Vo finančnom účtovníctve a controllingu, a nielen tam, potrebujete veľakrát zobraziť zoznam otvorených položiek k danému dátumu, a k nemu aj nejakú štatistiku. Tými položkami môžu byť otvorené/nevysporiadané pohľadávky, neukončené reklamácie, či nevybavené objednávky. A najmä pri riadení činností je dobré vedieť, koľko a čo všetko bolo otvorené k danému dátumu.
My si to ukážeme na príklade s reklamáciami. Tie budú našimi položkami, ktoré budeme analyzovať. Vo všetkých ostatných prípadoch, teda napr. pri pohľadávkach či objednávkach, bude postup rovnaký.
Začneme takouto tabuľkou, ktorú nazveme Reklamácie, a ktorá bude mať nasledovné údaje:
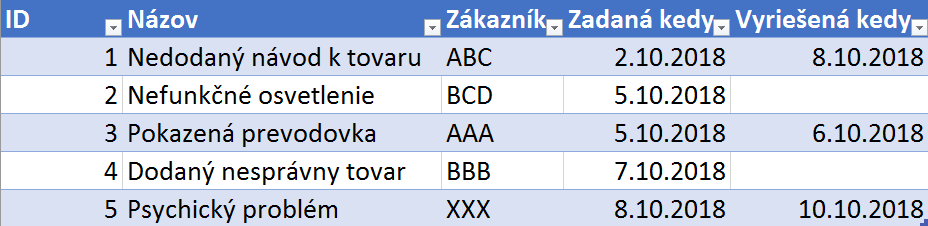
V nej máme vytiahnuté najpodstatnejšie údaje – ID reklamácie, jej názov, zákazníka, a dátum zadania a vyriešenia. Pričom si všimnite, že dátum vyriešenia nemusí byť zadaný – ak je daná reklamácia ešte stále nevybavená, resp. nevyriešená. A keďže je to bežná situácia, tak sa jej musíme prispôsobiť.
Keď teraz chceme zobraziť zoznam otvorených reklamácií k danému dátumu, tak existujú 2 riešenia – jedno jednoduché, ale nie moc flexibilné – a druhé mierne zložitejšie, ale veľmi flexibilné a rýchlo reagujúce.
Prvé riešenie
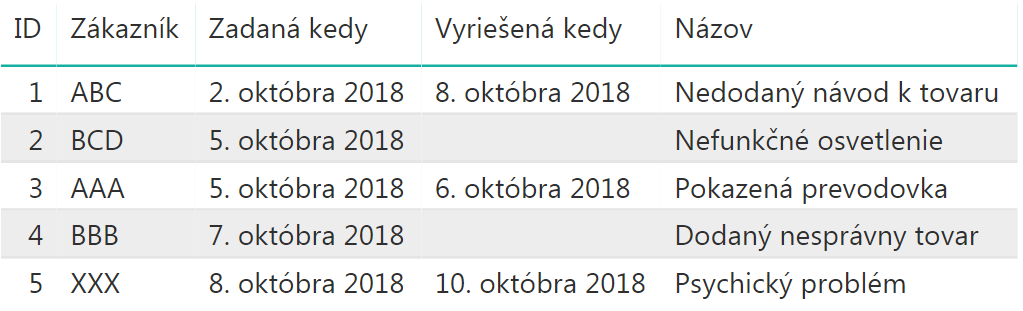
Prvé riešenie je najprv naimportovať si hore uvedenú tabuľku do dátového modelu, a potom si spraviť v reporte takúto jednoduchú tabuľku, kde budú zobrazené všetky reklamácie:
Potom si do dátového modelu naimportujeme časovú tabuľku (ak tam ešte náhodou nie je), alebo si naimportujeme takú tabuľku, ktorá bude obsahovať 1 stĺpec so všetkými použitými dátumami, ktoré súvislo nasledujú za sebou. V oboch prípadoch takúto tabuľku neprepojíme na hlavnú tabuľku s reklamáciami.
Potom si v reporte vytvoríme prehľad zo všetkých reklamácií, a vedľa neho slicer z toho dátumového stĺpca z druhej tabuľky. Nad tabuľku dajte zobraziť počet reklamácií. Bude to vyzerať nejak takto:

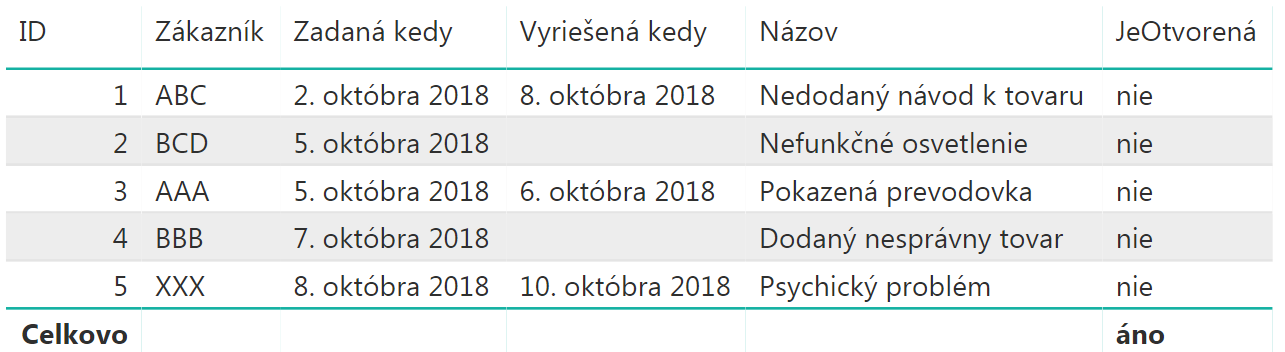
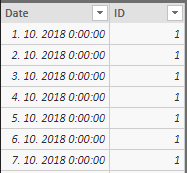
Ďalej si vytvoríme v dátovom modeli nové merítko, ktoré nazveme JeOtvorená, a ktoré bude vraciať hodnotu „áno“ alebo „nie“ pre danú reklamáciu, v závislosti od vybranej hodnoty v sliceri. Toto merítko potom pridáme do tej tabuľky v reporte:
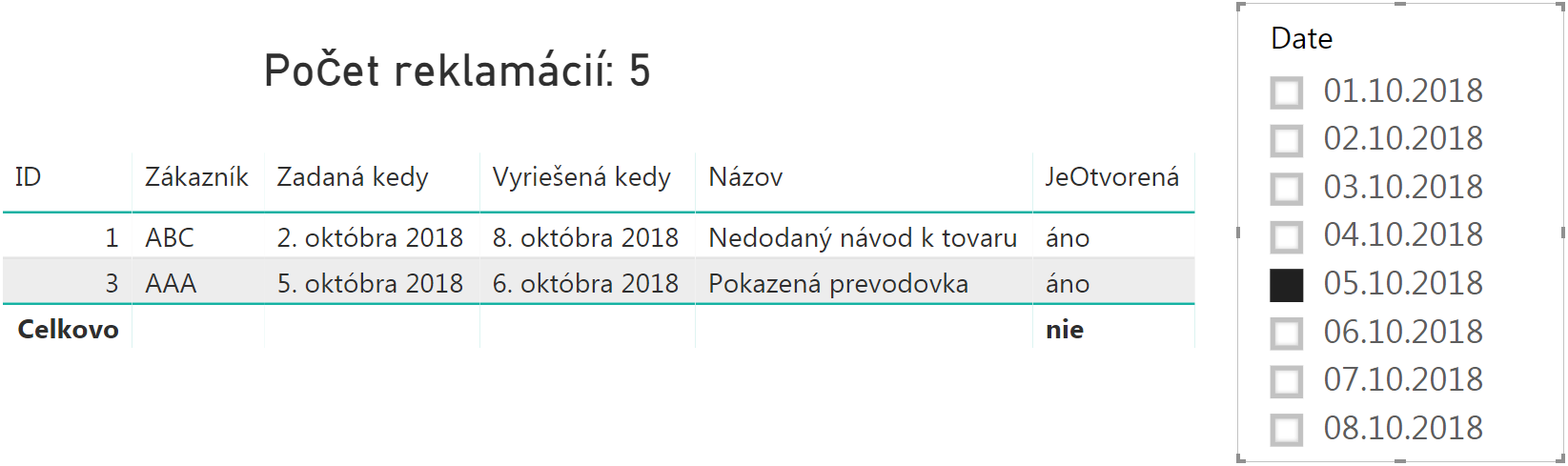
Teraz už len stačí nastaviť filter na úrovni tabuľky/vizuálu na podmienku JeOtvorená = „áno“. Po vybraní konkrétnej hodnoty v sliceri, napr. na 5.10.2018, nám to odfiltruje v tej tabuľke všetky položky len na tie reklamácie, ktoré boli otvorené k danému dátumu v sliceri:
Toto riešenie je funkčné, ale má dve nevýhody. Je použiteľné iba pre malé množstvo dát, rádovo max. pár tisíc až pár desiatok tisíc riadkov. Pri väčšom počte riadkov bude report dlho reagovať na každý preklik. Čo by ešte niektorí užívatelia vydržali.
Problém číslo 2 je však to, keď pridáme do reportu ďalší graf alebo vizuál – v našom prípade sa pozrite na vizuál nad tabuľkou, ktorý zobrazuje počet reklamácií. Tento vizuál nebude reagovať na slicer, a teda počet reklamácií v tomto prípade bude vždy zobrazovať ako 5, bez ohľadu na vybraný dátum. Ak by ste to chceli opraviť, tak buď môžete pridať ten filter JeOtvorená=“áno“ do každého grafu (veľa šťastia pri veľkých reportoch), alebo sa môžete pokúsiť dať tú podmienku do filtrov strany reportu či celého reportu. Keďže je to ale merítko, tak to nepôjde, pretože do filtrov mimo filtrov grafu/vizuálu môžu ísť iba stĺpce. A niektoré vizuály vám nedovolia ani zadať žiadne filtre.
Ako to teda vyriešiť, aby to filtrovanie išlo nastaviť globálne na celý report, prípadne aby to filtrovanie fungovalo okamžite aj na viac ako len pár tisíc riadkoch? Keď napr. máte ročne státisíce či milióny objednávok? To pôjde spraviť druhým riešením.
Druhé riešenie
V tomto prípade použijeme opäť techniku kombinačných tabuliek. Technika, ktorá mnohých odstrašuje, ale v skutočnosti je celkom fajn. Princípom riešenia bude to, že si nagenerujeme kombinačnú tabuľku, v ktorej budú kombinácie všetkých položiek so všetkými dátumami. A pre každú z kombinácií si v osobitnom stĺpci vypočítame, či bola daná položka k danému dátumu otvorená. Niečo podobné ako v sme robili v prvom článku o kombinačných tabuľkách s hotelovými izbami. V tomto prípade ale túto kombinačnú tabuľku použijeme trochu inak – prepojíme ju na pôvodnú tabuľku s položkami/reklamáciami, a nastavíme jednotlivé prvky reportu tak, aby nám to zobrazovalo to, čo chceme.
Začneme teda tým, že si naimportujeme hore uvedenú tabuľku do dátového modelu DVAKRÁT. Je to kvôli tomu, ako budeme vytvárať kombinačnú tabuľku, a ako budeme túto tabuľku prepájať. Keby sme ju naimportovali iba raz, tak by nám neskôr nechcel PowerPivot vytvoriť prepojenie medzi tabuľkami, lebo by v nich našiel cyklickú závislosť. Takže tú tabuľku naimportujeme 2x. Prvýkrát pod menom Reklamácie, druhýkrát pod menom Reklamácie2. Tú druhú kópiu dajte potom v reporte skryť.
Potom vytvoríme kombinačnú tabuľku, kde budú použité všetky dátumy v kombinácii so všetkými reklamáciami. Vytvoríme ju napr. ako vypočítanú tabuľku, týmto vzorcom:
Kombinácie = CROSSJOIN(CALENDAR(DATE(2018; 10; 1); DATE(2018; 10; 20)); VALUES(‚Reklamácie2′[ID]))
…alebo vypeknené cez DAX Formatter:

Tabuľka bude vyzerať takto (zobrazených len zopár riadkov):
V tejto tabuľke máme všetky kombinácie položiek a dátumov. Dátumy som tentokrát zadal staticky od 1.10.2018 do 20.10.2018, ale bežne ich tam zadávate cez vzorec, napr. ako VALUES(datumy) z dátumového stĺpca z časovej tabuľky. Počet riadkov v tejto kombinačnej tabuľke je zvyčajne obrovský – keď máte napr. milión položiek a analyzujete ich v rámci 1 roka, tak tam budete mať 365 miliónov riadkov. Pre PowerPivot je to však hračka, a takúto tabuľku bude počítať len pár sekúnd. Navyše, vďaka tomu, že sa v nej vo veľkom opakujú tie isté hodnoty, tak bude výborne komprimovateľná, ani nebude toľko zaberať ani v RAM, ani na disku.
Aby ste mali predstavu, koľko to spotrebuje zdrojov, tak pred pár dňami som toto použil u klienta, ktorý potreboval analyzovať 1/4 milióna položiek za 3 roky. Výsledná tabuľka mala 70 miliónov riadkov, a po uložení na disk sa súbor s reportom zväčšil iba o 20 MB. Na inej databáze, kde som mal 1,2 milióna položiek, to pre 1 rok vygenerovalo 420 miliónov riadkov. A spotreba? Zožralo to 1,4 GB RAM, a výsledný súbor sa zväčšil iba o 10 MB. V pamäti to podľa Power BI Analyzera zaberalo iba necelých 700 MB:

Spotreba pamäte počas prepočtu tabuliek je vždy dvojnásobná, pretože PowerPivot drží pôvodnú kópiu tabuľky v pamäti až dovtedy, dokým neukončí výpočet novej tabuľky. Viac o tom na Jedi Master kurze 😉 Takisto aj prekliky v takomto reporte trvali iba pol sekundy. Preto sa toho nemusíte báť. Jedine, že by ste prešvihli limit PowerPivotu, ktorý je 2 miliardy riadkov v 1 tabuľke. To viete vyriešiť buď skrátením histórie, alebo zvýšením časovej granularity pre veľmi starú históriu, alebo – ak už všetko ostatné zlyhá – preniesť dátový model na SSAS Tabular. Tam už nie je žiaden limit na počet riadkov v 1 tabuľke. Prípadne optimalizáciou kombinačnej tabuľky, ale tomu sa budem venovať až v niektorom z ďalších článkov.
Keď teda máme túto kombinačnú tabuľku, tak môžeme pre každú kombináciu vypočítať, či daná reklamácia (s daným ID) bola otvorená v danom dátume. To spravíme týmto vypočítaným stĺpcom:
JeOtvorená = IF(COUNTROWS(FILTER(‚Reklamácie2‘; ‚Kombinácie'[ID] = ‚Reklamácie2′[ID] && ‚Kombinácie'[Date] >= ‚Reklamácie2′[Zadaná kedy] && (‚Reklamácie2′[Vyriešená kedy] = BLANK() || ‚Kombinácie'[Date] <= ‚Reklamácie2′[Vyriešená kedy])))>0; „áno“; „nie“)
…alebo vypeknené cez DAX Formatter:

V tomto stĺpci robíme jednoduchý výpočet – pre každý riadok/kombináciu v tabuľke najprv funkciou FILTER vyhľadáme v tabuľke Reklamácie2 všetky riadky, ktoré majú rovnaké ID reklamácie ako aktuálne počítaný riadok v kombinačnej tabuľke, a zároveň kde dátum zadania je menší alebo rovný aktuálne počítanému dátumu z kombinačnej tabuľky, a zároveň kde dátum vyriešenia je buď prázdny, alebo je dátum vyriešenia väčší alebo rovný aktuálne počítanému dátumu. Potom otestujeme počet riadkov funkciou COUNTROWS, a keď ich je viac ako 0, tak vrátime hodnotu „áno“ (daná reklamácia v danom dátume bola ešte nevyriešená), inak vrátime hodnotu „nie“. Tento vzorec by išiel napísať aj oveľa kratšie, ale kvôli názornosti som zvolil radšej túto verziu.
Všimnite si ešte, že v tom vzorci sa odkazujeme na tú skrytú tabuľku, a teda na druhú kópiu tabuľky s reklamáciami. Je to preto, aby nám v ďalšom kroku, keď budeme prepájať túto kombinačnú tabuľku s tabuľkou Reklamácie, nevznikla cyklická závislosť pri prepájaní. Preto všetky výpočty v tejto kombinačnej tabuľke robíme z druhej kópie tabuľky, a teda z tabuľky Reklamácie2.
Prvých pár riadkov z tejto tabuľky bude vyzerať takto, a hneď si aj môžete skontrolovať správnosť výpočtu – pre prvú reklamáciu by ste tam mali vidieť „áno“ len pre dátumy 2. – 8.10.2018:
Teraz prejdeme do prepojení v dátovom modeli. Prepojíme kombinačnú tabuľku Kombinácie, s tabuľkou Reklamácie. Prepojenie spravíme zo stĺpca ‚Kombinácie'[ID] na stĺpec ‚Reklamácie'[ID]. Toto prepojenie následne nastavte ako obojsmerné:
Potom prejdeme do reportu.
Vytvorte si teraz v reporte tabuľku, kde zobrazíte z tabuľky Reklamácie všetky stĺpce. Vedľa nej potom vytvorte slicer, zo stĺpca Date v kombinačnej tabuľke. Nad tabuľku dajte zobraziť počet reklamácií:
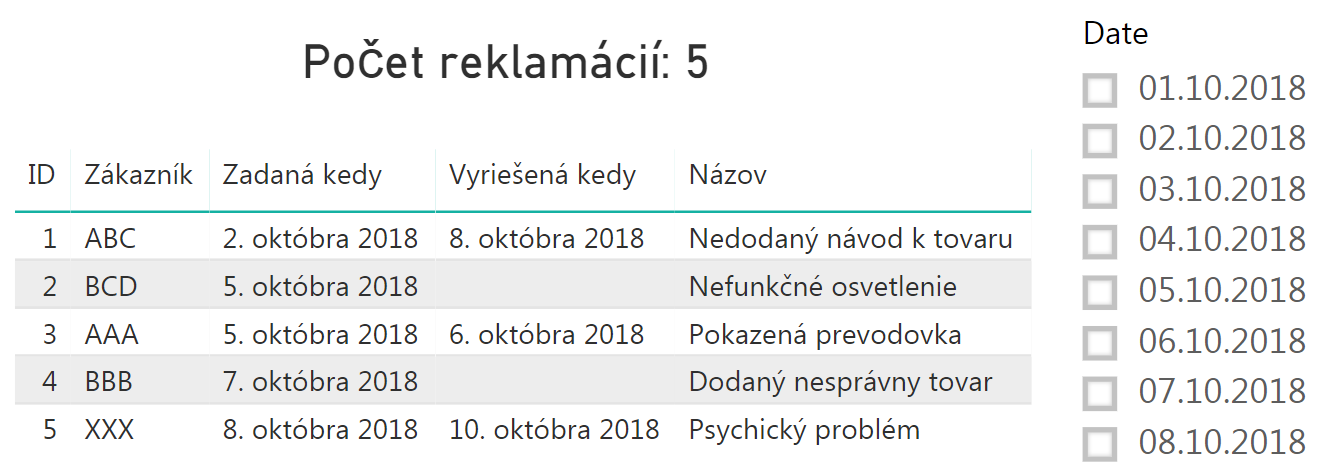
Keď teraz kliknete do slicera, nebude to mať žiaden vplyv na výsledky. Prepojenia medzi tabuľkami sú síce nastavené správne, ale keďže slicer filtruje kombinačnú tabuľku podľa dátumu, a v tej tabuľke sú pre všetky dátumy všetky reklamácie, tak to nemá zatiaľ žiaden vplyv na výsledok. Preto potrebujeme spraviť ešte jeden posledný krok – do filtrov na úrovni zostavy alebo strany zostavy pridáme filter len na otvorené položky. To spravíme tak, že do oblasti filtrov presunieme stĺpec JeOtvorená a tabuľky Kombinácie, a nastavíme filter pre tento stĺpec na hodnotu „áno“:

A potom všetko začne „magicky“ fungovať správne. Keď napr. vyberieme dátum 2.10.2018, tak dostaneme tento výsledok s položkami k danému dátumu:
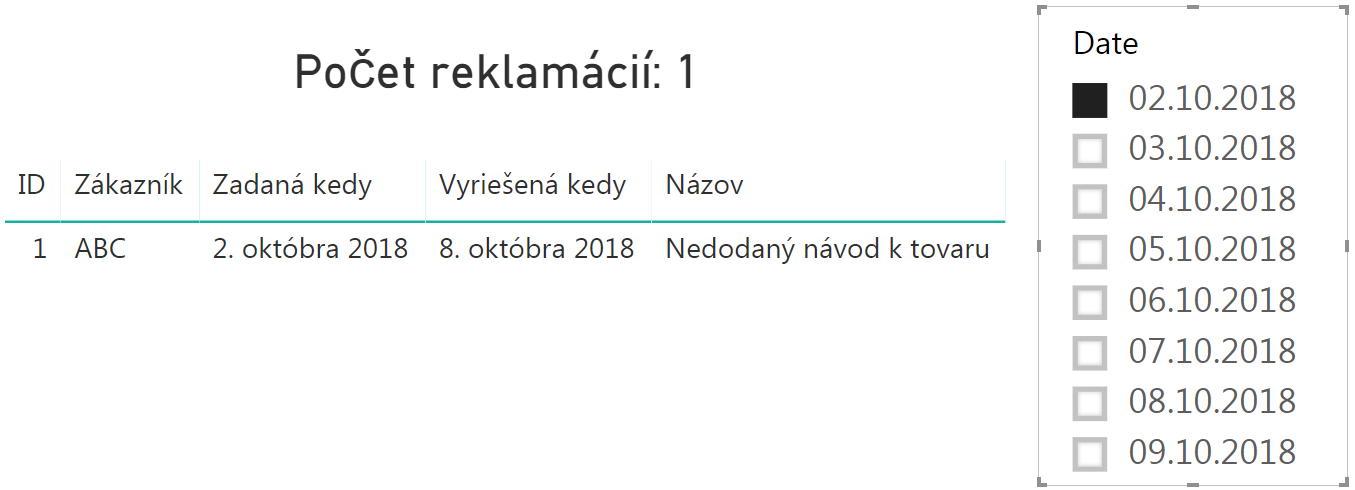
…a keď vyberieme napr. 7.10.2018, tak dostaneme tento výsledok s položkami k danému dátumu:
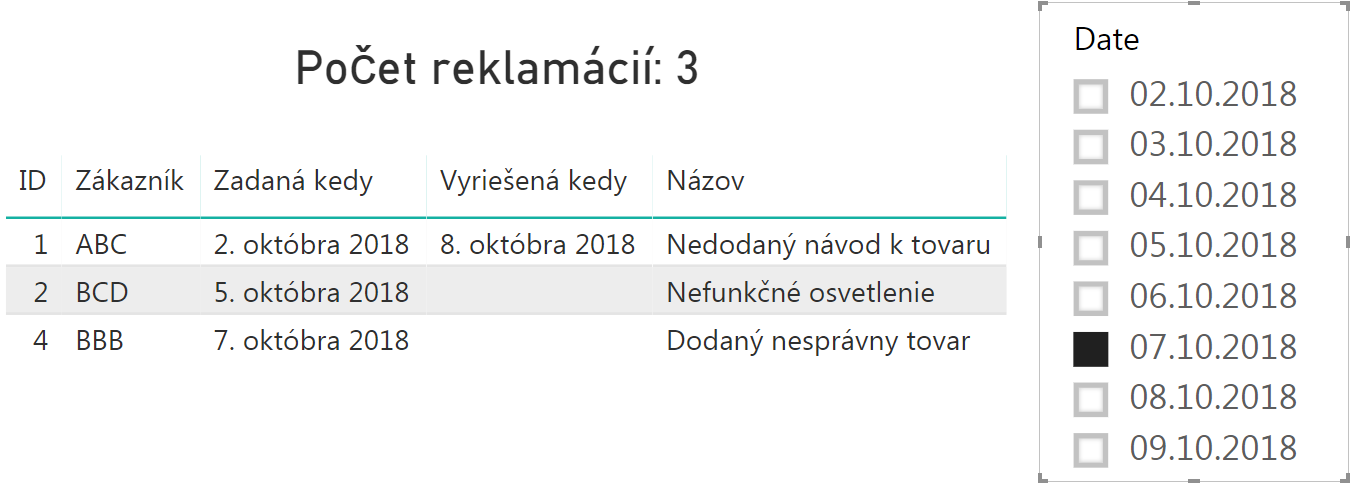
V oboch prípadoch to správne odfiltrovalo k danému dátumu aj položky, aj ich počet nad tabuľkou. A práca je hotová 🙂
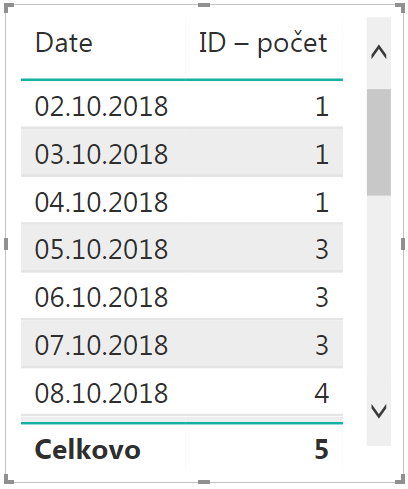
Keby ste teraz chceli napr. zobraziť počet otvorených položiek po jednotlivých dátumoch, tak si vytvorte ďalšiu stranu reportu. V nej tiež nastavte rovnaký filter JeOtvorená=áno na úrovni strany reportu. Potom stačí už len vytvoriť tabuľku s 2 stĺpcami:
- do prvého stĺpca dajte stĺpec Date z tabuľky Kombinácie,
- do druhého stĺpca dajte stĺpec ID z tabuľky Kombinácie, a nastavíte mu súhrnnú funkciu „Počet (jedinečné položky)“ alebo „Počet“, podľa toho čo chcete vidieť v celkovom súčte tabuľky.
Výsledok bude vyzerať takto:
Pre ostatné príklady sa inšpirujte ostatnými článkami o kombinačných tabuľkách. Pretože kombinačnými tabuľkami ide vyriešiť veľmi veľa analytických problémov, a najmä veľmi ľahko. A toto je ešte len začiatok toho, čo s nimi ide spraviť 🙂 Tešíte sa už na ďalšie články?
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.
Dobrý deň, skúšal som Vašu metódu s kombinačnou tabuľkou na analýzu otvorených položiek….pokiaľ som použil iba jednu podmienku tak výpočtový stĺpec sa vypočítal fakt rýchlo aj keď tam bolo niekoľko 100mil. riadkov ale akonáhle som pridal ďalšiu podmienku tak Power BI vypísalo že má nedostatok pamäti 🙁 …..postupoval som presne podľa Vášho návodu ale stále mi to hádže hlášku nedostatok pamäti. Na druhej strane keď použijem iný druh podmienky a nie dátum tak aj keď sú dve podmienky tak výpočtový stĺpec funguje správne.
Môžem Vás poprosiť o radu, že kde robím chybu ?
prikladám vzorový príklad:
https://drive.google.com/file/d/1TzpUXv7b-iXtp6QBlks9pVUTaMwuxlXi/view?usp=sharing
Vopred ďakujem za reakciu.
Dávid Kubovics
Dobrý deň,
Problém je v podmienke, ktorú používate – že druhou podmienkou chcete vyfiltrovať všetky riadky s dátumom menším ako dátum na aktuálnom riadku, čo časom vygeneruje tonu riadkov do pamäte, a na tom to spadne.
Namiesto pridávania vypočítaného stĺpca cez tlačítko „Nový stĺpec“, pridajte tento stĺpec v pôvodnom vzorci kombinačnej tabuľky cez funkciu ADDCOLUMNS. To Vám už prejde.