Kumulatívny histogram je relatívne zriedkavo používaná analytická technika, ktorá väčšinou sama o sebe nemá využitie. Používa sa však ako prípravný krok do ďalších analýz, napr. Paretovej analýzy, pomocou ktorej sa optimalizuje portfólio produktov, portfólio projektov, či iné početné jednotky. Preto sa teraz pozrieme, ako spraviť kumulatívny histogram v excelovskom PowerPivote aj v Power BI.
V tomto príklade znova použijeme náš vzorový súbor PowerPivotu, resp. Power BI.
Najprv si vytvoríme kontingenčku, kde:
- na riadkoch bude stĺpec ProductKey z tabuľky Objednávky,
- v oblasti hodnôt bude merítko Obrat z tabuľky Objednávky,
- kontingenčku dáme zotriediť od najväčších obratov po najmenší.
Kontingenčka bude vyzerať takto:
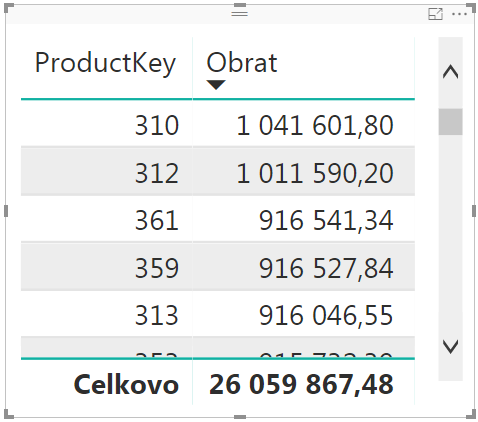
Táto kontingenčka zobrazuje sumu obratu za každý produkt. A v nej vidíte, že najpredávanejšie produkty sú produkty č. 310, 312 a 361. Čísla produktov v tomto článku používame kvôli jednoznačnej identifikácii produktov, pretože názvy produktov v našom vzorovom súbore jednoznačné nie sú.
Teraz by sme chceli spraviť kumulatívny histogram z týchto dát. Po slovensky povedané – chceli by sme spraviť graf, kde na osi X budú jednotlivé produkty, zoradené od najviac po najmenej predávané, a na osi Y bude pre daný produkt vypočítaný kumulatívny obrat za daný produkt a všetky menej predávané produkty súčasne. Čiže pre prvý, najmenej predávaný produkt bude zobrazený iba jeho obrat, za druhý najmenej predávaný produkt bude zobrazený obrat za tieto 2 produkty, a tak ďalej, až pri poslednom produkte – najpredávanejšom – bude zobrazený celkový obrat za všetky produkty. Ak potom dáte zoradiť takýto graf v opačnom poradí produktov, tak bude klesajúci od začiatku až po koniec. A toto bude náš kumulatívny histogram.
Riešenie v jazyku DAX nie je až tak ťažké. Stačí si ako vždy vytvoriť vhodné merítko, skombinovať dokopy tie správne daxové prísady, a dielo bude na svete.
Vytvoríme si teda takéto, na prvý pohľad komplikované merítko:
Kum. obrat :=
VAR ObratyPoProduktoch =
ADDCOLUMNS (
SUMMARIZE (
CALCULATETABLE ( 'Objednávky'; ALL ( 'Objednávky'[ProductKey] ) );
'Objednávky'[ProductKey]
);
"Obrat za produkt"; [Obrat]
)
VAR ObratyPoProduktochPlusPoradie =
ADDCOLUMNS (
ObratyPoProduktoch;
"Poradie"; COUNTROWS (
FILTER (
ObratyPoProduktoch;
EARLIER ( [Obrat za produkt] ) <= [Obrat za produkt] ) ) )
VAR PoradieAktProduktu =
MAXX ( FILTER ( ObratyPoProduktochPlusPoradie; [ProductKey] = MAX ( [ProductKey] ) ); [Poradie] )
RETURN
SUMX ( FILTER ( ObratyPoProduktochPlusPoradie; PoradieAktProduktu <= [Poradie] );
[Obrat za produkt]
)
A čo to robí?
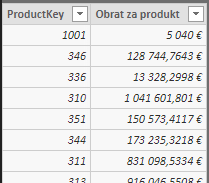
Na začiatku sme si zadefinovali 3 premenné. Prvá premenná zosumarizuje všetky objednávky podľa stĺpca ‚Objednávky'[ProductKey], pri rešpektovaní ostatných prípadných „neproduktových“ filtrov (CALCULATETABLE + SUMMARIZE). Následne sa do takejto tabuľky dopočíta stĺpec „Obrat za produkt“, v ktorom bude obrat za každý produkt. Táto premenná bude obsahovať potom takúto tabuľku:
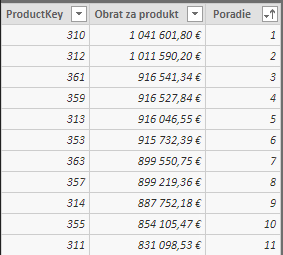
Následne takúto tabuľku použijeme v druhej premennej, nazvanej ObratyPoProduktochPlusPoradie, kde k tejto tabuľke pridáme stĺpec „Poradie“. V tomto stĺpci bude poradie predajnosti daného produktu podľa jeho obratu, kde najpredávanejší produkt bude mať poradie 1. V iných prípadoch by to išlo spraviť priamo funkciou RANK.EQ, ale keďže táto funkcia nefunguje na stĺpcoch vypočítaných „za behu“, tak sme si ju museli naemulovať cez funkcie COUNTROWS, FILTER a EARLIER. Výsledná medzitabuľka v tejto premennej bude vyzerať takto (pre účely článku zoradená podľa poradia):
A nad takouto tabuľkou sa už jednoducho dá spočítať kumulovaný obrat. Predtým si ale ešte pre zjednodušenie vzorca zistíme poradie aktuálne počítaného produktu, a uložíme ho do 3. premennej s názvom „PoradieAktProduktu“.
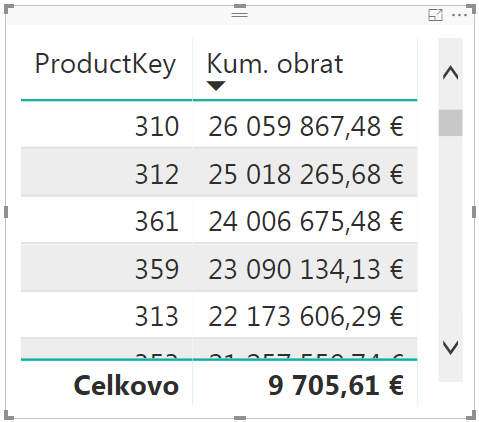
Následne už konečne spustíme hlavnú časť vzorca za slovíčkom RETURN, kde si funkciou FILTER vyfiltrujeme všetky riadky z poslednej tabuľky, ktoré majú v stĺpci Poradie väčšiu alebo rovnú hodnotu ako hodnota Poradia pre aktuálne počítaný produkt. Tieto riadky potom jednoducho zosumujeme cez funkciu SUMX podľa stĺpca „Obrat za produkt“, a máme pekne krásne vypočítaný kumulatívny obrat za daný produkt a všetky produkty s menšími obratmi súčasne. Po zobrazení v kontingenčke a jej zoradení podľa kum. obratu zostupne, to bude vyzerať takto:
Po otočení do grafu dostaneme náš kumulatívny histogram:
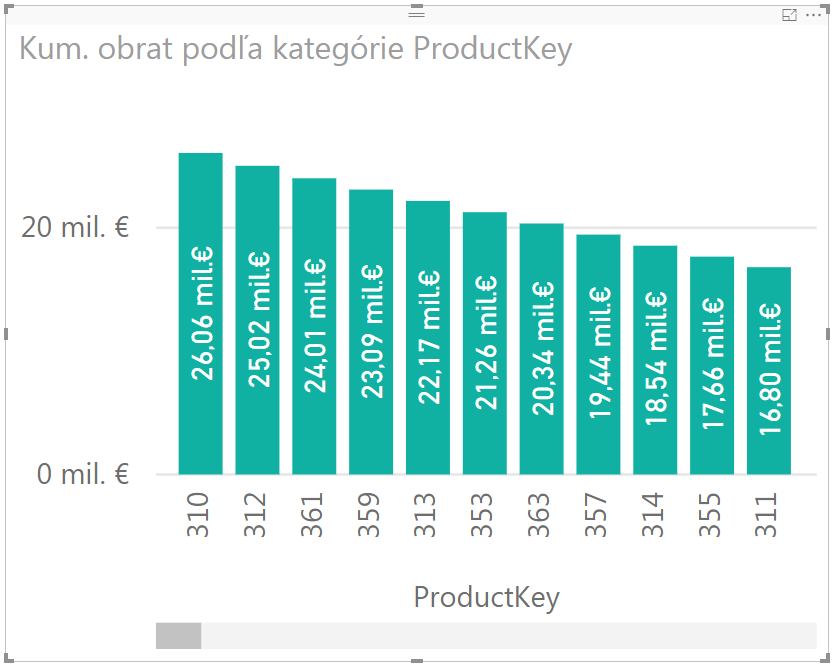
Tam vidíte, že najpredávanejšie produkty zo začiatku tohto článku – č. 310, 312 a 361 – sú zobrazené aj tu na prvých priečkach v grafe. Produktov je na grafe cca. 150, a zobrazený je iba začiatok grafu. Z technických príčin 😀
A čo teraz s tým?
Takéto grafy sa používajú na Paretovu analýzu, čiže to, čo poniektorí z vás poznajú pod označením „pravidlo 80/20“. Pareto bol taliansky matematik, ktorý prišiel s teóriou, že 80% dôsledkov pramení z 20% príčin. Preložené do jazyka analytiky – že 80% predajov je zvyčajne z 20% produktov, a opačne. Pri niektorých firmách to platí, pri niektorých nie. Niekde je ten pomer až 90:10 a vyššie, inde je to zhruba 50:50. A našou úlohou je to v tomto prípade overiť.
Spravíme si teraz teda jednoduché merítko, ktoré bude zobrazovať čiaru vo výške 80% celkových predajov. To bude takéto:
80 percent = CALCULATE(SUM(‚Objednávky'[Cena objednávky]) * 0,8; ALL(‚Objednávky'[ProductKey]))
Merítko spočíta 80% zo sumy cien všetkých objednávok, po zrušení filtra nad produktami v aktuálnom kontexte výpočtu. Po jeho pridaní ako čiary do grafu to bude vyzerať takto:

Tam hneď vidíme, či sa nám hypotéza potvrdila alebo nie. Referenčná 80% čiara pretína 6. najpredávanejší produkt v poradí, čo znamená, že prvých 6 produktov zo 150 prispieva cca. 20 percentami k celkovému obratu. To je síce od klasického Paretovho pravidla na míle ďaleko, ale ako som už vravel, tak u každej firmy je to iné. A toto sú okrem iného syntetické dáta, takže na reálnych dátach sa to pravdepodobne prejaví viac.
Každopádne, takto si to viete overiť celkom jednoducho, či to vo vašej firme platí alebo nie, a prípadne si nájsť potom aj vlastnú pomerovú čiaru. Napr., keby sme chceli vidieť, koľkými percentami sa v tomto prípade podieľa 20% najpredávajnejších produktov na celkovom obrate, tak môžeme spraviť napr. takéto merítko:
Obrat pre TOP20 percent produktov :=
VAR ObratyPoProduktoch =
ADDCOLUMNS (
SUMMARIZE (
CALCULATETABLE ( 'Objednávky'; ALL ( 'Objednávky'[ProductKey] ) );
'Objednávky'[ProductKey]
);
"Obrat za produkt"; [Obrat]
)
VAR ObratyPoProduktochPlusPoradie =
ADDCOLUMNS (
ObratyPoProduktoch;
"Poradie"; COUNTROWS (
FILTER (
ObratyPoProduktoch;
EARLIER ( [Obrat za produkt] ) <= [Obrat za produkt]
)
)
)
VAR PocetVsetkychPredanychProduktov =
COUNTROWS ( ObratyPoProduktoch )
RETURN
SUMX (
FILTER (
ObratyPoProduktochPlusPoradie;
[Poradie]
<= ROUNDUP ( PocetVsetkychPredanychProduktov * 0,2; 0 )
);
[Obrat za produkt]
)
Je to to isté merítko ako „Kum. obrat“ vyššie, len v tomto prípade ako 3. premennú počítame počet všetkých predaných produktov, aby sme potom následne v hlavnej časti vzorca mohli vyfiltrovať z našej zosumarizovanej tabuľky v premennej iba tie riadky/produkty, ktorých poradie je menšie alebo rovné 20% z celkového počtu všetkých predaných produktov. Po dosadení do grafu to bude vyzerať takto:
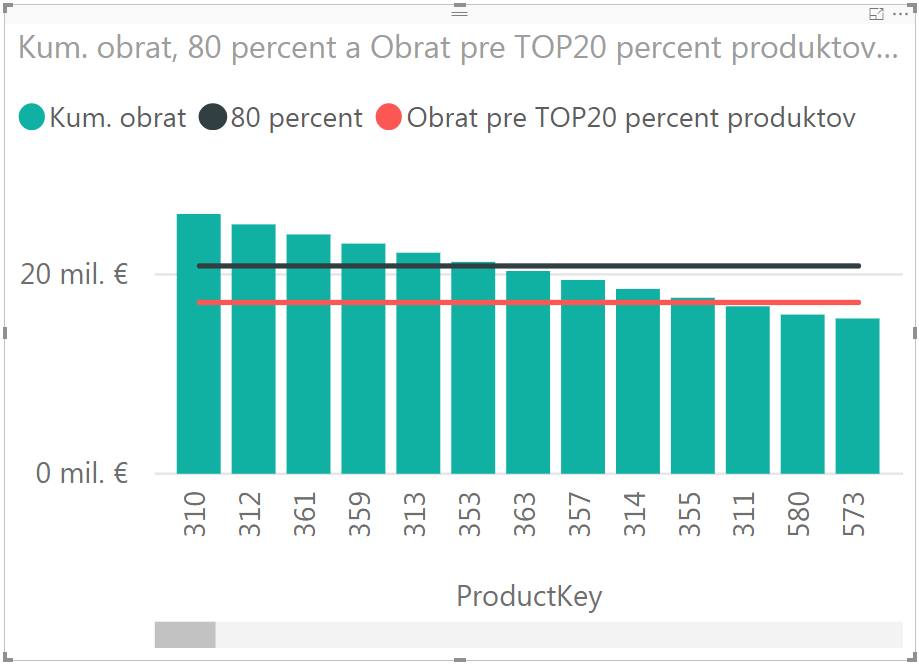
Keď si dáte zobraziť hodnotu toho merítka, tak to bude cca. 17,19 mil. eur. Čo je cca. 66% z celkového obratu firmy. Čiže 20% najpredávanejších produktov sa v tomto prípade podieľa na 66% obratu firmy. Čo nie je zlé číslo. Ale najmä sme zistili, aký je ten pomer v prípade našich dát.
Takto sa teda dá spraviť kumulatívny histogram, aj základná Paretova analýza. Na prvý pohľad dlhé komplikované merítka, ale po troche praxe je to iba trochu zložitejší, relatívne základný vzorec. Nie nutne optimálny z výpočtového hľadiska, ale aspoň sa dá rýchlo pochopiť. A to je na tom to podstatné 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.