pôvodného stĺpca. Keď ich dosadíme do kontingenčky, tak to bude vyzerať takto:
Merítko „Číslo objednávky“ potom stačí mierne upraviť, podobne ako v predošlom prípade:
Číslo objednávky := „SO“ & (MAX(‚Objednávky'[Prvá časť]) * 100 + MAX(‚Objednávky'[Druhá časť]))
…alebo ak pôvodné číslo obsahovalo aj úvodné nuly, tak to zabaľte ešte do funkcie FORMAT:
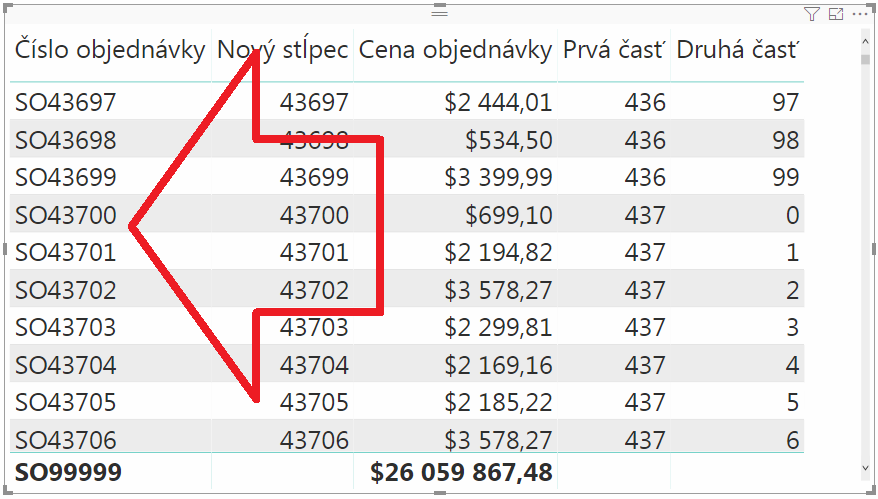
Číslo objednávky := „SO“ & FORMAT(MAX(‚Objednávky'[Prvá časť]) * 100 + MAX(‚Objednávky'[Druhá časť]); „00000“)
Výsledok bude identický ako na predošlom obrázku:
A ak chcete skryť to kvázi číslo objednávky v celkovom súčte, tak si prečítajte tento článok.
A ako to dokázalo zmenšiť dátový model?
Keď si znova dáme aktualizovať údaje v Power BI Analyzeri, tak to bude vyzerať takto:
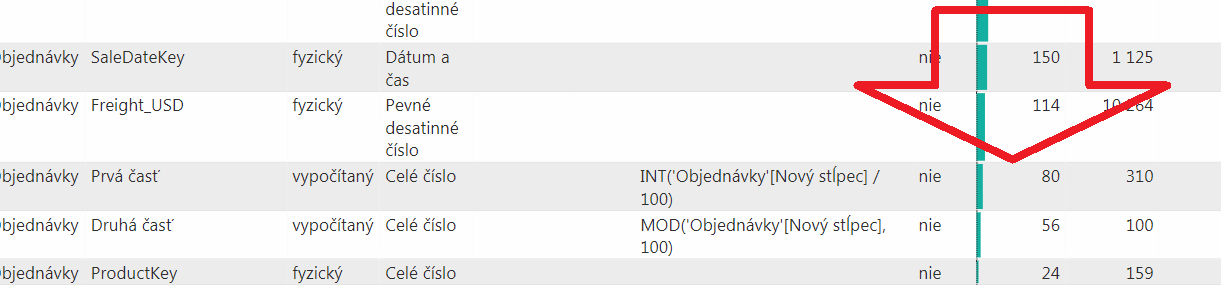
Budete musieť ísť v tej tabuľke o nejakú tú stranu nižšie, pretože tie 2 nové stĺpce sa v hitparáde veľkosti stĺpcov prepadli oveľa nižšie, medzi tie najmenšie stĺpce. Zaberajú 80 kB + 56 kB, čo je dokopy iba 136 kB. Čiže sme to z už optimalizovaného stĺpca s veľkosťou 227 kB stlačili skoro na polovicu. A keď to porovnáme s pôvodným stĺpcom SalesOrderNumber, ktorý mal 1 148 kB, tak sa nám podarilo zmenšiť ten stĺpec takmer 10-násobne. Pre detailistov, presne 8,44x 🙂 A to všetko bez straty informácií v dátovom modeli.
Takto to teda robia profesionáli. A toto je ešte len základná technika, a len jedna z mnohých, ktoré učím na Jedi Master kurze PowerPivotu a Power BI. Pretože niekedy táto technika nemusí zafungovať, a na jej správne použitie je potrebné poznať do hĺbky presné detaily toho, ako interne funguje dátový model, resp. PowerPivot. Aby ste vedeli, kedy to zafunguje, a čo sa s tým dá robiť, keď to nezafunguje. To by však vydalo aj na jednu dlhšiu kapitolu knihy. Takže dokým nenapíšem ďalšiu knihu, tak máte aspoň niečo, čo sa dá použiť. Každopádne, vo veľa prípadoch aj s týmto málom dosiahnete veľmi dobré výsledky. Stačí len dostatočne veľa experimentovať, a časom sa to podarí. Alebo dôjdite na Jedi Mastera, a naučíte sa to hneď 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.