Pri analýze predaja je veľakrát potrebné zistiť nielen to, koľko bolo uskutočnených objednávok alebo zmlúv, ale aj to, či boli od nových zákazníkov, existujúcich zákazníkov, a či nebodaj niektorí zákazníci aj neodišli. Zisťuje sa tým napr. fluktuácia zákazníkov, ale aj rôzne ďalšie zaujímavé veci z pohľadu predaja aj marketingu. Preto sa teraz pozrieme, ako to zistiť a vypočítať.
Tak ako aj v predchádzajúcich článkoch, aj v tomto prípade začneme s našim vzorovým súborom PowerPivotu, resp. Power BI. Výsledné riešenie bude fungovať v Exceli 2016 a novšom, v Office 365 a v Power BI. Riešenie pre staršie Excely bude potrebné spraviť náhradným spôsobom, ktorému sa možno budeme venovať v niektorom budúcom článku.
Najprv si vytvoríme nové merítko „Počet zákazníkov“ v tabuľke Objednávky, s týmto vzorcom:
Počet zákazníkov = DISTINCTCOUNT(‚Objednávky'[CustomerKey])
Toto merítko spočítava počet unikátnych zákazníkov v danom kontexte výpočtu. Je to preto, lebo jeden zákazník mohol v rámci jedného časového obdobia spraviť aj viac ako jednu objednávku. Spočítava sa to zo stĺpca CustomerKey v tabuľke Objednávky, ktorý obsahuje číslo zákazníka pre každú jednu objednávku.
Potom vytvoríme kontingenčnú tabuľku, kde:
- do oblasti riadkov dáme z tabuľky Čas hierarchiu Rok-Mesiac-Deň, a rozklikneme ju na úroveň mesiaca,
- do oblasti hodnôt dáme merítko Počet zákazníkov.
Výsledok bude vyzerať takto:
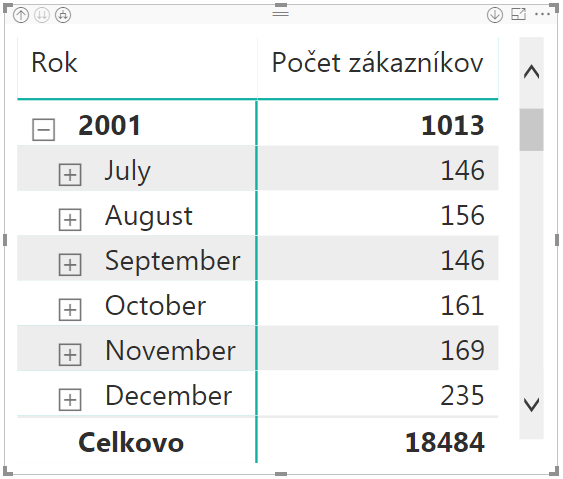
To nám zobrazí počet zákazníkov v jednotlivých mesiacoch.
Teraz si dáme zobraziť rozdiel v počte zákazníkov medzi jednotlivými mesiacmi. Označíme teda tabuľku Čas ako časovú tabuľku, a pomocou funkcie DATEADD vypočítame, čo potrebujeme, pomocou nového merítka:
Medzimesačný rozdiel = IF(HASONEVALUE(‚Čas'[MonthName]); [Počet zákazníkov] – CALCULATE([Počet zákazníkov]; DATEADD(‚Čas'[DateKey]; -1; MONTH)))
V tomto merítku počítame rozdiel medzi aktuálnym počtom zákazníkov, a počtom zákazníkov posunutým o mesiac dozadu. Zaujímavé je jedine testovanie pomocou funkcie HASONEVALUE, ktorým si skontrolujeme, či je v kontexte výpočtu vybraný iba 1 mesiac. Aby sa to nepočítalo na úrovni rokov.
Výsledok po pridaní do kontingenčky bude vyzerať takto:
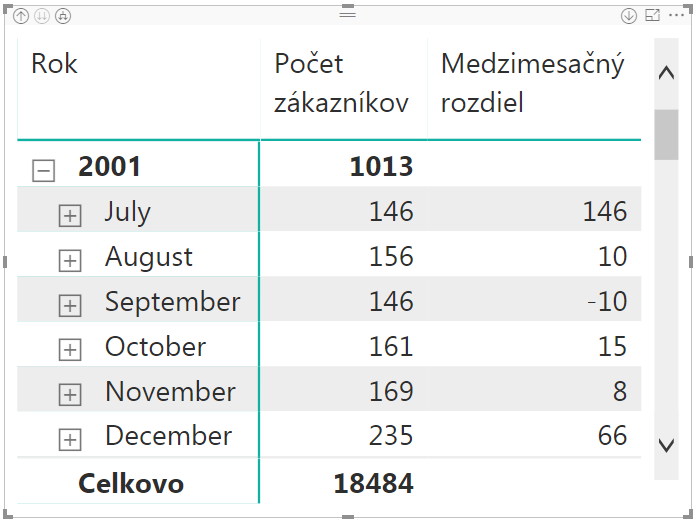
Tam vidíte, že počet zákazníkov sa medzi jednotlivými mesiacmi nejako dramaticky nemení, a je relatívne stály. Ale iba na prvý pohľad.
Problém je v tom, že keď napr. v prvom mesiaci máme 146 zákazníkov a v druhom 156, tak to vyzerá ako úspech. Zvýšil sa nám počet zákazníkov o 10. Vieme však, či tých 156 v druhom mesiaci je tých 146 zákazníkov z prvého mesiaca + 10 nových, alebo nám nejakí zákazníci z minulého mesiaca odišli a namiesto nich prišlo oveľa viac zákazníkov? Z týchto čísel určite nie. A budeme to musieť porovnať po jednotlivých zákazníkoch.
Spravíme si preto niekoľko merítok, pomocou ktorých to už budeme vedieť zistiť. Začneme s merítkom „Noví zákazníci“, ktoré spočíta počet zákazníkov, ktorí pribudli voči predchádzajúcemu mesiacu (vypeknené cez DAX Formatter):
Noví zákazníci =
IF (
HASONEVALUE ( 'Čas'[MonthName] );
COUNTROWS (
EXCEPT (
SUMMARIZE ( 'Objednávky'; 'Objednávky'[CustomerKey] );
CALCULATETABLE (
SUMMARIZE ( 'Objednávky'; 'Objednávky'[CustomerKey] );
DATEADD ( 'Čas'[DateKey]; -1; MONTH )
)
)
)
)
V tomto merítku používame hneď niekoľko zaujímavých funkcií. Najprv si uľahčíme výpočet pomocou funkcie SUMMARIZE, pomocou ktorej zoskupíme objednávky podľa stĺpca CustomerKey. Prvý SUMMARIZE vo vzorci zoskupí objednávky z aktuálneho kontextu výpočtu, a druhý SUMMARIZE zoskupí objednávky z kontextu posunutého na predchádzajúci mesiac (resp. o mesiac dozadu – pomocou funkcií DATEADD a CALCULATETABLE). Prvý SUMMARIZE nám teda vráti tabuľku s jedným stĺpcom, kde budú jedineční zákazníci z aktuálne počítaného mesiaca. A ten CALCULATETABLE nám vráti tiež tabuľku s jedným stĺpcom, kde budú jedineční zákazníci z predchádzajúceho mesiaca. A medzi týmito tabuľkami potrebujeme teraz spraviť už iba množinový rozdiel.
Zavoláme teda nad nimi funkciu EXCEPT, ktorá má takúto syntax:
EXCEPT(tabuľka1; tabuľka2)
Rýchle vysvetlenie: funkcia EXCEPT vráti zoznam riadkov z tabuľky1, ktoré sa nenachádzajú v tabuľke2. Alebo inak – vráti zoznam riadkov z tabuľky1 okrem riadkov v tabuľke2. Výsledok vráti ako tabuľku.
A my teraz využijeme túto funkciu na to, aby sme zistili rozdiel medzi tabuľkami zákazníkov z predchádzajúceho kroku. Zabalíme teda tie 2 tabuľky do funkcie EXCEPT, a tým efektívne zistíme rozdiel medzi zoznamom zákazníkov v aktuálne počítanom mesiaci vs. v predchádzajúcom mesiaci. Čiže zoznam zákazníkov v aktuálne počítanom mesiaci okrem zákazníkov z predchádzajúceho mesiaca. Výsledkom budú zákazníci, ktorí existujú v aktuálne počítanom mesiaci, ale neexistujú v predchádzajúcom mesiaci. Čiže po slovensky – noví zákazníci voči predchádzajúcemu mesiacu. Funkcia EXCEPT nám vráti výsledok ako tabuľku, resp. zoznam riadkov so zákazníkmi. Preto ju ešte zabalíme do funkcie COUNTROWS, ktorá spočíta počet riadkov v tejto tabuľke.
Po dosadení do kontingenčky bude výsledok vyzerať takto:
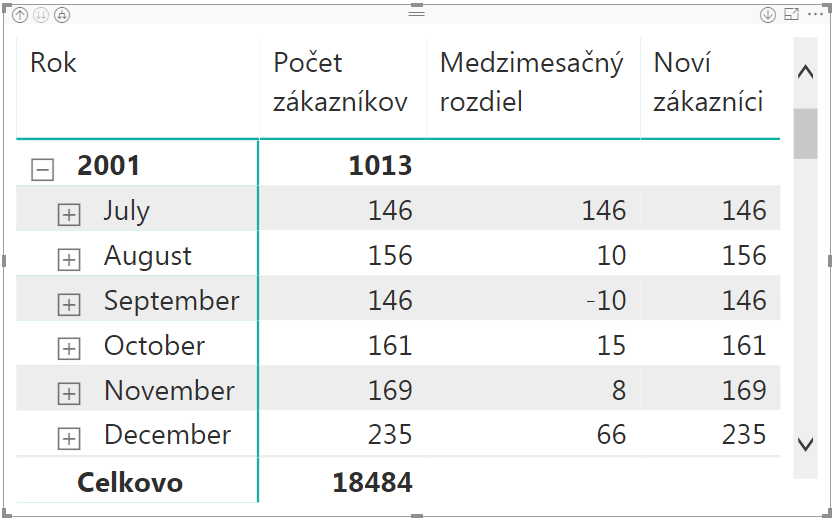
A tu zistíte „překvapeníčko“ – že počet nových zákazníkov v prvých mesiacoch je rovný počtu zákazníkov v danom mesiaci. Čiže všetko sú to noví zákazníci, čo z dlhodobého hľadiska nie je zrovna ideálne. Ale aspoň o tom teraz vieme. Toto je síce syntetická databáza, ale veľakrát to takto vyzerá aj v realite počas prvých mesiacov firmy. Keď sa pozrieme ďalej, napr. na rok 2003, tak tam sa to už začne zlepšovať:
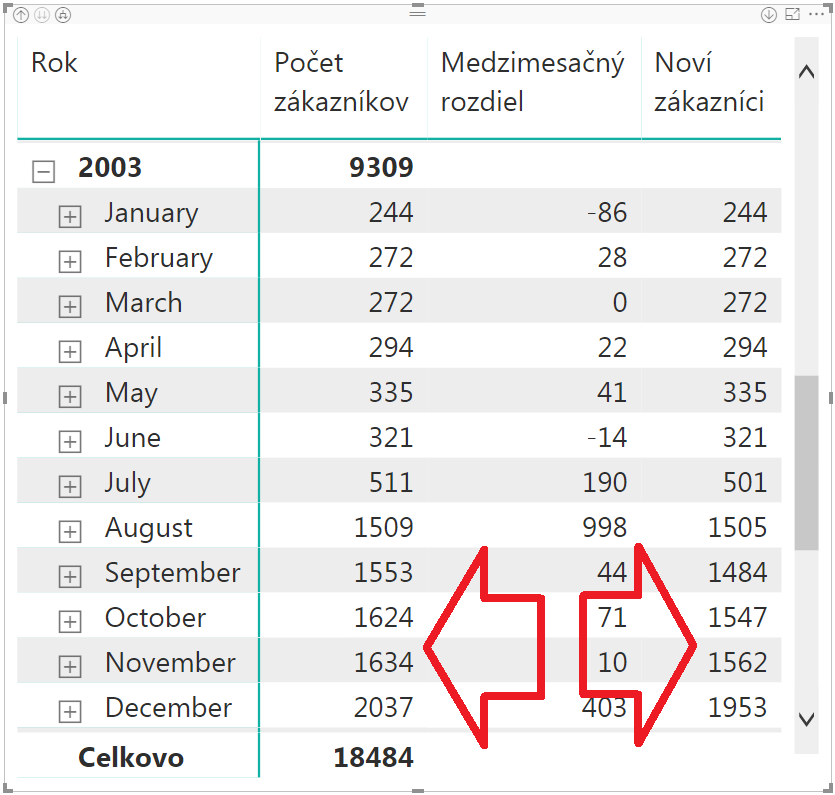
Nie síce o moc, ale predsa. A aby sme to mali kompletné, tak potrebujeme ešte zistiť počet odídených zákazníkov, a počet existujúcich zákazníkov. Počet odídených zákazníkov zistíme týmto novým merítkom:
Odídení zákazníci =
IF (
HASONEVALUE ( 'Čas'[MonthName] );
COUNTROWS (
EXCEPT (
CALCULATETABLE (
SUMMARIZE ( 'Objednávky'; 'Objednávky'[CustomerKey] );
DATEADD ( 'Čas'[DateKey]; -1; MONTH )
);
SUMMARIZE ( 'Objednávky'; 'Objednávky'[CustomerKey] )
)
)
)
Vzorec je rovnaký, iba sme v ňom prehodili poradie parametrov vo funkcii EXCEPT. Čiže sme spravili zoznam zákazníkov z predchádzajúceho mesiaca okrem zákazníkov v aktuálne počítanom mesiaci. Čiže logicky počet odídených zákazníkov:
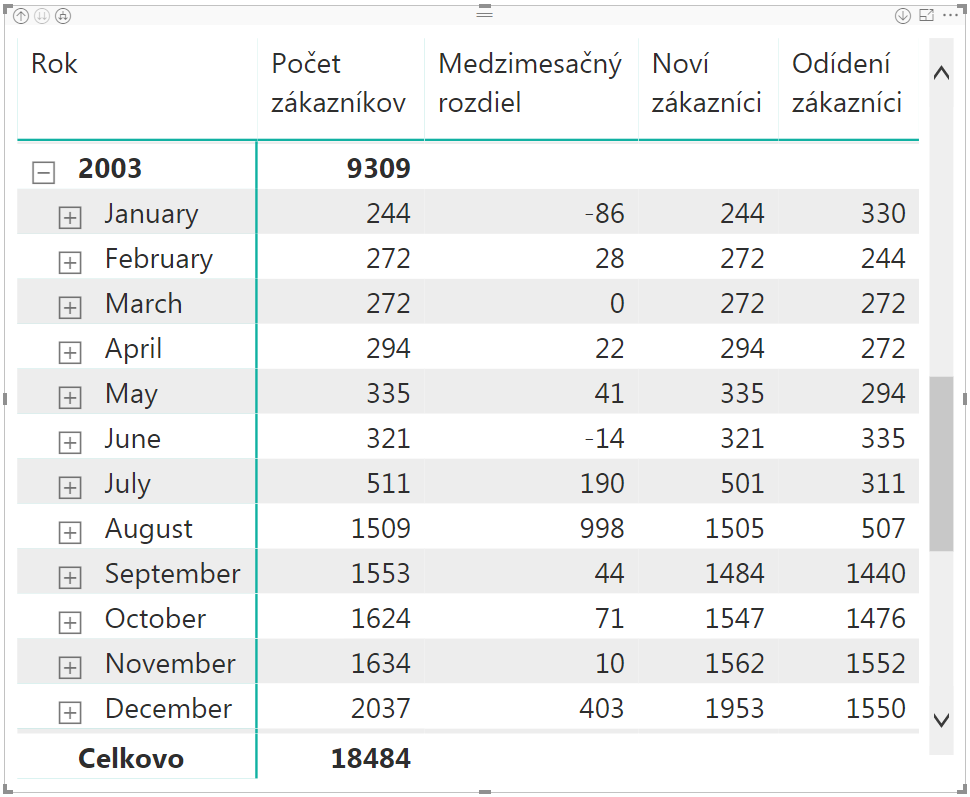
A ako zistíme počet existujúcich, resp. stálych zákazníkov medzi mesiacmi? Použijeme funkciu INTERSECT, ktorá má takúto syntax:
INTERSECT(tabuľka1; tabuľka2)
Rýchle vysvetlenie: funkcia INTERSECT vráti zoznam riadkov z tabuľky1, ktoré sa nachádzajú aj v tabuľke2. Čiže zoznam spoločných riadkov v oboch tabuľkách. Pozor na to, že funkcia ponechá vo výsledku aj prípadné duplicitné riadky.
Teraz už stačí iba zobrať vzorec pre merítko „Noví zákazníci“, a vytvoriť z neho nové merítko „Existujúci zákazníci“, kde funkciu EXCEPT nahradíme funkciou INTERSECT:
Existujúci zákazníci =
IF (
HASONEVALUE ( 'Čas'[MonthName] );
COUNTROWS (
INTERSECT (
SUMMARIZE ( 'Objednávky'; 'Objednávky'[CustomerKey] );
CALCULATETABLE (
SUMMARIZE ( 'Objednávky'; 'Objednávky'[CustomerKey] );
DATEADD ( 'Čas'[DateKey]; -1; MONTH )
)
)
)
)
Toto merítko zoberie zoznam zákazníkov z aktuálne počítaného mesiaca, a pomocou funkcie INTERSECT spraví prienik so zoznamom zákazníkov z predchádzajúceho mesiaca. To vráti zoznam zákazníkov, ktorí sa nachádzajú v oboch mesiacoch súčasne. A keďže je to tabuľka, tak ešte použijeme funkciu COUNTROWS, aby sme z nej spočítali počet riadkov, čiže v tomto prípade počet výsledných zákazníkov.
Po dosadení do kontingenčky to bude vyzerať takto:
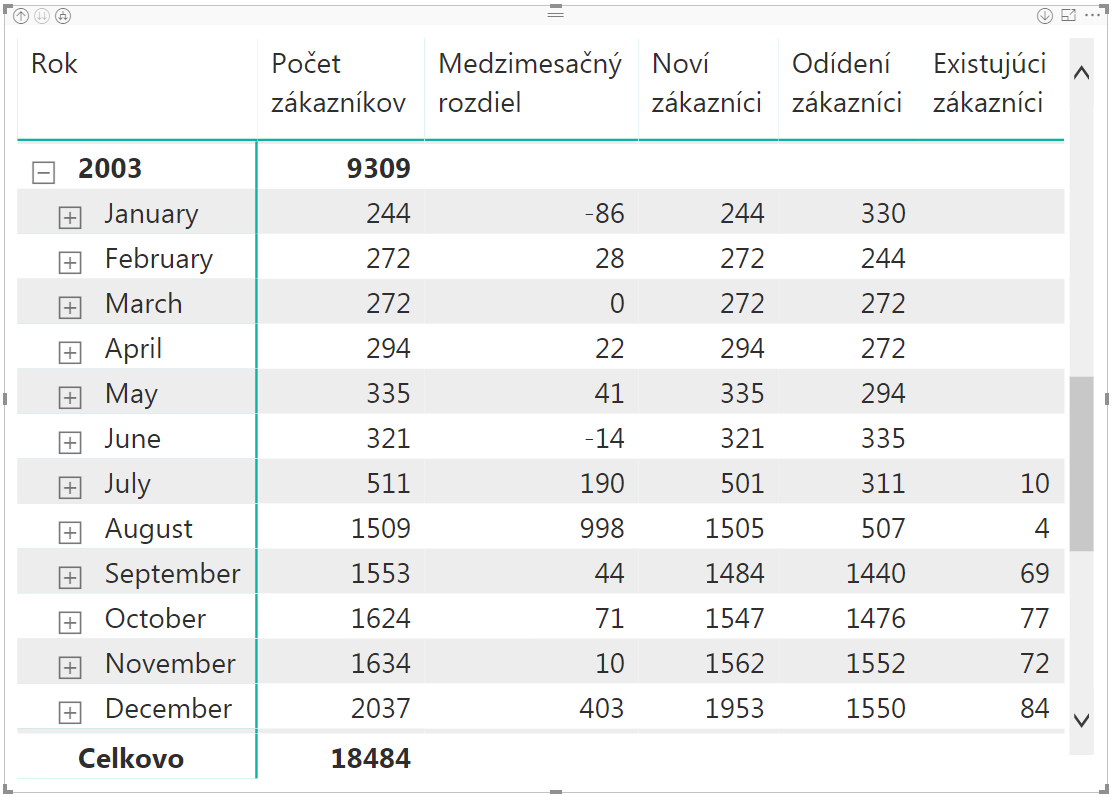
A tam už vidíte, že od polovice roka 2003 sa situácia vo firme začína zlepšovať, a konečne má aj nejakých verných zákazníkov 🙂
Takto vám teda jazyk DAX v PowerPivote, či už v Exceli alebo v Power BI, vie pomôcť s hlbšou analýzou údajov. Pretože aj na prvý pohľad dobré čísla nemusia byť zrovna dobré, keď sa na pozriete podrobnejšie. V tomto prípade sme si ukázali analýzu počtu zákazníkov medzi obdobiami, využiteľnú v predaji aj v marketingu. A ako vždy, aj toto je iba jednoduchá ukážka toho, čo jazyk DAX dokáže. A po použití tých správnych funkcií to ani moc nebolelo 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.