V projektovom riadení je častá požiadavka na analýzu vyťaženosti jednotlivých zdrojov, najmä ľudí. Zatiaľ čo nástroje ako Microsoft Project takúto funkcionalitu majú, tak ich použitie nie je vždy vhodné. Napr. vtedy, keď takúto štatistiku chcete zahrnúť do reportu, a nie všetci jeho konzumenti majú nainštalovaný MS Project. Preto si teraz ukážeme, ako analyzovať vyťaženosť ľudí na projektoch v PowerPivote a v Power BI, ktoré sú oveľa dostupnejšie.
Majme takúto tabuľku, ktorá zobrazuje zoznam jednotlivých projektov, ich fázy a zodpovedné osoby v každej fáze:

V nej si všimnite, že takmer každá fáza projektu má počiatočný aj koncový dátum, a ak práve prebieha, tak by tam mala byť priradená aj zodpovedná osoba.
A zadanie je teraz spraviť jednoduchú analýzu – chceme vidieť, kto bol kedy alokovaný na koľko projektov. Čiže budeme chcieť mať kontingenčku, kde na riadkoch budú všetky osoby, na stĺpcoch vybrané dátumy, a na priesečníku informácie o obsadenosti daného človeka v danom dni – napr. o počte či názve projektov, na ktorých je daný človek priradený v danom dni.
Najprv si teda naimportujeme túto tabuľku do nášho dátového modelu, pod názvom Projekty.
Takáto tabuľka však nie je priamo vhodná na analýzu, aj keď toto je typická štruktúra dát, ktorú bežne dostanete z nástrojov na riadenie portfólia projektov. Je to kvôli tomu, že osoby chceme mať na riadkoch kontingečky, a musíme ich preto dostať z viacerých stĺpcov do 1 stĺpca v tabuľke. Takisto dátumy máme vo viacerých stĺpcoch, a pre kontingenčku potrebujú byť sekvenčne usporiadané v jednom stĺpci, od najmenšieho po najväčší, aj keď sú medzi nimi medzery. Preto si ju budeme musieť v prvom kroku upraviť. Potom sa nám bude vyťaženosť ľudí analyzovať oveľa ľahšie.
Tabuľku teda upravíme na kombinačnú tabuľku, kde budú v prvom stĺpci všetky dátumy, kombinované v druhom stĺpci so všetkými osobami, kombinované v treťom stĺpci so všetkými názvami projektov. A ku každej takejto kombinácii si vypočítame, či bola daná osoba v danom dátume na danom projekte obsadená. Z takejto tabuľky už potom bude hračka spraviť kontingenčku či ľubovoľné iné výpočty. A najmä výpočty budu turbo rýchle.
Čo sa týka veľkosti tabuľky, tak to vás nemusí zrovna trápiť. Keby ste mali povedzme 100 projektov, na nich 100 rôznych ľudí a dáta za 3 roky, tak to máme 100 * 100 * (3*365) = 10,95 milióna riadkov. Z čoho by Excel kľakol, ale pre PowerPivot je to hračka. Navyše vďaka tomu, že údaje v tejto tabuľke sa budú veľmi často opakovať, a že PowerPivot ich v pamäti veľmi silno komprimuje, tak nezaberú veľké miesto v pamäti – väčšinou iba zopár megabajtov. V tomto konkrétnom prípade so 100 mil. riadkov to u jedného klienta počítalo celý príklad cca. 2 minúty, spotrebovalo v špičke 1,3 GB RAM a výsledný súbor PBIX mal iba 1,1 MB. Plus tým, že štruktúru dát prispôsobíme PowerPivotu, tak výpočty na takejto kôpke dát budú okamžité. Pretože dokým tam nemáte stámilióny až miliardy riadkov dát, tak vás rýchlosť absolútne nebude trápiť.
Ak by Vám to aj napriek tomu nezbehlo v ľubovoľnom kroku na nedostatok pamäte, tak si pozrite článok, kde je táto technika bez použitia kombinačných tabuliek. Inak radšej zostaňte pri tejto technike kvôli rýchlosti reportu.
Poďme teda na to.
Vytvoríme si teda najprv novú vypočítanú tabuľku v dátovom modeli, zo všetkých dátumov v dátach:
Osoby po dnoch a projektoch = CALENDAR(MIN(MIN(MIN(Projekty[Fáza 1 začiatok]); MIN(Projekty[Fáza 2 začiatok])); MIN(Projekty[Fáza 3 začiatok])); MAX(MAX(MAX(Projekty[Fáza 1 koniec]); MAX(Projekty[Fáza 2 koniec])); MAX(Projekty[Fáza 3 koniec])))
…alebo vypeknené cez DAX Formatter:

Prvé riadky tejto tabuľky budú vyzerať takto:

Tu sme použili metódu sekvenčných tabuliek, kde si pomocou funkcie CALENDAR vytvoríme jednostĺpcovú tabuľku, v ktorej budú dátumy od globálneho minima z dátumových stĺpcov s počiatkami fáz, po globálne maximum z dátumových stĺpcov z koncami fáz.
V ďalšom kroku si zistíme zoznam unikátnych osôb zo všetkých stĺpcov, odfiltrujeme na neprázdne riadky, a skombinujeme pomocou funkcie CROSSJOIN s našim dátumovým stĺpcom z predchádzajúceho kroku, pomocou techniky kombinačných tabuliek:
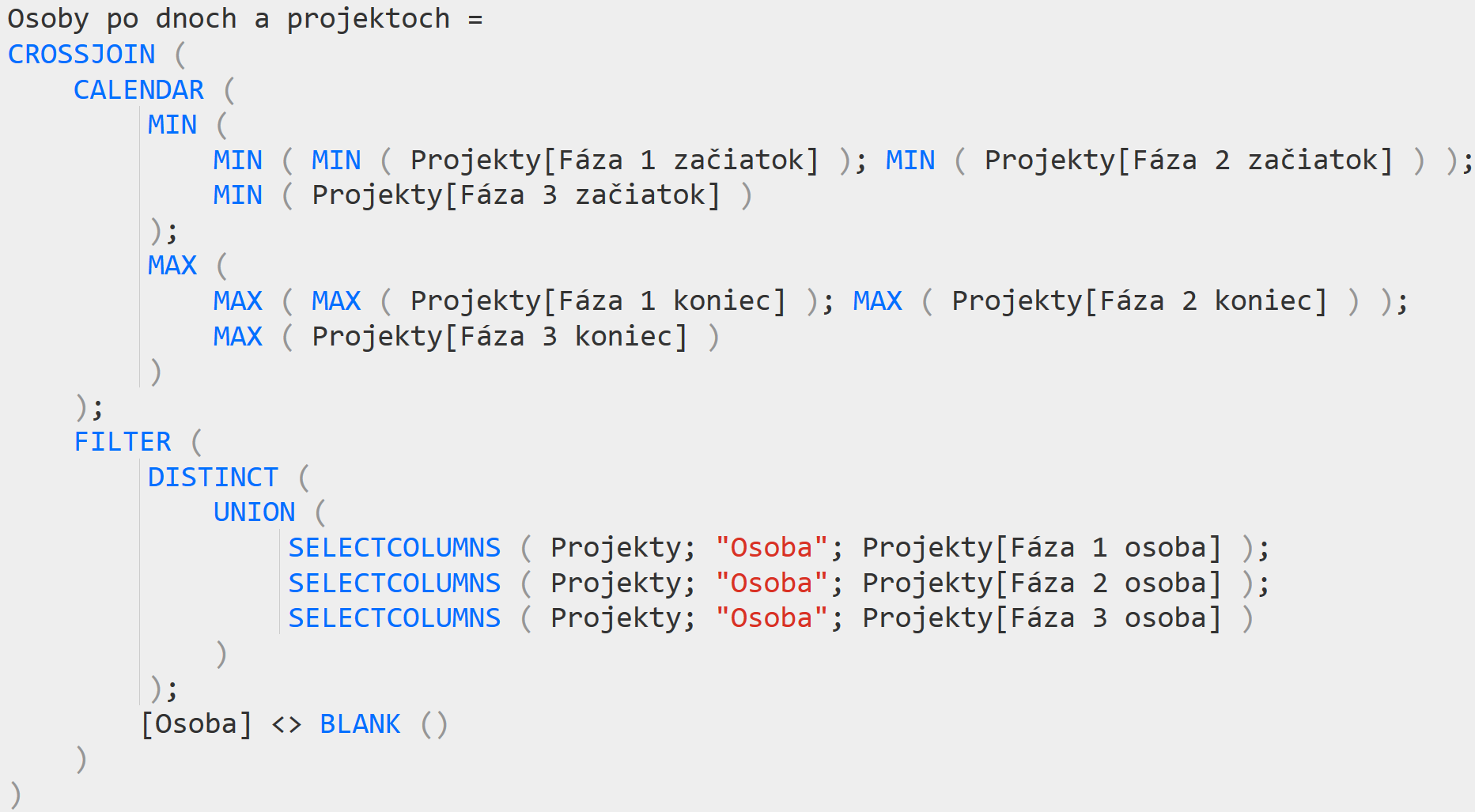
Osoby po dnoch a projektoch = CROSSJOIN(CALENDAR(MIN(MIN(MIN(Projekty[Fáza 1 začiatok]); MIN(Projekty[Fáza 2 začiatok])); MIN(Projekty[Fáza 3 začiatok])); MAX(MAX(MAX(Projekty[Fáza 1 koniec]); MAX(Projekty[Fáza 2 koniec])); MAX(Projekty[Fáza 3 koniec])));
FILTER(DISTINCT(UNION(SELECTCOLUMNS(Projekty; „Osoba“; Projekty[Fáza 1 osoba]); SELECTCOLUMNS(Projekty; „Osoba“; Projekty[Fáza 2 osoba]); SELECTCOLUMNS(Projekty; „Osoba“; Projekty[Fáza 3 osoba]))); [Osoba] <> BLANK()))
…alebo vypeknené cez DAX Formatter:
Prvé riadky tejto tabuľky budú vyzerať takto:

Následne ešte do funkcie CROSSJOIN v predchádzajúcom kroku, doplníme stĺpec, kde to všetko skombinujeme so všetkými názvami projektov:
Osoby po dnoch a projektoch = CROSSJOIN(CALENDAR(MIN(MIN(MIN(Projekty[Fáza 1 začiatok]); MIN(Projekty[Fáza 2 začiatok])); MIN(Projekty[Fáza 3 začiatok])); MAX(MAX(MAX(Projekty[Fáza 1 koniec]); MAX(Projekty[Fáza 2 koniec])); MAX(Projekty[Fáza 3 koniec])));
FILTER(DISTINCT(UNION(SELECTCOLUMNS(Projekty; „Osoba“; Projekty[Fáza 1 osoba]); SELECTCOLUMNS(Projekty; „Osoba“; Projekty[Fáza 2 osoba]); SELECTCOLUMNS(Projekty; „Osoba“; Projekty[Fáza 3 osoba]))); [Osoba] <> BLANK());
VALUES(Projekty[Názov]))
…alebo vypeknené cez DAX Formatter:

Prvé riadky tejto tabuľky budú vyzerať takto:

Toto je už teda klasická kombinačná tabuľka, kde máme v prvom stĺpci všetky dátumy, kombinované v druhom stĺpci so všetkými osobami, kombinované v treťom stĺpci so všetkými názvami projektov. A ku každej takejto kombinácii si vypočítame, či bola daná osoba v danom dátume na danom projekte obsadená. Spravíme to v tejto tabuľke týmto vypočítaným stĺpcom:
Vytazena = IF(COUNTROWS(FILTER(Projekty; Projekty[Fáza 1 začiatok] <= ‚Osoby po dnoch a projektoch'[Date] && ‚Osoby po dnoch a projektoch'[Date] <= Projekty[Fáza 1 koniec] && ‚Osoby po dnoch a projektoch'[Osoba] = Projekty[Fáza 1 osoba] && ‚Osoby po dnoch a projektoch'[Názov] = Projekty[Názov])) > 0 ||
COUNTROWS(FILTER(Projekty; Projekty[Fáza 2 začiatok] <= ‚Osoby po dnoch a projektoch'[Date] && ‚Osoby po dnoch a projektoch'[Date] <= Projekty[Fáza 2 koniec] && ‚Osoby po dnoch a projektoch'[Osoba] = Projekty[Fáza 2 osoba] && ‚Osoby po dnoch a projektoch'[Názov] = Projekty[Názov])) > 0 ||
COUNTROWS(FILTER(Projekty; Projekty[Fáza 3 začiatok] <= ‚Osoby po dnoch a projektoch'[Date] && ‚Osoby po dnoch a projektoch'[Date] <= Projekty[Fáza 3 koniec] && ‚Osoby po dnoch a projektoch'[Osoba] = Projekty[Fáza 3 osoba] && ‚Osoby po dnoch a projektoch'[Názov] = Projekty[Názov])) > 0;
„X“)
…alebo vypeknené cez DAX Formatter:

Vzorové riadky tejto tabuľky budú vyzerať takto:

V nich vidíte, že keď daná osoba bola priradená v danom dátume na ľubovoľnej fáze daného projektu, tak je v tomto stĺpci hodnota „X“, inak je tam prázdna hodnota. Vzorec by sa dal napísať aj kratšie, napr. združením všetkých tých podmienok do 1 filtra, ale tu je to rozpísané pre názornosť, aby ste sa v tom ľahšie zorientovali.
Poznámka: Táto časť kroku je na veľkých tabuľkách veľmi náročná na miesto v pamäti, a pri stámiliónoch riadkov to môže dočasne spotrebovať aj desiatky GB RAM počas výpočtu. Potom Power BI Desktop vyhodí takúto hlášku:
![]()
Keby Vám to padlo v tomto kroku na tejto chybe, tak máte 2 možnosti – použiť pomalšiu techniku bez kombinačných tabuliek, alebo optimalizovať pamäťovú náročnosť výpočtu.
A keď už máme takúto kombinačnú tabuľku, tak môžeme analyzovať vyťaženosť ľudí v kontingenčke, podobne ako v článku o kombinačných tabuľkách.
Vytvoríme si teda kontingenčku, resp. maticu, podľa toho kde ste, takto:
- do riadkov dáme z tabuľky „Osoby po dnoch“ a projektoch stĺpec Osoba,
- do stĺpcov dáme z tabuľky „Osoby po dnoch a projektoch“ stĺpec Date,
- do oblasti hodnôt dáme z tabuľky „Osoby po dnoch a projektoch“ stĺpec Vytazena, a nastavíme funkciu súhrnu na Prvé/First,
- zapneme zobrazovanie riadkov a stĺpcov bez hodnôt,
- vypneme zobrazovanie celkových súčtov a medzisúčtov, ak nám vadia.
Po odfiltrovaní kontingenčky napr. na dátumy 19. – 23.10.2018 uvidíme nádhernú vyťaženosť ľudí:

Tam vidíte, že keď bola daná osoba v danom dni vyťažená na ľubovoľnom projekte, tak je tam zobrazené X. Funguje to vďaka tomu, že súhrnná funkcia Prvé/First, ktorú sme nastavili poľu Vytazena v oblasti hodnôt, funguje tak, že zobrazí prvú neprázdnu hodnotu z tohto poľa. Preto ak mala daná osoba v daný deň v tomto poli aspoň v jednej bunke „X“, tak sa zobrazí aj tu.
Keď chceme vidieť počty projektov, na ktorých bola daná osoba v danom dni vyťažená, tak stačí v kontingenčke iba zmeniť súhrnnú funkciu pre pole Vytazena v oblasti hodnôt na Počet/Count. Táto funkcia spočíta počet neprázdnych hodnôt v danom poli, a teda počet projektov pre daný deň a danú osobu:

Tu už sa môže hodiť aj zapnutie celkových súčtov, najmä naspodu, aby ste videli počet osobodní v danom dni, resp. číselnú vyťaženosť ľudí v danom dni. Ak teda chcete.
A čo keby sme teraz namiesto tých čísel a X-iek chceli vidieť zoznam projektov, na ktorých daná osoba pracuje? Pre každého lepšieho powerpivotistu žiaden problém, všetko vyrieši jedno správne merítko: 🙂
Názvy projektov = CONCATENATEX(FILTER(‚Osoby po dnoch a projektoch‘; ‚Osoby po dnoch a projektoch'[Vytazena] = „X“); ‚Osoby po dnoch a projektoch'[Názov]; UNICHAR(13) & UNICHAR(10) ; ‚Osoby po dnoch a projektoch'[Názov]; ASC)
…alebo vypeknené cez DAX Formatter:

Keď si ho dosadíte do oblasti hodnôt namiesto toho poľa Vytazena, tak to zobrazí v každej bunke zoznam projektov na osobitných riadkoch pod sebou:

V tomto príklade sme využili funkciu FILTER, ktorou sme si odfiltrovali príslušné hodnoty v tabuľke „Osoby po dnoch a projektoch“ len na tie riadky, kde sú X-ká. Potom sme z týchto riadkov zobrali hodnoty v stĺpci Názov (názvy daných projektov), a funkciou CONCATENATEX sme ich zlepili do jedného reťazca. Hodnoty sme dali oddeliť koncami riadkov – vo Windows reprezentované znakmi s kódmi 13+10, zapísané funkciami UNICHAR(13) & UNICHAR(10) – a pred zlepením do jednej hodnoty sme dali ďalšími parametrami funkcie CONCATENATEX zoradiť tieto názvy projektov abecedne.
Toto celé riešenie bude samozrejme fungovať aj na úrovni mesiacov, štvrťrokov či rokov. Len v tom poslednom merítku budete musieť pridať funkciu DISTINCT medzi funkcie CONCATENATEX a FILTER, aby vám to odstránilo duplicitné názvy projektov, ktoré sme na úrovni dní nemuseli riešiť.
Takto sa teda dá bez problémov analyzovať aj zle navrhnutá tabuľka, a pomocou zopár vzorcov sa dá pretočiť na vhodnú analytickú tabuľku. Následná analýza nad takouto tabuľkou, či už ide o analyzujete vyťaženosť ľudí na projektoch, procesoch či iných činnostiach, je už potom hračkou. A aj keď to vyzerá ako obrovská kopa dát a veľké vzorce, tak pre PowerPivot je to hračka. Tak isto ako aj pre ľubovoľného Jedi majstra v PowerPivote, kde toto celé riešenie sa dá urobiť za menej ako pol hodiny 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.