Pri vytváraní filtrovaných ukazovateľov v jazyku DAX existuje ešte jeden spôsob zápisu filtrov okrem toho, ktorý som popisoval kedysi vo veľmi starom článku. Tým zápisom je tzv. indický zápis filtrov, ktorý sa s obľubou používa najmä na indických blogoch pre rýchle riešenia. Ale ak neviete, čo presne to robí, tak sa z rýchleho riešenia časom stane problém. Ktorý môže ľahko viesť k nesprávnym výpočtom, ak si nedáte na to pozor.
Indický zápis filtrov nie je oficiálny názov tejto techniky. Pretože žiadny oficiálny názov to v dokumentácii k jazyku DAX jednoducho nemá. Takto mi to niekedy dávno pomenoval niekto na jednom školení, pretože to často vídaval ako rýchle a jednoduché riešenie na indických blogoch, ktoré ale bez ďalších opatrení zlyhávalo v prípade výpočtu komplexnejších ukazovateľov. Používa sa samozrejme aj inde, ale keďže ma k tomu nenapadol lepší názov, tak to odvtedy volám aj ja indický zápis filtrov.
Klasické filtrované ukazovatele
Na demonštráciu tejto techniky filtrovania opäť využijeme náš vzorový súbor PowerPivotu, resp. Power BI.
Spravíme si kontingenčku, kde:
- do oblasti hodnôt dáme merítko Obrat z tabuľky Objednávky,
- do oblasti riadkov dáme stĺpce CalendarYear z tabuľky Čas.
Výsledná kontingenčka bude vyzerať takto:
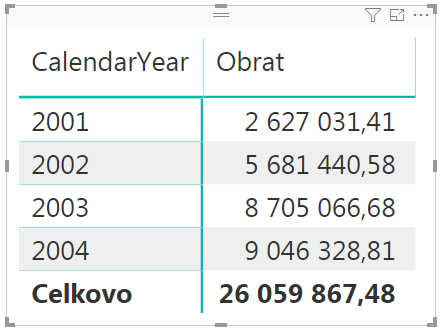
A teraz by sme chceli vytvoriť merítko, ktoré vypočíta obrat len v USA. Čiže potrebujeme vytvoriť filtrovaný ukazovateľ, kde nastavíme filter nad stĺpec Krajina v tabuľke Regióny na hodnotu „United States“. Také merítko už máme v dátovom modeli v tabuľke Objednávky, takže ho rovno použijeme:
Obrat za USA := CALCULATE( [Obrat] ; FILTER('Regióny'; 'Regióny'[Krajina] = "United States"))
Po dosadení do kontingenčky to bude vyzerať takto:
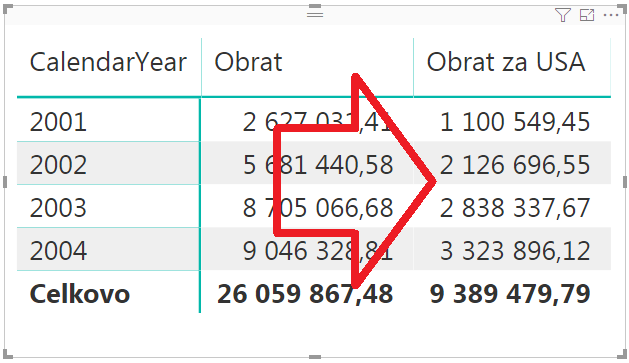
Kontingenčka teraz zobrazuje vedľa seba obrat za všetky krajiny vs. obrat za vybranú krajinu (USA). A výpočet je správny.
Indický zápis filtrov
Alternatívne sa však dá tento istý ukazovateľ vypočítať jednoduchšie, cez indický zápis filtrov. Zapisuje sa tak, že namiesto funkcie FILTER použijeme vo vnútri funkcie CALCULATE iba filtrovaciu podmienku. V tomto konkrétnom prípade teda vytvoríme takéto merítko:
Obrat za USA 2 := CALCULATE( [Obrat] ; 'Regióny'[Krajina] = "United States")
A po dosadení do kontingenčky bude výsledok identický, ako v prípade pôvodného merítka „Obrat za USA“, kde sme pridávali filter pomocou funkcie FILTER:
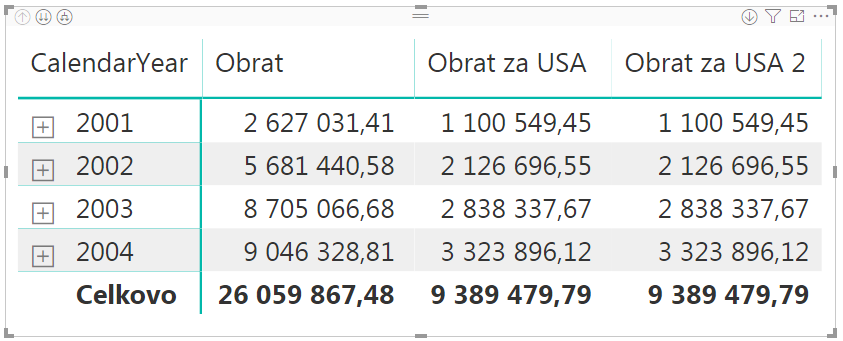
A keď je to teda takto jednoduché, tak prečo by sme si mali komplikovať situáciu so zložitejším zápisom cez funkciu FILTER? Pretože oba zápisy filtrov fungujú odlišne. A v závislosti od toho, aký chcete dostať výsledok, je nutné rozlišovať medzi tým, ktorý kedy použiť.
Rozdiel medzi oboma zápismi
Rozdiel medzi oboma zápismi je nasledovný:
- keď používate funkciu FILTER s CALCULATE, tak tento zápis pridá daný filter do kontextu výpočtu. Iba pridá. Nič viac, nič menej.
- keď používate indický zápis filtrov, tak tento buď pridá filter do kontextu výpočtu (ak v ňom ešte neexistuje filter nad daným stĺpcom), alebo prepíše filter v kontexte výpočtu (ak tam už existuje filter nad takým stĺpcom).
Čiže indický zápis filtrov nielen pridáva, ale aj prepisuje filtre v kontexte výpočtu. Čo môže byť fajn, keď práve toto potrebujete, ako napr. pri výpočte ukazovateľa za rovnaký týždeň pred rokom. Ale už nie fajn v iných prípadoch, kde takéto správanie nechcete.
Indický zápis filtrov si viete alternatívne prepísať aj na takýto zápis:
Obrat za USA 3 := CALCULATE( [Obrat] ; FILTER( ALL('Regióny'[Krajina]) ; 'Regióny'[Krajina] = "United States"))
Pretože vo svojej podstate je to to isté, ako keby ste najprv zrušili filter nad stĺpcom Krajina, a potom ho nastavili naspäť s inou hodnotou filtra. Tento posledný zápis spraví to isté, a je tu iba pre demonštráciu toho, že to ide aj takto. Aj keď nemá zmysel si to takto zbytočne komplikovať.
A kde je teda problém?
Problém je v tom, keď v kontexte výpočtu už existuje filter nad tým stĺpcom, ktorý sa pokúšate filtrovať. Keď si dosadíme do našej kontingenčky, do oblasti riadkov, stĺpec Krajina z tabuľky Regióny – čiže ten istý stĺpec, nad ktorým nastavujeme filter v našich merítkach – tak po dosadení do kontingenčky hneď uvidíte rozdiel:
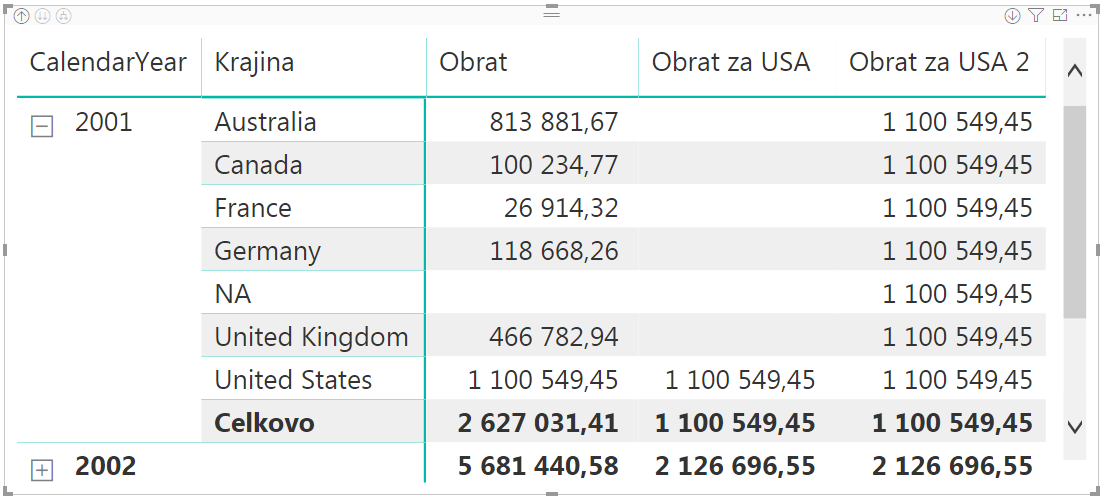
Tu vidíte, že v prvom prípade (merítko „Obrat za USA“), keď sme pridávali filter do kontextu výpočtu cez funkciu FILTER, tak to vypočítali Obrat iba pri krajine „United States“. V druhom prípade, keď sme pridávali filter cez indický zápis filtrov, to vypočítalo rovnaký obrat pri každej krajine. A ten obrat je Obrat za USA, ako keby rozkopírovaný ku každej krajine. Lenže DAX nerozkopírováva. Len sa prejavilo to správanie tohto zápisu, ktorý popisujem vyššie.
Zoberme si napr. takúto bunku, ktorá prislúcha roku 2001 a krajine France:
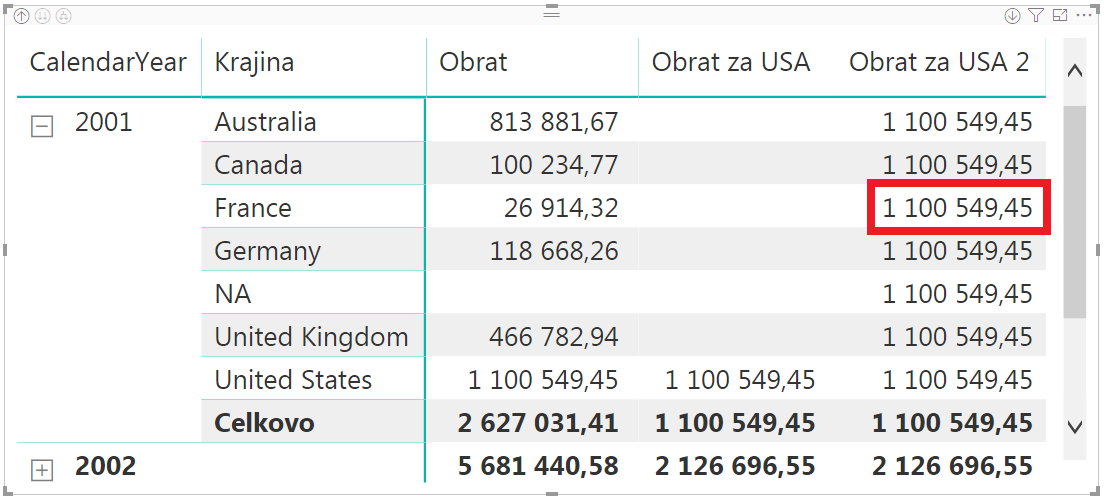
V tomto prípade je kontext výpočtu tejto bunky definovaný týmito 2 daxovými filtrami:
- Čas[CalendarYear] = 2001
- Regióny[Krajina] = France
A keď teraz chceme vypočítať merítko „Obrat za USA 2“ v takomto kontexte výpočtu, tak nami použitý indický zápis filtrov spôsobí to, že namiesto pridania filtra do kontextu výpočtu, to nahradí filter nad stĺpcom Regióny[Krajina]. A zmení jeho hodnotu na „United States“. Preto nám vypočíta v skutočnosti obrat za USA, napriek tomu že na danom riadku kontingenčky máme krajinu France.
Výhody a nevýhody pre indický zápis filtrov
Je to zlé? To závisí od toho, čo sa pokúšate vypočítať. Ak robíte napr. benchmarking, čiže porovnanie všetkých ostatných krajín oproti zvolenej krajine, tak je to presne to, čo potrebujete. Alebo ak potrebujete nahradiť/prepísať filter v kontexte výpočtu, ako som to použil napr. v tomto článku. Prípadne v tone ďalších situácií, kde potrebujete presne takéto správanie.
Výhodou indického zápisu filtrov je jeho jednoduchosť, a v prípade komplikovanejších vzorcov aj oveľa rýchlejší výpočet ako pri použití funkcie FILTER. Jeho nevýhodou je však to, že väčšinou môžete použiť iba jednoduché podmienky vo formáte „stĺpec operátor hodnota“. Čiže napr. „stĺpec = 7“ alebo „stĺpec > 7“. Nemôžete tam vo všeobecnosti použiť zložené podmienky, a ani väčšinu funkcií jazyka DAX. Zjednodušene povedané, indický zápis filtrov musí byť vyhodnotiteľný v rámci jedného stĺpca, riadok po riadku (pretože to je iterátor), a môžu byť ňom použité iba niektoré jednoduché funkcie jazyka DAX. Všetky obmedzenia sú popísané v oficiálnej dokumentácii. Čiže môžete použiť aj zložené podmienky, za predpokladu, že sú vyhodnotiteľné v rámci toho 1 stĺpca.
Aktualizácia 9.4.2021: Indický zápis filtrov je možné používať aj cez viaceré stĺpce súčasne, za určitých podmienok. Podrobnosti nájdete v tomto článku.
Výhodou pridávania filtrov cez funkciu FILTER je zasa to, že v tejto funkcii môžete použiť ľubovoľnú filtrovaciu podmienku. Môžete použiť aj ľubovoľne zložité podmienky, vrátane zložených podmienok, funkcií a podobne. Jedinou podmienkou je to, aby sa tá podmienka dala vyhodnotiť v rámci tej tabuľky, resp. voči tej tabuľke, ktorú zadávate do prvého parametra funkcie FILTER (a keď sa nedá vyhodnotiť, tak to ide spraviť napr. tak ako v tomto článku). Inak máte voľnú ruku. Nevýhodou je jedine to, že funkcia FILTER môže, ale nemusí byť oveľa pomalšia ako indický zápis filtrov s tou istou podmienkou. To sa však dá vždy nejako prežiť a prepísať na jeden, alebo druhý spôsob.
Takto teda funguje indický zápis filtrov. Kompletné vysvetlenie oboch zápisov, vrátane zložených kontextov výpočtu, by zabralo niekoľko článkov. Keď sa však s tým pár týždňov pohráte, tak by to malo byť jasné. Alebo dôjdite na môj najnovší workshop. Tam si to rozoberieme ešte oveľa, oveľa podrobnejšie 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.