Ideálny dátový model v PowerPivote a v Power BI by mal byť štruktúrovaný tak, ako popisujem v mojej knihe o Power BI a PowerPivote – čiže ako dátové tabuľky a číselníky. Čo zvyčajne nie je problém, keď importujete dáta z bežných databáz, pretože zvyčajne tam sú už uložené v takomto formáte. Čo však s tým, keď tak uložené nie sú? Napr. ak vám niekto sprístupní len jednu gigantickú tabuľku so všetkými stĺpcami pokope, a vy to chcete ešte skombinovať s plánovacími údajmi, a spoločne analyzovať? V tom prípade sa nevyhnete procesu normalizácie dát. A my si teraz ukážeme, ako si to viete spraviť sami v Power Query.
Proces normalizácie dát sa dá popísať ako rozbitie jednej veľkej tabuľky na viacero menších tabuliek, tak aby sa odstránilo čo najviac opakujúcich sa hodnôt z pôvodných dát, a aby zaberali čo najmenej miesta v databáze (a robili sa ľahšie aktualizácie dát a pod.). Toľko aspoň z matfyzáckeho pohľadu. V PowerPivote a Power BI nám opakujúce sa hodnoty zrovna nevadia, lebo tie si PowerPivot na pozadí vie veľmi dobre skomprimovať, takže normalizáciou dát neušetríte zrovna veľa pamäte. Z pohľadu analytiky a reportingu to má však výhodu v tom, že dáta vytiahnuté do osobitných číselníkov vám neskôr umožnia analyzovať podľa týchto číselníkov dáta vo viacerých tabuľkách súčasne. Čiže filtrovať, zoskupovať a triediť. Napr. taký časový číselník, resp. časová tabuľka, sa používa na analýzu plánu voči skutočnosti, kde máte uložené dáta pre plán aj skutočnosť v dvoch odlišných tabuľkách, prepojených spoločne na časovú tabuľku. Pre toto aj pre kopu ďalších dôvodov je dobré mať v dátovom modeli číselníky.
My si teraz ukážeme, ako sa dá v Power Query ľahko znormalizovať tabuľka, čiže ako z tabuľky vytiahnuť stĺpce do osobitného číselníka. Majme povedzme takúto denormalizovanú tabuľku, kde máme dokopy dáta objednávok (prvých 5 stĺpcov) aj dáta produktov (posledné 3 stĺpce):
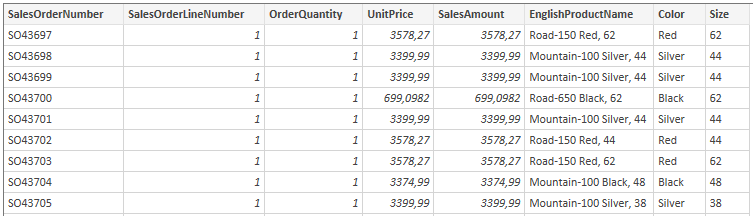
Vidíte, že dáta v posledných 3 stĺpoch sa dosť často opakujú. Teraz by sme potrebovali vytiahnuť tieto dáta o produktoch do osobitnej tabuľky, ktorá sa pre potreby analýz stane neskôr číselníkom. A podľa ktorého budeme môcť analyzovať dáta v tabuľke objednávok. Pôvodná tabuľka bude obsahovať iba číselný odkaz na daný riadok v tomto číselníku. Poďme teda na to.
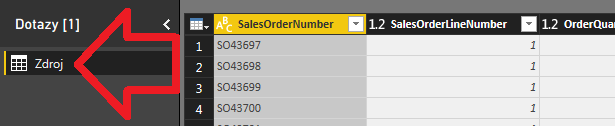
Vytvorte si v Power Query nový dotaz so svojimi dátami, ktoré potrebujete normalizovať, a nazvite ho Zdroj:
Tento dotaz potom zduplikujte cez možnosť „Odkaz„, najprv do dotazu s názvom Objednávky, a potom ešte raz do dotazu s názvom Produkty:
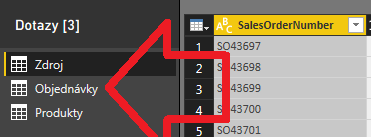
Dotaz Produkty na konci bude obsahovať iba tie 3 stĺpce z pôvodného Zdroja, a len unikátne riadky. Dotaz Objednávky na konci bude obsahovať tabuľku s objednávkami, bez tých 3 stĺpcov na konci, a namiesto nich len číselný odkaz na príslušný riadok v tabuľke Produkty.
Prvým krokom bude upraviť si dotaz Produkty tak, aby obsahoval iba číselník produktov. Choďte teda do tohto dotazu, označte všetky stĺpce okrem posledných troch, kliknite pravým tlačítkom myši na názov niektorého z označených stĺpcov, a zvoľte možnosť „Odstrániť stĺpce„:

V ďalšom kroku odstránime duplicitné riadky. Odstránime duplicity podľa všetkých 3 stĺpcov súčasne. Preto najprv označte všetky 3 stĺpce, potom kliknite pravým tlačítkom myši na názov niektorého z označených stĺpcov, a vyberte položku „Odstrániť duplikáty„:
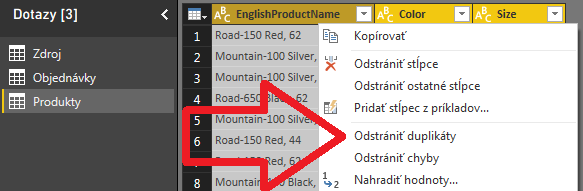
Toto v našom konkrétnom prípade zredukuje cca. 60 tisíc riadkov v tabuľke na 130 riadkov.
Následne potrebujeme očíslovať riadky, a toto číslo potom použiť ako referenciu na daný produkt v tabuľke/dotaze Objednávky. Riadky si očíslujeme tak, že v hlavnom menu prejdeme do záložky Pridať stĺpec, a tam klikneme na malú šípočku vedľa tlačítka Stĺpec indexu, a vyberieme položku „Od 1„:
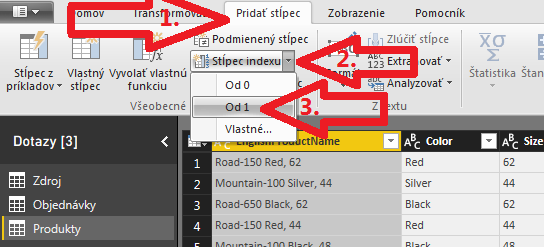
To nám očísluje všetky riadky postupne od 1 po N:
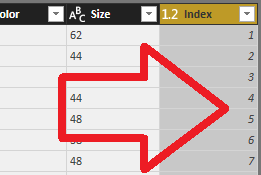
Túto tabuľku máme teda pripravenú, a môžeme sa vrhnúť na dotaz Objednávky. Tento dotaz zatiaľ obsahuje iba kópiu zdrojových dát z dotazu Zdroj. A do tohto dotazu si teraz najprv dotiahneme referenciu na daný produkt z dotazu Produkty (z toho novo vytvoreného stĺpca Index), a potom dáta produktov z tohto dotazu Objednávky zmažeme.
Prejdite teda do dotazu Objednávky. Posledné 3 stĺpce obsahujú dáta produktov, ktoré sme si znormalizovali do dotazu Produkty, a teraz sem potrebujeme dotiahnuť referenciu na príslušný riadok v tom dotaze. To spravíme tak, že v hlavnom menu prejdeme na záložku Domov, a na jej konci klikneme na tlačítko Zlučovacie dotazy:

Otvorí sa okno na zlučovanie dotazov, ktoré sa okrem iného dá použiť na dohľadanie referencie v inej tabuľke, alebo – ak sa vám to predstavuje lepšie – na simuláciu excelovského VLOOKUP-u. V strede okna vyberieme v roletke dotaz Produkty, a v oboch tabuľkách vyberieme, podľa ktorých stĺpcov sa majú dohľadať príslušné riadky k prvému dotazu Objednávky z druhého dotazu Produkty. V tomto prípade v oboch tabuľkách vyberieme súčasne cez kláves Ctrl a kliknutie myši, stĺpce s dátami produktov, a teda EnglishProductName, Color a Size, a stlačíme tlačítko OK:
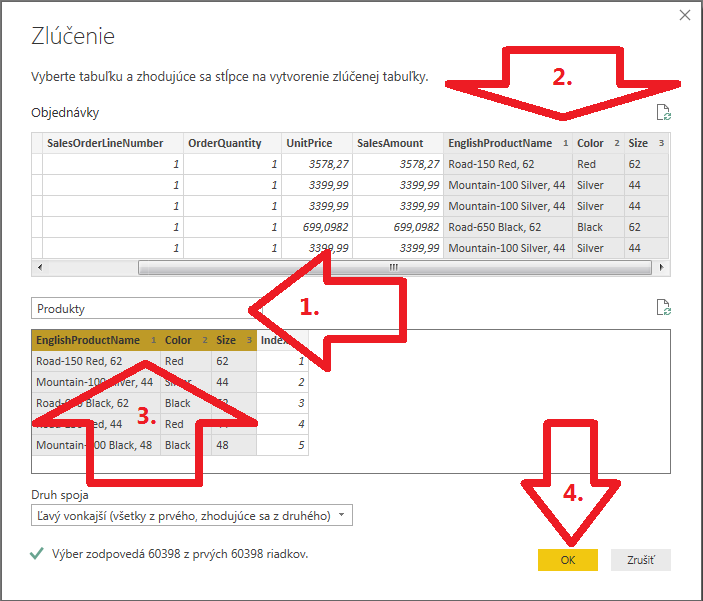
Po vykonaní operácie bude dotaz Objednávky obsahovať nový stĺpec Produkty, a bude vyzerať takto:
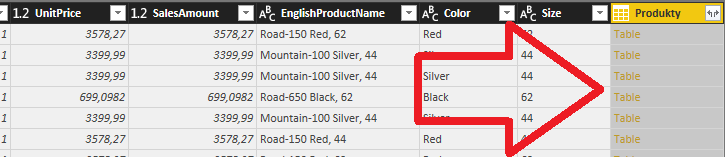
Tento stĺpec reprezentujúci tabuľku si potrebujeme rozbaliť len na tie stĺpce, ktoré odtiaľ potrebujeme. Konkrétne iba stĺpec Index, ktorý obsahuje referenciu na daný riadok s produktom. To spravíme tak, že v pravom hornom rohu toho stĺpca klikneme na tú ikonku s dvoma šípočkami, v otvorenom okne necháme zakliknutý iba stĺpec Index, a klikneme na tlačítko OK:
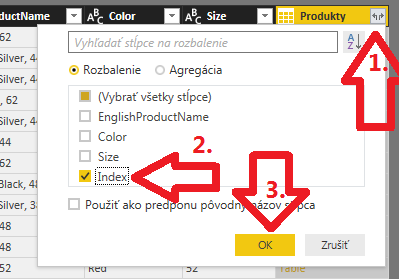
To nám rozbalí iba stĺpec s názvom Index, ktorého dáta teraz budeme mať v dotaze Objednávky:
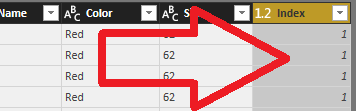
Teraz už v tomto dotaze nepotrebujeme tie 3 stĺpce EnglishProductName, Color a Size, a teda ich môžeme označiť a odstrániť:
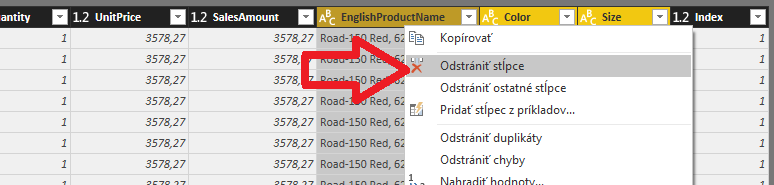
…a zostane nám pekný krásny dotaz iba s odkazom na tabuľku Produktov:

V realite si ešte premenujte stĺpec Index napr. na ProductID, aby bolo potom pri prepájaní tabuliek v PowerPivote / v Power BI jasné, čo s čím máte prepojiť.
A týmto istým spôsobom viete normalizovať ďalšie stĺpce do ďalších číselníkov, ak by ste to potrebovali.
Pred načítaním do dátového modelu dáme ale ešte skryť dotaz Zdroj, aby sa nám zbytočne nenačítaval do dátového modelu ako ďalšia tabuľka. To spravíme tak, že klikneme pravým tlačítkom myši na názov dotazu Zdroj, a tam odklikneme položku Povoliť načítanie (nesmie pri nej zostať tá fajka):
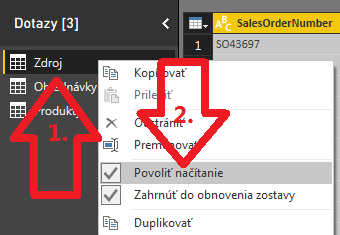
Po tomto dajte načítať dáta (tlačítkom Zavrieť a použiť, resp. Zavrieť a načítať, podľa toho či ste v Power BI alebo v Exceli). Po načítaní by ste mali vidieť v dátovom modeli iba tie 2 znormalizované tabuľky. A môžte si užívať novo nadobudnuté možnosti 🙂
Toto je teda základ techniky, ako znormalizovať tabuľky v Power Query. Toto by síce za vás mali robiť ľudia z IT, ktorí by vám mali pripraviť dáta už v takejto forme, ale nie vždy ich máte poruke, a tiež nie vždy majú čas či zdroje na to, aby vám to takto pripravili. Preto je dobré vedieť, že sa to dá takto spraviť aj v Power Query, a že to ide spraviť celkom ľahko 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.