Už v niekoľkých článkoch sme sa venovali funkcii TOPN, ktorá vráti prvých N riadkov z tabuľky. A vo väčšine prípadov funguje ako očakávate. Niekedy však vráti tých riadkov viac. A ak si na to nedáte pozor, tak môžete mať zlé analýzy a nevedieť o tom. Preto sa teraz pozrieme na to, kedy sa to stáva, a ako z toho von.
Funkcia TOPN má takúto syntax:
TOPN(n; tabuľka; zoradiťPodľa; smerTriedenia, …)
Táto funkcia vracia zo zadanej tabuľky prvých N riadkov, kde riadky v pôvodnej tabuľke sa ešte predtým zoradia podľa 3. a 4. parametra. Výsledok je vrátený ako tabuľka. Poradie riadkov vo výsledku nie je garantované.
Táto funkcia sa dosť často využíva na zistenie štatistiky za najlepších N záznamov či entít v skupine, tak ako sme to mali už v tomto článku. Niekedy však dostanete mierne odlišné výsledky, ako by ste čakali. A oficiálna dokumentácia k tejto funkcii to tiež spomína iba jednou suchou vetou, aj keď podľa mňa by to tam malo byť veľkými červenými písmenami.
Vysvetlíme si to na príklade, kde znova použijeme náš vzorový súbor PowerPivotu, resp. Power BI.
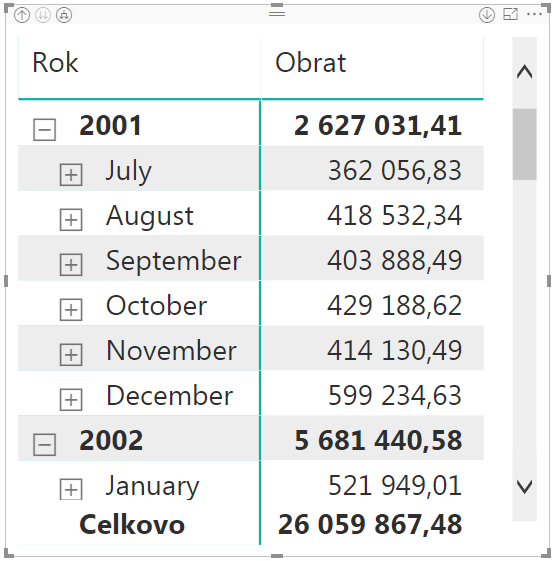
Najprv si vytvoríme kontingenčku, kde:
- na riadkoch bude hierarchia Rok-Mesiac-Deň z tabuľky Čas, rozkliknutá na úroveň mesiacov,
- v oblasti hodnôt bude merítko Obrat z tabuľky Objednávky.
Kontingenčka bude vyzerať takto:
A my by sme teraz chceli porovnať Obrat v danom období voči obratu za 3 najlepších zákazníkov v tom istom období. Na to si spravíme takéto pekné merítko (vypeknené cez DAX Formatter):
Obrat za TOP 3 zákazníkov =
SUMX (
TOPN (
3;
SUMMARIZE (
'Objednávky';
'Objednávky'[CustomerKey];
"Obrat za zákazníka"; [Obrat]
);
[Obrat za zákazníka]; DESC
);
[Obrat za zákazníka]
)
V tomto merítku si najprv zoberieme zoznam objednávok v aktuálnom kontexte výpočtu, a funkciou SUMMARIZE ich zosumarizujeme podľa stĺpca CustomerKey (číslo zákazníka) a ku každému zákazníkovi dopočítame jeho obrat do nového stĺpca „Obrat za zákazníka“. Z tejto tabuľky potom vyberieme funkciou TOPN prvých 3 zákazníkov, pričom funkcia TOPN ich pred výberom ešte zoradí od toho s najväčším po najmenší obrat. Tieto riadky potom zosumarizujeme funkciou SUMX cez stĺpec „Obrat za zákazníka“, a máme obrat za 3 najlepších zákazníkov v danom období, resp. v aktuálnom kontexte výpočtu. Výsledok po dosadení do kontingenčky vyzerá takto:
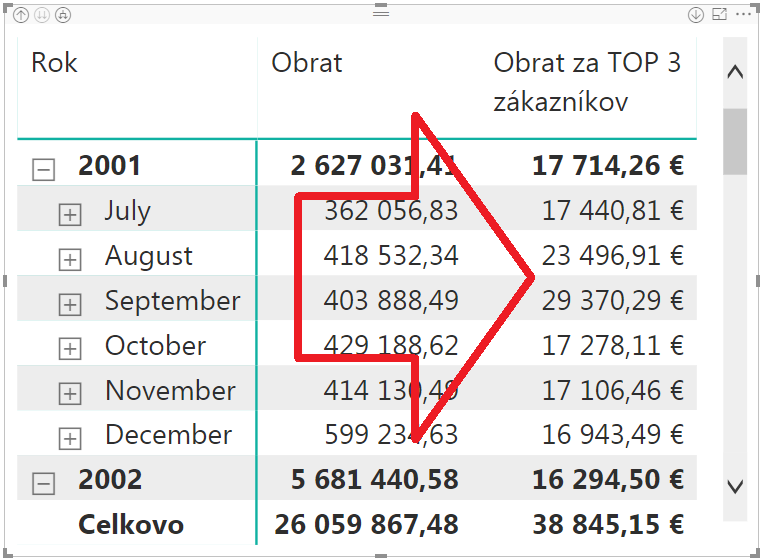
Na prvý pohľad to vyzerá správne. Všimnite si ale šípku na obrázku, a porovnajte obrat za TOP 3 zákazníkov v danom mesiaci s TOP3 obratom za príslušný rok. Vidíte, že napr. v septembri 2001 bol obrat za TOP 3 zákazníkov 29 370 eur, a v príslušnom roku 2001 bol ten istý obrat iba 17 714 eur. Pritom z logiky veci vyplýva, že obrat na ročnej úrovni by mal byť väčší alebo prinajhoršom rovný obratu na mesačnej úrovni. Tu je to naopak. Ideme teda pohľadať, v čom to je.
Pridáme si teda do kontingenčky ešte stĺpec CustomerKey z tabuľky Objednávky, ktorý obsahuje číslo zákazníka, a ktorý sme použili do nášho výpočtu. Po rozkliknutí mesiaca september 2001 na zákazníkov, a zoradení riadkov podľa TOP3 obratu od najväčšieho po najmenší, to bude vyzerať takto:
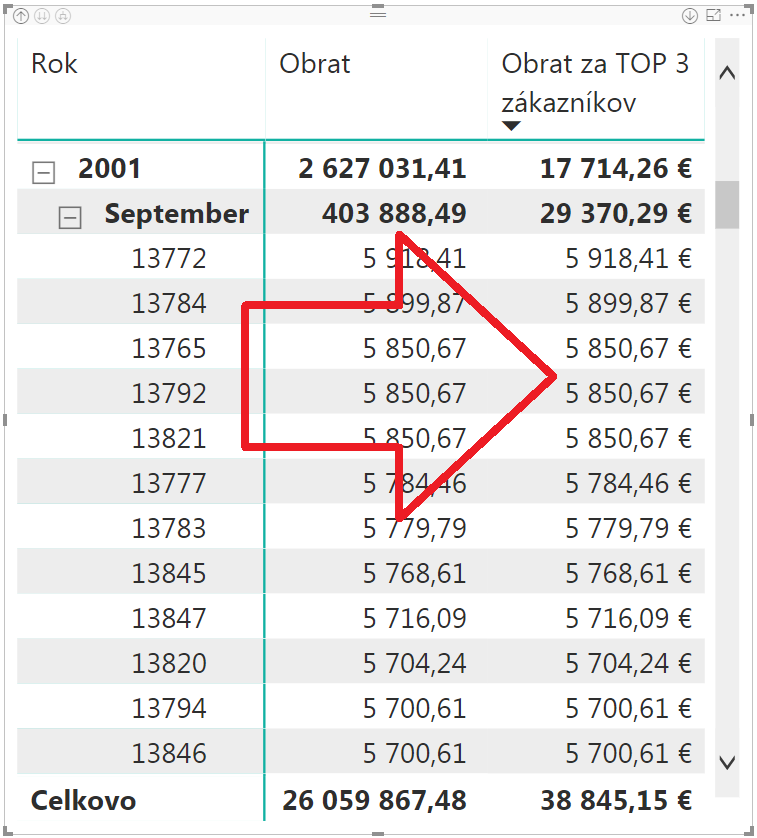
Keď si tam spočítate obraty za prvých 3 zákazníkov, tak vám vyjde 17 668,95 EUR, čo je podľa očakávania menšie ako príslušný TOP3 obrat na úrovni roka 2001. Naše merítko to ale pre ten mesiac vypočítalo ako 29 370 eur. Kde je zádrhel?
Problém je v tom, že funkcia TOPN nie je až tak priamočiara, ako to vyplýva z jej popisu. Technicky totiž funguje tak, že zoberie najprv riadky zo zadanej tabuľky, a zotriedi ich podľa 3. a 4. parametra. Potom tie riadky očísluje postupne od 1 po X, a vyberie z nich všetky riadky, ktoré majú toto číslo menšie alebo rovné hodnote N, ktorú ste zadali do prvého parametra tejto funkcie.
A problém je práve v tom číslovaní riadkov. Ak by boli hodnoty v stĺpci „Obrat za zákazníka“, podľa ktorého číslujeme, rôzne pre každý riadok, a mali by sme v tej tabuľke povedzme 50 riadkov, tak by ich funkcia TOPN očíslovala od 1 do 50. Ak sa však niektoré hodnoty pod sebou opakujú, tak funkcia TOPN ich očísluje rovnakým poradovým číslom. A na ďalších riadkoch pokračuje ďalším číslom v poradí (nepreskakuje poradie ako napr. funkcia RANK.EQ).
Keď sa teraz pozriete na ten obrázok, tak si všimnite, že hodnoty pri 3., 4. a 5. zákazníkovi sú rovnaké – 5 850,67 eur. Čiže keď ide funkcia TOPN cez takúto tabuľku, tak riadok s hodnotou 5 918, 41 eur bude očíslovaný poradovým číslom 1, riadok pod ním s hodnotou 5 899, 87 eur dostane poradové číslo 2, a ďalšie 3 riadky s hodnotou 5 850,67 eur dostanú rovnaké poradové číslo 3. Keď z takejto tabuľky dáme vrátiť prvé 3 riadky, tak podľa popisu fungovania vyššie to v skutočnosti vráti všetky riadky, kde to poradové číslo je od 1 do 3. Čiže vráti z tej tabuľky prvých 5 riadkov. Ich následným zosumovaním nám vyjde oných 29 370,29 eur.
Takže z pohľadu jazyka DAX sa to počíta správne, ale z nášho pohľadu sa to počíta nesprávne. Lebo sme chceli vypočítať obrat za 3 najlepších zákazníkov v danom období, a nie obrat za zákazníkov s 3 najväčšími obratmi v danom období. Opravíme to jednoducho. Funkcia TOPN totižto umožňuje zoraďovať riadky pred výpočtom nielen podľa jedného zoraďovacieho stĺpca, ale aj podľa viacerých stĺpcov. A tie ďalšie zoraďovacie stĺpce sa používajú rovnako ako v Exceli na to, že keď prvotné zoradenie nie je dostatočné a zoraďované hodnoty sa opakujú, tak sa v rámci tých skupín spraví druhotné zoradenie podľa ďalšieho zadaného stĺpca. A ak ste ich zadali viac, tak postupne zoraďuje v podskupinách a podpodskupinách podľa tých ďalších stĺpcov.
To využijeme aj my, a povieme funkcii TOPN, že má síce zoradiť tie riadky podľa stĺpca „Obrat za zákazníka“ od najväčšej hodnoty po najmenšiu, ale ak nájde rovnaké obraty, tak nech ich ešte dodatočne zoradí podľa stĺpca CustomerKey od najmenšieho po najväčší. Pri tomto stĺpci smer triedenia v tomto prípade nie je až tak podstatný. Avšak vďaka tomu, že v tomto stĺpci sú jedinečné hodnoty, tak už bude jednoznačne určené poradie riadkov pre výber. Výsledný vzorec merítka bude takýto:
Obrat za TOP 3 zákazníkov =
SUMX (
TOPN (
3;
SUMMARIZE (
'Objednávky';
'Objednávky'[CustomerKey];
"Obrat za zákazníka"; [Obrat]
);
[Obrat za zákazníka]; DESC;
[CustomerKey]; ASC
);
[Obrat za zákazníka]
)
A po skliknutí kontingenčky naspäť na úroveň mesiacov nám to už správne vypočíta obrat za 3 najlepších zákazníkov. Nielen pri septembri 2001, ale tentokrát už všade:
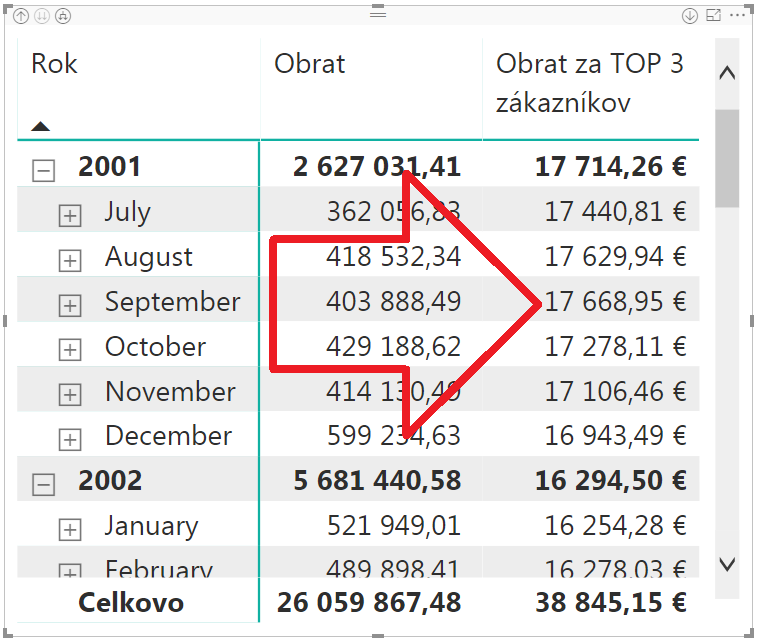
Takto teda viete jednoznačne povedať funkcii TOPN, že čo má vybrať spomedzi riadkov. A aj keď sa vám to ešte nestáva na vašich dátach, tak preventívne by ste mali dávať vždy aj sekundárne zoradenie do funkcie TOPN. Pretože keď sa niekedy v budúcnosti podkladové dáta zmenia, tak môžete dostať takéto nepresné výsledky. Do sekundárneho zoradenia by mal ísť ideálne vždy nejaký stĺpec s unikátnymi hodnotami, ale môže tam ísť aj iná kombinácia stĺpcov. Podstatné je, že sa vám podarí jednoznačne pomocou nich určiť jedinečné poradie pre každý riadok.
A jazyk DAX skrýva viacero takýchto prekvapení. Nie že by to bolo niečo zlé, len nie vždy to v dokumentácii aj nájdete, resp. nie vždy si to tam medzi tou tonou textu aj všimnete. A veľakrát takéto veci viete iba zo skúseností, alebo z poriadneho školenia. Pretože nie vždy tie funkcie robia presne to, čo očakávate. Od toho sme ale tu, aby sme sa to poriadne naučili. Tak aby vás takýchto prekvapení do budúcnosti čakalo čo najmenej 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.