Pred pár dňami sme si ukázali, ako jednoducho analyzovať vyťaženosť ľudí na projektoch v PowerPivote a v Power BI, pomocou techniky kombinačných tabuliek. Problém tejto techniky je v tom, že napriek tomu, že report je megarýchly aj na veľkom počte riadkov, tak počas prepočtu dátového modelu to dokáže spotrebovať aj desiatky GB RAM. Čo si väčšina užívateľov nemôže dovoliť. Najmä nie tí, ktorí majú 32-bitový Excel či Power BI Desktop. Preto sa teraz pozrieme na to, ako to spraviť aj bez kombinačných tabuliek.
Táto technika však bude mať jednu veľkú nevýhodu. Ak budete mať v pôvodných dátach milióny riadkov, tak report nemusí reagovať hneď na prekliky užívateľa. Keď vám však nevadí čakať zopár sekúnd na zobrazenie výsledkov, či máte 32-bitový PowerPivot, tak inú možnosť ani nemáte.
Začneme teda s rovnakou tabuľkou ako v predchádzajúcom článku, ktorá obsahuje obsahuje zoznam jednotlivých projektov, ich fázy a zodpovedné osoby v každej fáze:

V nej si všimnite, že takmer každá fáza projektu má počiatočný aj koncový dátum, a ak práve prebieha, tak by tam mala byť priradená aj zodpovedná osoba.
A zadanie je teraz spraviť jednoduchú analýzu – chceme vidieť, kto bol kedy alokovaný na koľko projektov. Čiže budeme chcieť mať kontingenčku, kde na riadkoch budú všetky osoby, na stĺpcoch vybrané dátumy, a na priesečníku informácie o obsadenosti daného človeka v danom dni – napr. o počte či názve projektov, na ktorých je daný človek priradený v danom dni.
Najprv si teda naimportujeme túto tabuľku do nášho dátového modelu, pod názvom Projekty.
Takáto tabuľka však nie je priamo vhodná na analýzu, aj keď toto je typická štruktúra dát, ktorú bežne dostanete z nástrojov na riadenie portfólia projektov. Je to kvôli tomu, že osoby chceme mať na riadkoch kontingečky, a musíme ich preto dostať z viacerých stĺpcov do 1 stĺpca v tabuľke. Takisto dátumy máme vo viacerých stĺpcoch, a pre kontingenčku potrebujú byť sekvenčne usporiadané v jednom stĺpci, od najmenšieho po najväčší, aj keď sú medzi nimi medzery. Preto si ju budeme musieť v prvom kroku upraviť. Potom sa nám bude vyťaženosť ľudí analyzovať oveľa ľahšie.
Ideálnym spôsobom by bolo vytvoriť kombinačnú tabuľku, ako v predchádzajúcom článku. Lenže máme iba 32-bitový PowerPivot či málo RAM, a musíme ísť tentokrát na to inak.
V prvom kroku si spravíme v dátovom modeli tabuľku, kde bude stĺpec iba so všetkými unikátnymi osobami zo všetkých fáz projektu. To môžete spraviť v Power Query, aj v PowerPivote. My to teraz spravíme v PowerPivote, takouto vypočítanou tabuľkou:
Osoby = FILTER(DISTINCT(UNION(SELECTCOLUMNS(Projekty; „Osoba“; Projekty[Fáza 1 osoba]); SELECTCOLUMNS(Projekty; „Osoba“; Projekty[Fáza 2 osoba]); SELECTCOLUMNS(Projekty; „Osoba“; Projekty[Fáza 3 osoba]))); [Osoba] <> BLANK())
…alebo vypeknené cez DAX Formatter:

Prvé riadky tejto tabuľky budú vyzerať takto:
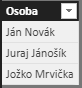
V tomto kroku sme si zistili zoznam unikátnych osôb zo všetkých stĺpcov, odfiltrovali na neprázdne riadky, a uložili do novej vypočítanej tabuľky s názvom Osoby.
Ďalšom kroku použijeme metódu sekvenčných tabuliek, kde si pomocou funkcie CALENDAR vytvoríme jednostĺpcovú tabuľku s názvom Dátumy, v ktorej budú dátumy od globálneho minima z dátumových stĺpcov s počiatkami fáz, po globálne maximum z dátumových stĺpcov z koncami fáz:
Dátumy = CALENDAR(MIN(MIN(MIN(Projekty[Fáza 1 začiatok]); MIN(Projekty[Fáza 2 začiatok])); MIN(Projekty[Fáza 3 začiatok])); MAX(MAX(MAX(Projekty[Fáza 1 koniec]); MAX(Projekty[Fáza 2 koniec])); MAX(Projekty[Fáza 3 koniec])))
…alebo vypeknené cez DAX Formatter:

Prvé riadky tejto tabuľky budú vyzerať takto:
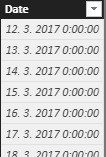
Následne už iba stačí vytvoriť merítko, ktoré nám v kontingenčke bude na priesečníku osôb a dátumov počítať, či daná osoba bola vyťažená na nejakom projekte. V tomto merítku budeme predpokladať, že v kontingenčke sú na riadkoch osoby z tabuľky Osoby a stĺpca Osoba, a v stĺpcoch jednotlivé dátumy z tabuľky Dátumy a stĺpca Date. Oblasť riadkov aj stĺpcov môžete medzi sebou aj prehodiť, je to zajedno.
Výsledné merítko teda bude takéto:
Vytazena =
VAR vybranaOsoba = SELECTEDVALUE(Osoby[Osoba])
VAR vybranyDatum = SELECTEDVALUE(‚Dátumy'[Date])
RETURN
IF(COUNTROWS(FILTER(Projekty; (Projekty[Fáza 1 osoba] = vybranaOsoba && Projekty[Fáza 1 začiatok] <= vybranyDatum && vybranyDatum <= Projekty[Fáza 1 koniec]) || (Projekty[Fáza 2 osoba] = vybranaOsoba && Projekty[Fáza 2 začiatok] <= vybranyDatum && vybranyDatum <= Projekty[Fáza 2 koniec]) || (Projekty[Fáza 3 osoba] = vybranaOsoba && Projekty[Fáza 3 začiatok] <= vybranyDatum && vybranyDatum <= Projekty[Fáza 3 koniec]))) > 0; „X“)
…alebo vypeknené cez DAX Formatter:

Toto merítko si zistí cez funkciu FILTER zoznam projektov, na ktorých je v danom dni daná osoba priradená aspoň v jednej fáze projektu. Použili sme tam pre zjednodušenie premenné vybranaOsoba a vybranyDatum, ktorými si zistíme vybranú osobu a dátum na ich aktuálne počítanom priesečníku v kontingenčke. Ak máte starší PowerPivot a nepodporuje funkciu SELECTEDVALUE, tak si pozrite v mojej knihe, ako sa to dá zistiť alternatívnym vzorcom.
Teraz tieto 2 tabuľky a merítko využijeme na konštrukciu finálnej kontingenčky:
- na riadky dáme z tabuľky Osoby stĺpec Osoba,
- do stĺpcov dáme z tabuľky Dátumy stĺpec Date,
- do oblasti hodnôt dáme práve vytvorené merítko Vytazena.
- zapneme zobrazovanie riadkov a stĺpcov bez hodnôt,
- vypneme zobrazovanie celkových súčtov a medzisúčtov, ak nám vadia.
Po odfiltrovaní kontingenčky napr. na dátumy 19. – 23.10.2018 uvidíme nádhernú vyťaženosť ľudí, tak ako aj v predchádzajúcom článku:

Tam vidíte, že keď bola daná osoba v danom dni vyťažená na ľubovoľnom projekte, tak je tam zobrazené X.
Výhodou tohto spôsobu počítania je takmer nulová pamäťová náročnosť výpočtu. A teda takýto report vám to zobrazí aj na ľubovoľnej kalkulačke. Nevýhodou je algoritmická náročnosť výpočtu, kvôli ktorej vám pri väčších zdrojových dátach môže prepočítavať kontingenčku aj niekoľko sekúnd. Ak ale máte obmedzené zdroje, tak to vydržíte.
Keď chceme vidieť počty projektov, na ktorých bola daná osoba v danom dni vyťažená, tak si budeme musieť vyrobiť ďalšie merítko, a potom ho vymeniť za to aktuálne v kontingenčke:
Vytazena pocet =
VAR vybranaOsoba = SELECTEDVALUE(Osoby[Osoba])
VAR vybranyDatum = SELECTEDVALUE(‚Dátumy'[Date])
RETURN
COUNTROWS(FILTER(Projekty; (Projekty[Fáza 1 osoba] = vybranaOsoba && Projekty[Fáza 1 začiatok] <= vybranyDatum && vybranyDatum <= Projekty[Fáza 1 koniec]) || (Projekty[Fáza 2 osoba] = vybranaOsoba && Projekty[Fáza 2 začiatok] <= vybranyDatum && vybranyDatum <= Projekty[Fáza 2 koniec]) || (Projekty[Fáza 3 osoba] = vybranaOsoba && Projekty[Fáza 3 začiatok] <= vybranyDatum && vybranyDatum <= Projekty[Fáza 3 koniec])))
…alebo vypeknené cez DAX Formatter:

Je to to isté merítko ako v predchádzajúcom príklade, len sme z neho odstránili funkciu IF, pretože teraz chceme vedieť počet riadkov (čiže počet projektov, na ktoré je daná osoba v danom dátume priradená). Výsledok po výmene predchádzajúceho merítka za toto v kontingenčke bude vyzerať takto:

A čo keby sme teraz namiesto tých čísel a X-iek chceli vidieť zoznam projektov, na ktorých daná osoba pracuje? Pre každého lepšieho powerpivotistu žiaden problém, všetko vyrieši jedno správne merítko: 🙂
Vytazena projekty =
VAR vybranaOsoba = SELECTEDVALUE(Osoby[Osoba])
VAR vybranyDatum = SELECTEDVALUE(‚Dátumy'[Date])
RETURN
CONCATENATEX(FILTER(Projekty; (Projekty[Fáza 1 osoba] = vybranaOsoba && Projekty[Fáza 1 začiatok] <= vybranyDatum && vybranyDatum <= Projekty[Fáza 1 koniec]) || (Projekty[Fáza 2 osoba] = vybranaOsoba && Projekty[Fáza 2 začiatok] <= vybranyDatum && vybranyDatum <= Projekty[Fáza 2 koniec]) || (Projekty[Fáza 3 osoba] = vybranaOsoba && Projekty[Fáza 3 začiatok] <= vybranyDatum && vybranyDatum <= Projekty[Fáza 3 koniec]));
Projekty[Názov]; UNICHAR(13) & UNICHAR(10); Projekty[Názov]; ASC)
…alebo vypeknené cez DAX Formatter:

V tomto prípade sme zobrali zasa len predchádzajúce merítko, a namiesto spočítavania riadkov funkciou COUNTROWS sme z nich zagregovali názvy projektov zo stĺpca Projekty[Názov] do jednej textovej hodnoty oddelenej windowsáckym koncom riadku. Agregáciu sme spravili funkciou CONCATENATEX, a koniec riadku týmti dvoma funkciami UNICHAR, podobne ako v predchádzajúcom článku.
Výsledok bude vyzerať takto:

Toto celé riešenie bude samozrejme fungovať aj na úrovni mesiacov, štvrťrokov či rokov. Len v tom poslednom merítku budete musieť pridať funkciu DISTINCT medzi funkcie CONCATENATEX a FILTER, aby vám to odstránilo duplicitné názvy projektov, ktoré sme na úrovni dní nemuseli riešiť.
Takže takto to celé ide spraviť aj s veľmi obmedzenými prostriedkami. Keď budete mať milióny riadkov, tak to trochu môže trvať, kým to zobrazí tú kontingenčku. Ale keďže máte obmedzené zdroje, a kde nič nie je, tam ani smrť nebere, tak treba jednoducho chvíľu počkať. Podstatné je to, že sa vám to takto podarí aj s veľmi malým množstvom pamäte, a vďaka tomu dosiahnete presne to, čo ste chceli. Síce trochu pomalšie, ale niekedy pomalšie ďalej zájdete 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.