V predchádzajúcom článku som sa venoval vcelku jednoduchému problému, ako zobraziť TOP N položiek, a ako zvyšné položky zoskupiť do položky „ostatné“. Malo to však jednu chybičku krásy – nereagovalo to na vybrané filtre a slicery kontingenčky. Dnes si ukážeme, ako tento problém vyriešiť pomocou výpočtu dynamických TOP N položiek v DAXe.
Predchádzajúce riešenie malo nevýhodu v tom, že používalo vypočítané stĺpce na oskórovanie záznamov. Následné výpočty boli potom založené na tomto stĺpci, a keď ste náhodou pridali do kontingenčky slicery alebo klasické filtre, tak nemali vplyv na daný výpočet, lebo na to vypočítané stĺpce nereagujú. Riešením je v tomto prípade spraviť výpočet dynamických TOP N položiek pomocou merítok, ktoré reagujú na všetky typy filtrov.
Začneme tým, že si vyskladáme nasledovnú kontingenčku z nášho vzorového súboru PowerPivotu, ktorá zobrazí obrat podľa produktu:
1) do oblasti hodnôt dáme merítko Obrat z tabuľky Objednávky,
2) do oblasti riadkov dáme stĺpec ProductName z tabuľky Produkty,
3) vytvoríme slicer zo stĺpca CalendarYear z tabuľky Čas,
4) kontingenčku zotriedime podľa „stĺpca“ s Obratom od najväčšej po najmenšiu hodnotu.
Výsledná kontingenčka bude vyzerať takto:
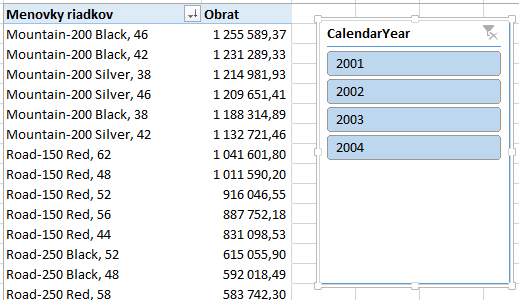
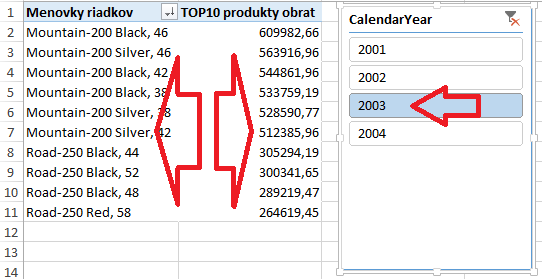
V tejto kontingenčke chceme zobraziť vždy iba TOP 10 produktov s najvyšším obratom, ale tak, aby to bralo do úvahy aj výber v sliceri aj prípadné ďalšie filtre kontingenčky. Takže ak v našom sliceri klikneme na rok 2003, tak to zobrazí tieto položky:
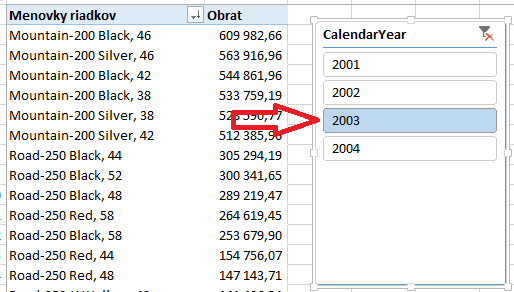
…a keď v ňom klikneme na rok 2004, tak zobrazí mierne odlišné položky, samozrejme pre vybraný rok:

A my by sme teraz chceli, aby to zobrazilo iba prvých 10 položiek v danom roku, resp. iba prvých 10 položiek z aktuálneho výberu užívateľa. Na to musíme spraviť postupne tieto 3 kroky:
1) vyrobiť merítko, do ktorého si vypočítame skóre predajnosti produktu podľa jeho obratu,
2) vyrobiť merítko, ktoré pre daný produkt zobrazí jeho Obrat iba vtedy, keď skóre v merítku 1) je menšie alebo rovné 10 (čiže ak daný produkt patrí medzi TOP10 produkty),
3) nahradiť merítko Obrat v kontingenčke merítkom z bodu 2), a zotriediť kontingenčku podľa tohto „stĺpca“.
Pre prvý krok si vytvoríme merítko „Skóre TOP10 produktu“ s týmto vzorcom, ktoré nám bude vracať skóre predajnosti produktu podľa jeho obratu:
Skóre TOP10 produktu:=RANKX(SUMMARIZE(ALL(Produkty); Produkty[ProductName]; „Obrat za rovnaky produkt“; [Obrat]); [Obrat za rovnaky produkt]; [Obrat])
Alebo naformátované takto:

Postup výpočtu je taký, že si potrebujeme funkciou RANKX oskórovať produkty podľa ich obratov. Takže najprv použijeme funkciu ALL na odstránenie filtrov nad tabuľkou Produkty, aby sme získali celú tabuľku do výpočtu skórovania. Problém je ale v tom, že niektoré názvy produktov sa tam opakujú, a kontingenčka ich združí do 1 riadku tak isto ako všetky opakujúce sa hodnoty. Takže musíme tomu prispôsobiť aj náš výpočet. Pred oskórovaním si tabuľku Produkty zoskupíme pomocou funkcie SUMMARIZE podľa názvu produktu, a pre každý zoskupený produkt dáme do nového stĺpca „Obrat za rovnaky produkt“ vypočítať jeho Obrat. Následne dáme jednoducho oskórovať takúto tabuľku produktov funkciou RANKX, kde prvý parameter je tabuľka so všetkými skórovanými záznamami, a druhý parameter je skórovací stĺpec, voči ktorému sa počíta skóre hodnoty zadanej v treťom parametri tejto funkcie. Po pridaní takéhoto merítka do kontingenčky bude medzivýsledok vyzerať takto:
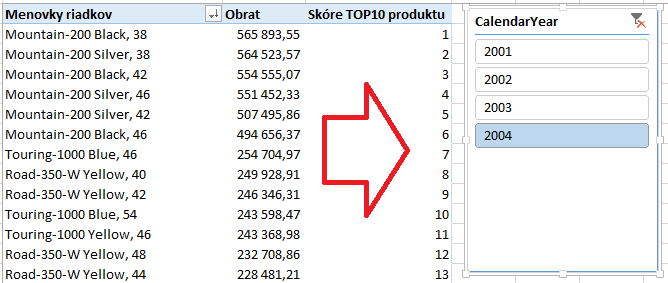
Na základe tohto prejdeme k druhému kroku, v ktorom vytvoríme merítko s názvom „TOP10 produkt obrat„:
TOP10 produkty obrat:=IF(HASONEVALUE(Produkty[ProductName]) && [Skóre TOP10 produktu] <= 10; [Obrat]; BLANK())
Toto merítko sa bude počítať len vtedy, keď je na riadkoch kontingenčky vybraný iba 1 produkt (to je okrem iného účel funkcie HASONEVALUE), a zároveň daný produkt má skóre podľa predchádzajúceho merítka menšie alebo rovné 10. Ak je väčšie ako 10 (a teda produkt nepatrí medzi TOP 10 produktov), tak toto merítko vráti prázdnu hodnotu. A týmto merítkom docielime to, aby po pridaní do kontingenčky a odstránení ostatných polí okrem názvu produktu kontingenčka skryla prázdne riadky, a zobrazila len TOP10 produkty:
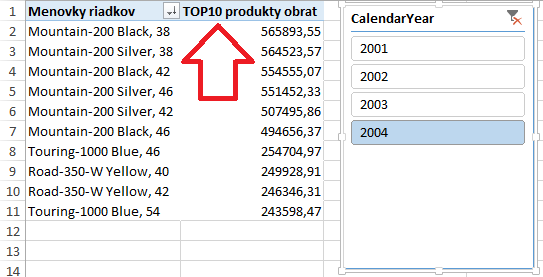
Takže takto, relatívne jednoducho, vieme zobraziť dynamických TOP N položiek v kontingenčke. Nakoniec dáme ešte zoradiť kontingenčku podľa posledného stĺpca, a dielo je dokonalé 🙂 Pekné na tom je to, že keď si teraz vyskúšate filtrovanie pomocou slicera, tak výpočet ho bude brať do úvahy, a pre iný rok zobrazí iné (a dokonca správne) čísla:
Pre dokonalosť je ešte potrebné spomenúť, že vo väčšine prípadov budú položky v sliceri mierne svetlejšie alebo zašedenejšie ako predtým. Je to spôsobené tým, že Excel takto vyfarbuje položky slicerov, o ktorých si myslí, že pre ne neexistujú dáta. Ak Vám to vadí, tak to vypnete v nastaveniach slicera (pravý klik na nadpis slicera -> Nastavenie rýchleho filtra -> odkliknúť Skryť položky neobsahujúce údaje -> OK).
A ako zobraziť položku „ostatné“, kde budú zoskupené predaje za všetky ostatné produkty, tak ako v predchádzajúcom článku? To si povieme v nasledujúcom článku 🙂 Dovtedy si skúste prejsť a pochopiť tento postup, aby ste vedeli, ako zobraziť dynamických TOP N položiek v kontingenčke. Pretože tento trik sa dosť často používa v pokročilej analytike, a po malých úpravách sa dá spraviť veľmi jednoducho aj to, aby aj tá desiatka vo vzorci s TOP10 bola dynamická, a aby si ju mohol užívateľ sám zmeniť bez zásahu do DAXového vzorca. Ale o tom snáď niekedy inokedy 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.
Pri komplikovanejších dátach to celkom nefunguje – zoradí to síce správne, ale TOPX vygeneruje čísla z celého výberu, ak niektoré položky chýbajú vo vybranom období, potom nejdú v poradí za sebou. Funguje to lepšie, ak ALL(Produkty) nahradíme ALLEXCEPT(Produkty;Produkty[CalendarYear]).
Inými slovami, ak rešpektujeme filter 🙂
Vďaka za postreh. Nie je mi síce úplne jasné, čo je to za stĺpec Produkty[CalendarYear], ale ak tam máte taký stĺpec, a je to ten stĺpec, podľa ktorého ste si vyrobili slicer, tak áno, je to ešte lepšie riešenie 😉
Tak a tu je zopár vzorcov na 80/20 (som si dovolil vymyslieť)
Skore Top10 produktu som si dovolil premenovať na Poradie, tu je trochu zmodifikovaný vzorec:
Poradie:=RANKX(SUMMARIZE(ALLEXCEPT(Produkty;Produkty[CalendarYear]); Produkty[ProductName]; “Obrat za rovnaky produkt”; [Obrat]); [Obrat za rovnaky produkt]; [Obrat])
Potom kumulované obraty:
KO = SUMX(TOPN([Poradie];SUMMARIZE(ALLEXCEPT(Produkty;Produkty[CalendarYear]);Produkty[ProductName];“Obrat za rovnaky produkt“;[Obrat]);[Obrat za rovnaky produkt]);[Obrat za rovnaky produkt])
A samozrejme kumulované %:
KO % = [KO]/SUMX(SUMMARIZE(ALLEXCEPT(Produkty;Produkty[CalendarYear]); Produkty[ProductName]; “Obrat za rovnaky produkt”; [Obrat]);[Obrat za rovnaky produkt])
A nakoniec orezanie na 80%:
80% produkty obrat:=IF(HASONEVALUE(Produkty[ProductName]) && [KO %] <= 0,8; [Obrat]; BLANK())
A to je všetko 🙂 Na dnes
Ospravedlňujem sa, vo Vašom príklade je to Čas[CalendarYear] 🙂