Ako sme spomínali v prechádzajúcom článku, kategórie sa dajú vytvárať nielen podľa “surových” dát, ale aj podľa dát, ktoré si vieme dopočítať z, alebo pomocou iných tabuliek v našom dátovom modeli. A to následne ponúka ďalšie, veľmi zaujímavé možnosti, ktorým sa budeme venovať v tomto článku.
Povedzme, že by sme chceli analyzovať produkty, a vytvoriť z nich 3 kategórie podľa ich predajnosti:
- kategóriu najpredávanejšie, kde budú produkty s obratom nad 1 milión dolárov, resp. eur,
- kategóriu priemerne predávané, kde budú produkty s obratom od 100 tisíc do 1 milióna dolárov,
- kategóriu slabo predávané, kde budú produkt s obratom pod 100 tisíc dolárov.
Toto vieme spraviť pomocou dvoch vypočítaných stĺpcov v tabuľke Produkty. Najprv si do prvého vypočítaného stĺpca vypočítame obrat za daný produkt, a potom v ďalšom stĺpci vytvoríme naše 3 kategórie podľa definície vyššie.
Presuňte sa teda do okna PowerPivotu, do tabuľky Produkty, do posledného stĺpca (nazvaného, ako vždy, Pridať stĺpec). V tomto stĺpci zadajte nasledujúci vzorec:
=SUMX(RELATEDTABLE(‚Objednávky‘); ‚Objednávky'[Cena objednávky])
Tento vzorec nám vypočíta pre každý produkt sumu cien objednávok, v ktorých bol objednaný. Premenujte tento stĺpec na „Obrat za produkt„. Ak nevidíte žiadne údaje v tomto stĺpci, je to preto, že len niektoré produkty sú priradené k objednávkam, resp. len niektoré z produktov sa predávali v celej histórii firmy. Pre kontrolu sa presuňte povedzme na riadok 300 (využite navigáciu v ľavom dolnom rohu PowerPivotu), a mali by ste vidieť vypočítané obraty aspoň pri niektorých produktoch, ako na tomto obrázku:
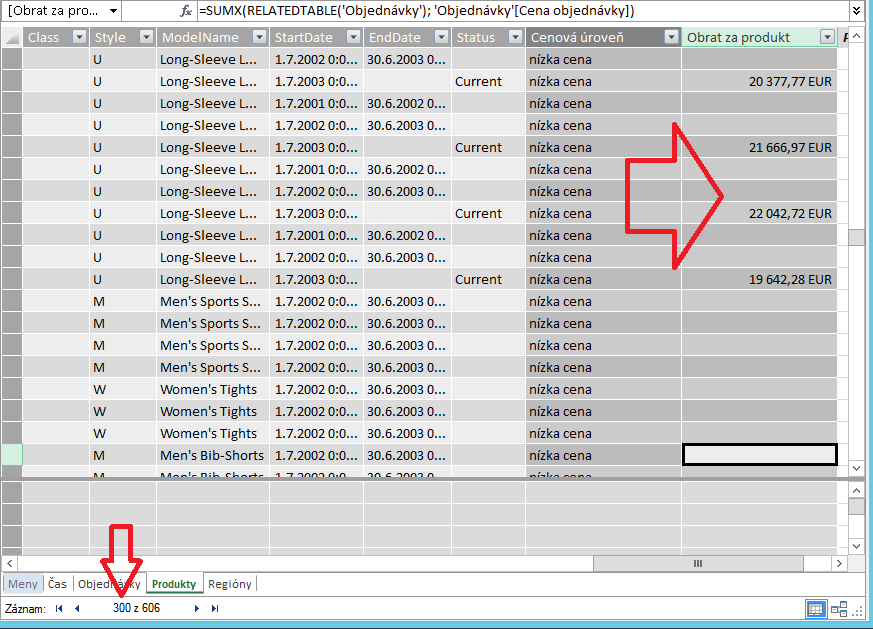
A ako to funguje? Je to celkom jednoduché. Používame tieto 2 funkcie:
- RELATEDTABLE – dotiahne k aktuálne počítanému riadku všetky príslušné riadky zo zadanej tabuľky (podľa prepojení v dátovom modeli), a vráti tieto riadky ako tabuľku,
- SUMX – má syntax SUMX(tabuľka; výraz), a robí to, že v zadanej tabuľke spočíta sumu z výrazu, ktorý vyhodnotí zvlášť pre každý riadok tejto tabuľky.
Takže keď zadáme tento vzorec do vypočítaného stĺpca v tabuľke Produkty, tak PowerPivot vypočíta tento vzorec pre každý riadok tabuľky Produkty osobitne, a výsledok uloží k danému produktu do príslušnej bunky vo vypočítanom stĺpci.
Čiže pre každý produkt spraví nasledovné:
- pomocou funkcie RELATEDTABLE(‚Objednávky‘) zistí, ktoré objednávky (riadky z tabuľky Objednávky) patria k danému produktu. Tieto riadky vráti ako tabuľku,
- výsledok z bodu 1 dáme na vstup funkcii SUMX do jej prvého parametra, a do druhého parametra dáme stĺpec „Cena objednávky“ z tabuľky Objednávky. A keďže ten stĺpec nie je z našej aktuálnej tabuľky Produkty, musíme ho uviesť aj s menom jeho tabuľky v tvare ‚Objednávky'[Cena objednávky]. Funkcia SUMX následne pre každý riadok zadanej tabuľky vyhodnotí výraz z jej druhého parametra (v našom prípade je tam len stĺpec „Cena objednávky“), a potom spraví súčet všetkých hodnôt z toho výrazu zo všetkých riadkov. Čo v našom zjednodušenom prípade znamená, že spraví súčet cien objednávok z tej tabuľky – ktorá, ako už vieme, obsahuje všetky príslušné objednávky k aktuálne počítanému produktu.
Takže takto vypočítame obrat pre každý produkt a uložíme ho do stĺpca „Obrat za produkt“.
Potom si vytvoríme ďalší vypočítaný stĺpec, kde nám bude vstupom stĺpec „Obrat za produkt„. A podľa definície na začiatku tohto článku v ňom vytvoríme želané kategórie. Vzorec pre tento stĺpec bude takýto (vzorec je rozpísaný na viacero riadkov kvôli čitateľnosti):
=
IF (
[Obrat za produkt] > 1000000;
„najpredávanejšie“;
IF ( [Obrat za produkt] > 100000; „priemerne predávané“; „slabo predávané“ )
)
Názov stĺpca premenujeme na Predajnosť, a výsledok bude vyzerať takto v PowerPivote:
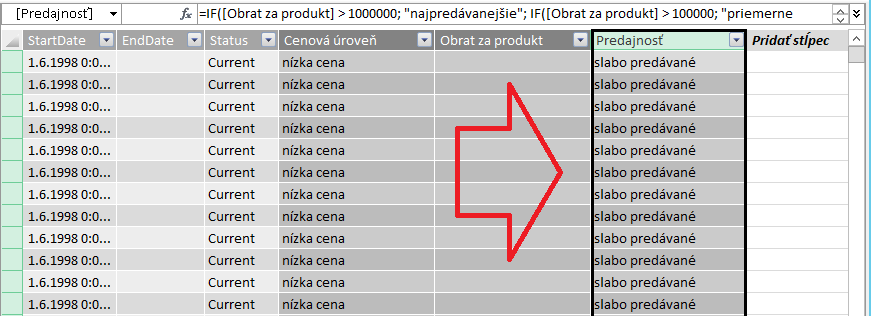
…a takto, keď stĺpec použijeme v kontingenčke:

A aby bolo riešenie dokonalé, tak v PowerPivote skryte stĺpec „Obrat za produkt“ z ponuky kontingenčky, lebo takýto stĺpec nemá pre užívateľa v kontingenčke využiteľnosť.
Toto je pritom len ukážka niektorých vecí, v ktorých tkvie sila PowerPivotu v porovnaní s bežnou excelovskou kontingenčkou. Podobným spôsobom si viete dotiahnuť dáta z jednej tabuľky do hociktorej inej tabuľky, nad nimi spraviť požadovaný výpočet, a potom, ako napríklad v našom príklade, zaradiť príslušný riadok do príslušnej kategórie. Z dlhodobého hľadiska to má ešte jednu nezanedbateľnú výhodu – produkty budú zaradené v správnej kategórii, aj keď dáme aktualizovať dáta v dátovom modeli. Pretože po aktualizácii dát sa vždy okamžite prepočítajú všetky vzorce v PowerPivote, čiže aj naše zaradenie do kategórií, podľa aktuálnych dát. A takúto flexibilitu a konzistentnosť možno očakávať od klasickej kontingenčky bez PowerPivotu len veľmi ťažko. Čo nás odteraz už trápiť nemusí, keď vieme, ako to spraviť v PowerPivote 😉
Takto teda viete využiť vypočítané stĺpce na vytvorenie vlastných analytických kategórií, a elegantnejšie analyzovať dáta. Týmto sa však ich využitie nekončí. Pomocou nich môžeme napr. opravovať chyby v dátach. A to si pozrieme v ďalšom článku 😉
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.
Pri výpočet SUMX(RELATEDTABLE(‘Objednávky’); ‘Objednávky'[Cena objednávky]) v Power Pivote hlási neočakávanú chybu „xquery.cpp, riadok 13960,XMVSX Join::Build Relationships“. Kde môže byť problém?
Chyba je v inštalácii Vášho Excelu/Officu. Chybu zvyčajne vyrieši preinštalovanie alebo oprava Officu, návrat na niektorú z predchádzajúcich aktualizácií Officu, alebo počkanie na to, že to snáď ďalšia aktualizácia Officu opraví.