Power Query v Power BI aj Exceli majú jednu zaujímavú funkcionalitu, nazvanú Query Folding. Ide o posúvanie niektorých operácií z Power Query do dátového zdroja, a ich vykonanie tam namiesto v Power Query. To vám vie rapídne urýchliť načítanie dát do Excelu aj Power BI, a ušetriť množstvo čakania aj operačnej pamäte počítača. Preto sa na to teraz pozrieme.
Query Folding je jedna z funkcionalít, o ktorej väčšinou ľudia nevedia, ale Power Query ju automaticky používa, keď to uzná za vhodné. Jej výhodou je to, že niektoré náročné operácie, ako zoskupovanie, spájanie či filtrovanie dát, ktoré si užívateľ nakliká v Power Query, sa vykonávajú nie v Power Query, ale priamo v dátovom zdroji. Čiže v databáze, ktorá vie zvyčajne takéto operácie vykonať oveľa rýchlejšie ako Power Query. Musia však byť na to splnené hneď viaceré podmienky.
Táto funkcionalita je tam dostupná už hneď od prvej verzie Power Query. Problém však je ten, že existuje len veľmi chabá oficiálna dokumentácia k tejto funkcionalite. Ďalším zdrojom sú drobné informácie roztrúsené po internete, a vlastné experimenty na dátach. A táto funkcionalita sa časom mierne rozširuje, tak ako všetko ostatné v Power BI. Preto tento súhrn berte iba orientačne, a vyskúšajte si sami, ako to funguje na vašom prostredí.
Query folding je podporovaný len pri niektorých typoch dátových zdrojov, a aj to v každom inak:
- Databázové zdroje – SQL Server, Oracle, … (podporujú najviac operácií),
- OData a z neho odvodené zdroje – napr. čisté OData, Zoznamy SharePoint, Azure Marketplace,
- Active Directory,
- Exchange,
- HDFS, Folder.Files, Folder.Contents a SharePoint.Files (iba základné operácie nad cestami v adresárovej štruktúre),
- SSAS Tabular a Azure Analysis Services.
Medzi podporované operácie patria:
- Filtrovanie riadkov a stĺpcov,
- Zlučovanie tabuliek (merge queries / joiny a antijoiny) a pripájanie tabuliek (append queries / union all) – iba ak sú obe tabuľky z toho istého dátového zdroja,
- Zoskupovanie tabuliek a sumarizovanie stĺpcov (group by),
- Zoraďovanie riadkov (order by),
- Výber/ponechanie prvých N riadkov,
- Operácie „Kontingenčný stĺpec“ a „Zrušiť kontingenčnosť stĺpcov“ (pivot a unpivot),
- Číselné výpočty,
- Zmena dátového typu stĺpca (cast, convert, …),
- Premenovanie stĺpcov (sql alias),
- Jednoduché transformácie, ako napr. UPPER (prevod všetkých písmen v texte na veľké písmená).
A ako to celé funguje?
Zoberme si vzorovú databázu AdventureWorksDW na SQL Serveri. Dáme si odtiaľ načítať tabuľku internetových objednávok – tabuľku FactInternetSales. Potom si otvoríme príslušný dotaz v Power Query, a bude to vyzerať takto:
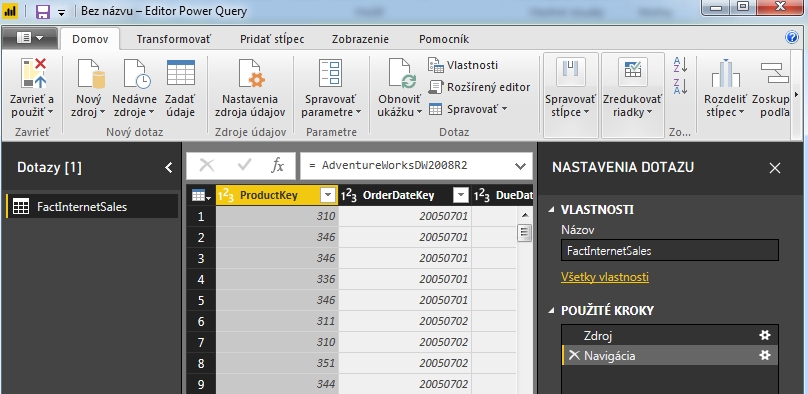
Teraz si dáme dáta zoskupiť, napr. podľa stĺpca SalesTerritoryKey. Pridáme teda transformáciu „Zoskupiť podľa“:
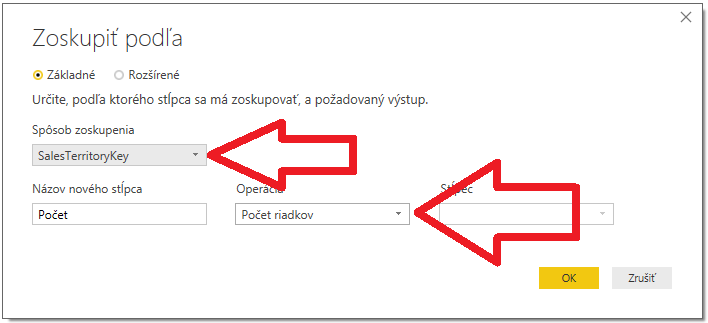
…a potom dáme údaje zoradiť podľa stĺpca SalesTerritoryKey. To nám pridá do zoznamu operácií podľa očakávania 2 operácie:
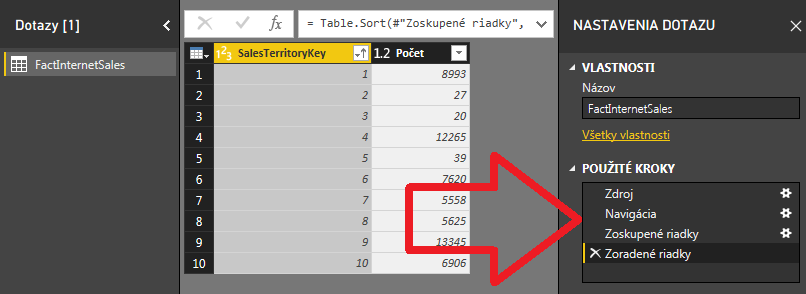
A ako teraz vieme, či sa tieto 2 operácie vykonali v Power Query, alebo na strane databázového servera?
Riešenie je jednoduché – pozrieme si to priamo v zozname operácií. Keď kliknete pravým tlačítkom na poslednú operáciu nazvanú „Zoradené riadky“, tak sa zobrazí takáto ponuka:
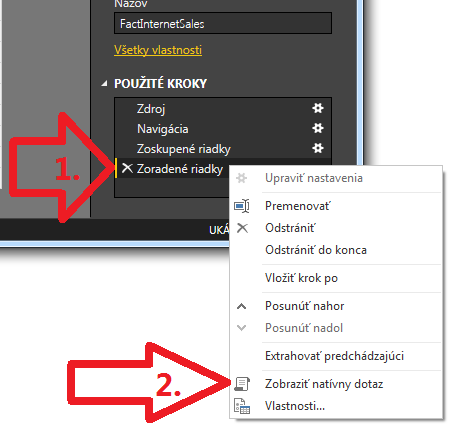
A ak máte povolenú položku „Zobraziť natívny dotaz“, tak až po túto operáciu funguje Query Folding – čiže posúvanie operácií z Power Query na vykonanie do databázy. Ak táto položka povolená nie je, tak Query Folding nie je podporovaný pre túto operáciu.
Aby ste zistili, pre ktorú podporovaný je, resp. po ktorú to funguje, tak choďte postupne od poslednej operácie po prvú, a tá, pri ktorej to bude povolené, je podporovaná, a tá nasledujúca za ňou, pri ktorej je to zakázané, už podporovaná nie je. Takto si viete postupne zistiť, ktoré operácie sú a ktoré nie sú podporované vo vašej verzii Power Query, či už Exceli, v Power BI Desktope, alebo v SSAS Tabulare 2017 a novšom.
Po kliknutí na položku „Zobraziť natívny dotaz“ si môžete pozrieť, aký SQL dotaz sa posiela do databázy:
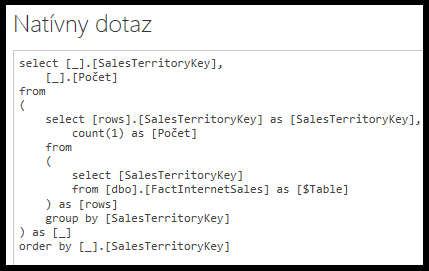
Tam si všimnite, že operácia zoskupenia sa vykonáva v jazyku SQL ako klauzula GROUP BY, a operácia zoradenia ako klauzula ORDER BY.
Ak sa však niektorá z nasledujúcich operácií tvári, že nie je podporovaná, tak to neznamená, že nie je podporovaná. Je možné, že je pred ňou v poradí iba niektorá z operácií, ktorá podporovaná nie je. Pretože pre Query Folding platí podmienka, že funguje len po prvú operáciu, ktorá nie je podporovaná. Čiže ak nie je podporovaná niektorá z operácií, a za ňou nasledujú podporované operácie, tak tie už nebudú kvôli tej jednej predchádzajúcej nepodporovanej zahrnuté do funkcie Query Folding. A vykonajú sa namiesto toho v Power Query. Ktoré zrovna nie je rýchle na väčšom množstve dát.
Čiže ak napr. pridáme do nášho postupu operácie „Nahradiť hodnoty“, a nahradíme v prvom stĺpci povedzme hodnotu 5 za hodnotu 20, tak toto je nepodporovaná operácia pre SQL Server. Preto sa táto operácia vykoná už v Power Query, a všetky predchádzajúce ešte v databáze SQL Servera. Keď potom pridáme operáciu filtrovania riadkov, ktorá patrí medzi podporované operácie pre Query Folding, tak tá sa už aj napriek tomu vykoná v Power Query. Pretože pred ňou bola nepodporovaná operácia, a teda všetky nasledujúce operácie sa tiež vykonajú v Power Query. Po kliknutí pravým tlačidlom na poslednú operáciu bude menu vyzerať takto:
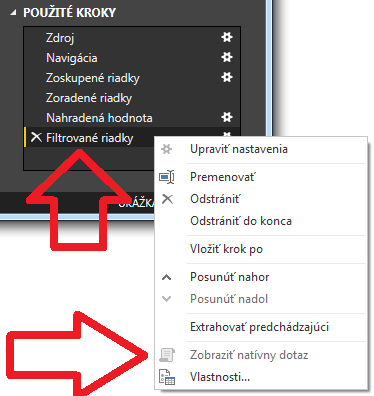
Všimnite si, že položka menu „Zobraziť natívny dotaz“ je teraz zakázaná. A teda Query Folding v tomto prípade už neposúva operáciu do databázy, ale vykonáva ju Power Query. Ak to chcete optimalizovať, tak riešením je presunúť podporované operácie na začiatok, tak aby ich za sebou od začiatku nasledovalo za sebou čím viac. Jednoducho preto, aby čím viac práce spravila databáza, ktorá je zvyčajne neporovnateľne rýchlejšia ako Power Query. Lebo to vyniká iba možnosťami transformácií dát, ale výkon je relatívne pomalý. A po týchto podporovaných operáciách zaradiť všetky ostatné operácie. Tak sa vám do Excelu či Power BI Desktopu načítajú údaje oveľa rýchlejšie. Prípadne potom ešte nie je od veci zoptimalizovať výkon na strane databázy pridaním indexov, indexovaných/materializovaných pohľadov, či pomocou columnstore indexov (ktoré mimochodom tiež využívajú technológiu PowerPivotu).
A kedy ešte nefunguje Query Folding?
Nefunguje samozrejme vtedy, keď používate nepodporovaný dátový zdroj (napr. Excel, súbory CSV). A najmä nefunguje vtedy, keď sa rozhodnete ako zdroj dát vybrať síce niektorý z podporovaných zdrojov – napr. SQL Server – ale namiesto výberu tabuľky si napíšete dotaz sami. V tomto prípade sa Query Folding úplne vypne pre ten celý dotaz Power Query, a žiadna operácia ho nebude využívať. Preto si otestujte, najmä pri používaní databáz, obe možnosti – napísanie dotazu cez jazyk SQL, aj naklikanie výsledku v Power Query. Ak ste použili iba niektoré z hore uvedených operácií, tak medzi tým pravdepodobne nebude rozdiel. A teda vo väčšine prípadov ani nemusíte písať ručne SQL dotazy. Pretože to Power Query vďaka funkcii Query Folding spraví automaticky za vás. V ostatných prípadoch si overte obe možnosti, a vyberte si tú rýchlejšiu.
A čo znamená „oveľa rýchlejšie“ na väčšom množstve údajov?
Spravil som jednoduchý test. Zobral som databázku na SQL Serveri so 7 miliónmi riadkov a cca. 100 stĺpcami. Dal som ju načítať do Power Query, a následne dal zoskupiť podľa jedného zo stĺpcov, v ktorom bolo okolo 10 jedinečných hodnôt. Tabuľka v databáze zaberala približne 8 GB. Táto operácia trvala s Query Foldingom cca. 3-5 sekúnd, a nespotrebovala takmer žiadnu pamäť. Keď som to však vyskúšal s vypnutým Query Foldingom – tak že som dal naimportovať dáta z dotazu „SELECT * FROM tabulka“, a potom dal v Power Query zoskupenie rovnako ako v predošlom prípade, tak zobrazenie výsledku v editore Power Query trvalo okolo 10 minút, a spotrebovalo to 34 GB operačnej pamäte (!). Následné načítanie do Power BI Desktopu trvalo „iba“ 5 minút, a spotrebovalo 4+1 GB pamäte (PQ UI vlákno + PQ worker vlákno). Mohol som samozrejme napísať do toho dotazu rovno klauzulu GROUP BY a dostal by som rovnaký výsledok. Ale chcel som, aby ste videli, aký rozdiel spraví zapnutý vs. vypnutý Query Folding. Nehovoriac o tom, že som zbytočne zabil čas písaním dotazu, keď dotaz z rovnakým výsledkom za mňa „naklikalo“ Power Query.
Skúšal som to aj s tabuľkou z SQL Servera s veľkosťou 250 GB a cca. 1,3 miliardami riadkov, s indexom nad daným zoskupovaným stĺpcom. Keď bol zapnutý Query Folding, tak to zbehlo za pár sekúnd. Keď bol vypnutý, tak na mojom desktope so 64 GB RAM to po niekoľkých minútach spadlo na nedostatok pamäte. Takže asi tak…
Na záver
Takto teda funguje Query Folding v Power Query – či už je to v Exceli, v Power BI Desktope či v SSAS Tabulare 2017 a novších. Na prvý pohľad sa to zdá ako mágia, ale po troche praxe sa v tom časom ľahko zorientujete. Podstatné je zapamätať si, že ak pracujete s databázami, a ťaháte malé objemy dát ako výsledok z veľkej kopy dát, tak je dobré dať čo najviac z podporovaných operácií na začiatok, a až po nich všetky ostatné. Tak by sa vám mohli načítať údaje oveľa rýchlejšie.
Na záver ešte pocta človeku, ktorý si s tým spravil prácu, a zosumarizoval snáď najviac informácií o ňom z celého internetu. Volá sa Koen Verbeeck a z jeho článku som čiastočne čerpal aj ja:
https://www.mssqltips.com/sqlservertip/3635/query-folding-in-power-query-to-improve-performance/
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.