Pri svojich projektoch u klientov sa často stretávam s jedným zásadným problémom, keď sa vyberá analytická technológia – a to, že z nejakého dôvodu v IT brandži prevláda stále názor, že tabulárne modely sú pomalé pre veľké množstvo dát. Ako logické zdôvodnenie ľudia často používajú dôvod, že „PowerPivot bude vždy pomalší ako OLAP kocky, pretože spočítať miliardu riadkov trvá vždy oveľa dlhšie ako zobrať predpočítané dáta z OLAP kocky“. Čo je na jednej strane pravda, ale kto povedal, že PowerPivot si nedokáže predpočítať tieto dáta tiež? A že je to dokonca extrémne jednoduché? 🙂 Poďme sa teda pozrieť, ako na to.
Obrovskou výhodou tabulárneho modelu je to, že môžete veľmi ľahko vzájomne kombinovať dáta zo všetkých tabuliek medzi sebou. A v tomto kombinovaní Vám pomôžu vzťahy, resp. prepojenia medzi tabuľkami. To vieme potom využiť na pokročilú analytiku, ale aj na optimalizáciu výpočtov. Napr. tým, že si často používané súhrny predpočítame dopredu ako vypočítané stĺpce v číselníkoch, alebo v osobitných, tzv. agregačných tabuľkách. Ak používate PowerPivot v3, tak to viete spraviť pomerne jednoducho za pár sekúnd pomocou vypočítaných tabuliek z DAX dotazov. Ak máte starší PowerPivot, pôjde to tiež, len Vám to zaberie o nejakú minútu-dve času naviac 🙂
Ideme si teda ukázať základ toho, ako si predpočítať dáta v dátovom modeli, a ako ich potom ďalej využiť vo svojich výpočtoch. Na predpočítanie sa používajú 2 hlavné spôsoby:
- predpočítanie dát do číselníka,
- predpočítanie dát do agregačnej tabuľky.
Prvý spôsob sa používa vtedy, keď potrebujete urýchliť v kontingenčke dátové rezy pomocou iba samotného číselníka (čiže máte nejakú kontingenčku, ktorá zobrazuje rozpad nejakej veličiny napr. podľa zložiek času – rok, mesiac, deň). Druhý spôsob je univerzálnejší, ale nie vždy sa dá použiť priamo, a v niektorých extrémnych prípadoch treba kombinovať viacero takýchto tabuliek dokopy. Ako základ však používa princíp z prvého spôsobu, a preto si tu teraz rozoberieme prvý spôsob. Po jeho zvládnutí veľmi rýchlo pochopíte aj druhý spôsob, ktorému sa budem venovať v ďalšom článku 🙂
Prvý spôsob spočíva v tom, že si najprv určíme tabuľku s číselníkom, pre ktorý potrebujeme urýchliť výpočty v kontingenčke. Majme takúto kontingenčku:
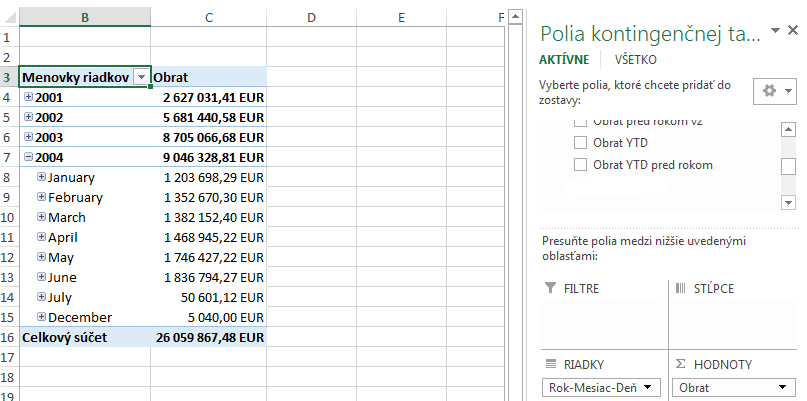
Na riadkoch máme hierarchiu „Rok-Mesiac-Deň“ z časovej tabuľky, a v oblasti hodnôt je staré známe merítko Obrat, ktoré počíta sumu cien objednávok z tabuľk Objednávky za aktuálny rozklik:
Obrat := SUM(‚Objednávky'[Cena objednávky])
Za týmto zobrazením je nejaký DAX alebo MDX dotaz, pomocou ktorého Excel vyťahuje z PowerPivotu tieto dáta. Napríklad, ak chcete zobraziť obrat po rokoch, tak Vám ho vráti tento DAX dotaz:
EVALUATE
ADDCOLUMNS(VALUES(‚Čas'[CalendarYear]), „Obrat“, [Obrat])
Tento dotaz vráti výsledok na našom vzorovom súbore za 45 milisekúnd. Čo nie je zlý čas, ale na miliarde riadkov by to bolo tak 5-10 sekúnd 🙂 My ho použijeme ako porovnávací čas po vykonaní optimalizácie, aby sme vedeli, o koľko sa to zlepšilo. Pretože, čo neviete zmerať, to neviete kontrolovať 😉
Ideme si teda predpočítať dáta do číselníka, ktorý sme použili – do časovej tabuľky. Tá obsahuje 1 riadok pre každý deň v histórii objednávok. A my si ku každému takémuto dňu spočítame obrat za daný deň. Ten sa bude dať následne využiť na rýchlejší výpočet obratu podľa všetkých ostatných stĺpcov v tomto číselníku, ako rok, mesiac, štvrťrok, … Obrat si predpočítame ako nový vypočítaný stĺpec týmto vzorcom, a s názvom „Obrat za den“:
= SUMX(RELATEDTABLE(‚Objednávky‘); ‚Objednávky'[Cena objednávky])
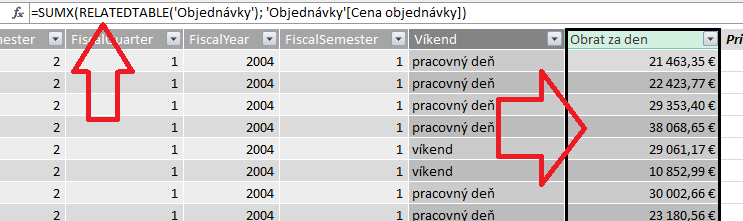
Následne z neho vytvoríme merítko v tabuľke Objednávky, ktoré sa bude počítať len vtedy, keď sme dali filtrovať aktuálny kontext časovou tabuľkou:
Obrat rýchly := IF(ISCROSSFILTERED(‚Čas'[DateKey]); SUM(‚Čas'[Obrat za den]); BLANK())
V ňom využívame funkciu ISCROSSFILTERED, ktorá vracia hodnotu true, keď je kontext merítka filtrovaný zadaným stĺpcom priamo alebo nepriamo. A keď do tejto funkcie dosadíte do parametra primárny kľúč tabuľky (resp. ten stĺpec, cez ktorý máte tento číselník prepojený na hlavnú tabuľku), tak tým zabezpečíte to, že funkcia vráti vždy true, keď je aktuálny kontext merítka filtrovaný ľubovoľným stĺpcom z tohto číselníka. A vďaka tomu sa toto merítko bude počítať len vtedy, keď je v kontingenčke vybraný na riadkoch alebo na stĺpcoch niektorý zo stĺpcov časovej tabuľky 🙂
Na overenie – keď teraz pridáme toto nové merítko do kontingenčky, bude vracať rovnaké hodnoty ako merítko Obrat (s výnimkou Celkového súčtu, ale to viete opraviť v DAXe za pár sekúnd):
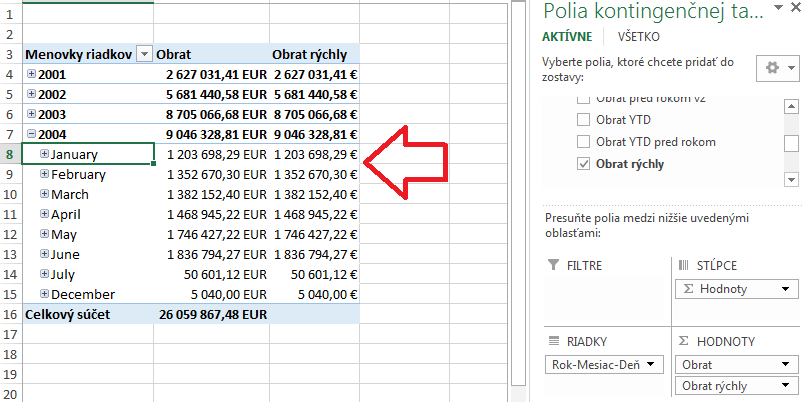
A teraz to podstatné – keď prepíšeme DAX dotaz zhora, ktorý predtým používal merítko Obrat, na naše nové merítko „Obrat rýchly“, bude to vyzerať takto:
EVALUATE
ADDCOLUMNS(VALUES(‚Čas'[CalendarYear]), „Obrat“, [Obrat rýchly])
Tento dotaz zbehne za 14 milisekúnd, čo znamená 3,2x rýchlejšie ako pôvodný dotaz. Podotýkam, že po zmazaní dátovej cache PowerPivotu (pretože aj ten si v sebe drží niektoré predpočítané výsledky z predchádzajúcich dotazov). To je celkom solídne zrýchlenie. A to sa prejaví o to viac, čím viac riadkov máte v dátovom modeli. Ak ich budete mať 1 miliardu, tak môžete čakať zrýchlenie z 5-10 sekúnd na cca. 50 milisekúnd, čo je 100-200x rýchlejšie ako pôvodný dotaz. A to je rovnako, ak nie ešte rýchlejšie, ako OLAP kocka na rovnakých dátach 🙂
Takto sa teda dajú predpočítať dáta dopredu, a urýchliť PowerPivot na úroveň OLAP kociek. Toto riešenie však nie je univerzálne, pretože keď do kontingenčky pridáte stĺpec z inej ako časovej tabuľky, tak to bude zobrazovať nesprávne dáta (v podstate bude ignorovať všetko okrem časovej tabuľky). Použijeme ho však ako základ do univerzálneho predpočítania dát, ktoré si ukážeme v nasledujúcom článku. Tam si ukážeme fintu, ako tieto vedomosti zúročiť tak, aby to fungovalo správne za každých okolností. Dovtedy, ak máte nejaké užitočné postrehy, napíšte ich do komentárov pod článkom 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.