V súvislosti so zavádzaním smernice GDPR sa v poslednej dobe rozmohli riešenia na maskovanie dát v databázach, aby užívatelia nevideli to, čo nemajú vidieť. Do SQL Servera 2016 bola na tento účel pridaná funkcionalita nazývaná dynamické maskovanie dát – Dynamic Data Masking – ktorá sa práve kvôli prechodu na GDPR začala hojne využívať aj v našich končinách. Väčšina ľudí však nevie, že táto funkcia nie je bezpečnostnou funkciou, a teda ani negarantuje bezpečnosť dát. A s modernými nástrojmi ako Power BI alebo Power Query sa dá elegantne obísť za pár minút, a dostať sa k dátam, ktoré užívateľ nemá vidieť. Preto si teraz ukážeme, ako ľahko sa to dá obísť, a ako to zabezpečiť lepšie.
Ak ste ešte nečítali o dynamickom maskovaní dát, tak si o tom môžete prečítať podrobnejšie napr. na oficiálnej stránke Microsoft Docs venujúcej sa tejto funkcionalite. V skratke to funguje tak, že dáta, ku ktorým užívateľ nemá mať prístup, sa mu zobrazia maskované. Napríklad, ak máme takúto tabuľku s názvom Zamestnanci:
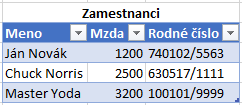
…a nastavíme maskovanie na stĺpce Mzda a Rodné číslo, tak sa čísla v týchto stĺpcoch budú vo všetkých aplikáciách zobrazovať takto:

To na prvý pohľad vyzerá fajn – nemuseli sme meniť aplikácie, a užívatelia nevidia citlivé údaje. Na prvý pohľad bezpečnosť vyriešená, vyzerá to že to funguje, a môže sa ísť na piv…riešenie ďalšej úlohy. Až dokým sa na hore uvedenej stránke nezačnete rýpať v technologických detailoch, ako to presne funguje. A tam nájdete to, že maskovanie dát prebieha po vykonaní výsledku (databázového dotazu), tesne predtým ako sa vráti výsledok užívateľovi. Čiže najprv sa zavolá databázový dotaz – ktorý musíte zavolať vy alebo aplikácia ako PowerPivot / Power Query / Power BI – a až po získaní výsledkov prebehne maskovanie dát. Keď však ovládate aspoň základy jazyka SQL, tak môžete snáď v každom jednom nástroji napísať SQL dotaz, ktorý vráti len také výsledky, aké chcete. A to sa dá celkom ľahko zneužiť na hádanie presných hodnôt hrubou silou.
Ako to obísť
Povedzme, že máte maskované dáta ako na obrázku vyššie, ale chcete vedieť, akú výplatu má Chuck Norris. Podľa mena by sa jeho výplata ani nemala zmestiť do toho stĺpca. Ale zvedavosť Vám nedá, a musíte to vedieť, lebo inak sa Vám zrúti svet, a nič už nebude také, ako bývalo. Preto to skúsite cez hádanie pomocou SQL dotazu. Napr. keď napíšete takýto dotaz, ktorý vráti zoznam všetkých zamestnancov s výplatou od 1000 do 2000 eur:
SELECT * FROM zamestnanci WHERE mzda >= 1000 AND mzda <= 2000
…tak Vám to nevráti žiadne riadky. Môžete ho ale upraviť na ďalší interval:
SELECT * FROM zamestnanci WHERE mzda >= 2000 AND mzda <= 3000
… a voaláá, vráti nám to jeden riadok:
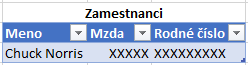
Nevidíme síce presnú hodnotu, ale postupným znižovaním rozsahu intervalu sa k tomu viete veľmi rýchlo dostať. Napr. pomocou metódy delenia intervalu sa dostanete k presnej hodnote na 1 euro po 10-12 krokoch. SQL Server síce nezobrazuje stále presnú hodnotu, ale keď sa dopracujete k dotazu typu „vráť mi zamestnancov s výplatou od 2500 do 2501 eur„, a vráti vám to Chucka Norrisa, tak je asi jasné, čo je ukryté za tými X-kami.
A ako uhádnuť textovú hodnotu?
Jednoducho – budeme hádať po jednom písmenku. Napr. keby sme chceli uhádnuť rodné číslo Chucka Norrisa, tak využijeme to, že rodné číslo začína číslicou. Máme teda 10 možností. Zadáme teda príslušný SQL dotaz, ktorý vráti všetkých zamestnancov, ktorým začína rodné číslo číslicou nula:
SELECT * FROM zamestnanci WHERE rodne_cislo LIKE ‚0%‘
Opäť, nevráti to žiadny riadok. Takže začneme postupne skúšať číslice od 1 po 9, a pri číslici 6 to vráti tento výsledok:
Nevidíme síce rodné číslo, ale vďaka tomuto vieme, že začína číslicou 6. Možeme teda začať hádať druhú číslicu, rovnakým spôsobom – dáme si vrátiť zamestnancov, ktorých prvá číslica rodného čísla je 6 a druhá 0:
SELECT * FROM zamestnanci WHERE rodne_cislo LIKE ‚60%‘
Znova to nevráti nič, tak na pozícii 2 znova budeme skúšať ostatné číslice. A pri niektorej z nich to vráti riadok s Chuckom Norrisom. A takto budete postupovať s ďalšou a ďalšou pozíciou, až sa postupne dopracujete k celému rodnému číslu. Náročnosť je max. 10×10 = 100 krokov, čo sa dá zvládnuť aj ručne za pár minút.
Ak by ste ale mali hádať z väčšej množiny znakov, napr. ak by ste nevideli mená zamestnancov, tak to bude trochu náročnejšie. Konkrétne 40x2xN krokov, kde 40 je približný počet znakov v slovenskej abecede, 2x za veľké/malé znaky, a N za predpokladanú dĺžku hľadaného reťazca. Pri hľadanom reťazci dĺžky 10 znakov je to max. 800 krokov, čo sa zdá ako vysoké číslo, ale pomocou makra v Exceli to zautomatizujete za 10 minút. Alebo, ak si trúfate, tak aj pomocou Power Query či Power BI, napr. pomocou cyklov ako v tomto článku. Prácnosť tiež okolo 10-15 minút, plus pár minút čakania na to kým sa to dokončí. A zdanlivo nemožné je za chvíľu prekonané. Pre hádanie veľkých objemov dát sa dá táto metóda ešte výrazne skrátiť, tiež napr. metódou delenia intervalov.
A ako to naozaj zabezpečiť?
To závisí od konkrétnej databázy, ktorú používate. V SQL Serveri sa na to dá použiť zabezpečenie na úrovni stĺpcov tabuliek, šifrovanie dát, či logon triggre. Čiže skutočné zabezpečovacie mechanizmy. Lebo až keď sa k tým hodnotám naozaj nedostane daný užívateľ, ani priamo ani nepriamo, tak až vtedy si môžete byť istí, že sú dáta bezpečné. Ale na dynamické maskovanie dát sa nespoliehajte. Napriek tomu, že patrí medzi bezpečnostnú funkcionalitu, tak nejde o plnohodnotné zabezpečenie dát. Ide len o rýchle, čiastkové riešenie problému. Ktoré sa dá bez aplikovania ostatných zabezpečovacích mechanizmov veľmi jednoducho obísť.
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.