Pri analýze predaja potrebujete častokrát použiť skórovanie záznamov v kontingenčke. Napríklad na skórovanie predajnosti produktov či služieb, najmä ak máte široké portfólio. To samé osebe nie je ťažké spraviť. Ťažšie je však to, ak potrebujete spraviť skórovanie voči skupine vs. celku, alebo rôznym nadskupinám a podskupinám. A s trochou DAX-u ani to nebude ťažké. Preto si teraz ukážeme, ako na to.
Riešenia si opäť ukážeme na našom vzorovom súbore PowerPivotu, resp. Power BI. Vytvoríme si takúto kontingenčku:
- do oblasti hodnôt dáme merítko Obrat z tabuľky Objednávky,
- do oblasti riadkov dáme stĺpec ProductName z tabuľky Produkty.
- kontingenčku dáme zoradiť podľa merítka Obrat, od najväčšej hodnoty po najmenšiu.
Výsledná kontingenčka bude vyzerať takto:
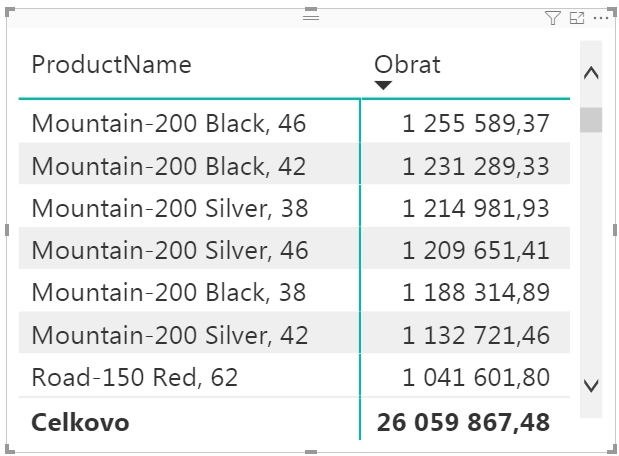
Kontingenčka zobrazuje zoznam všetkých produktov, zoradených od najpredávanejšieho po najmenej predávaný.
Jednoduché skórovanie
Teraz by sme chceli pridať do kontingenčky skóre predajnosti produktu. Čiže produkt s najvyšším obratom bude mať skóre 1, druhý najpredávanejší produkt skóre 2, atď.. Na to využijeme funkciu RANKX, ktorá slúži na skórovanie hodnôt, a má podľa oficiálnej dokumentácie takúto syntax:
RANKX(tabuľka; skórovacíStĺpec; hodnota; smerSkórovania; súvislo)
…kde význam parametrov je takýto:
- tabuľka je tabuľka so zoznamom všetkých skórovaných položiek,
- skórovacíStĺpec je vzorec v jazyku DAX, ktorý dočasne „pridá“ do tabuľky v prvom parametri skórovací stĺpec (podobne ako všetky X-kové funkcie) so skórovacími hodnotami,
- hodnota je skórovaná hodnota, a je zadaná buď ako hodnota alebo ako vzorec v jazyku DAX vracajúci hodnotu, ktorej skóre vypočíta funkcia RANKX voči všetkým skórovacím hodnotám v skórovacom stĺpci (vyrobenom v 2. parametri),
- smerSkórovania určuje, či sa použije skórovanie od najväčšej hodnoty po najmenšiu (hodnota DESC), alebo naopak (hodnota ASC),
- súvislo určuje, či sa v prípade po viacerých rovnakých skórovacích hodnách preskočia skórovacie miesta podľa počtu duplicít (hodnota SKIP), alebo nie (hodnota DENSE).
V našom prípade vyrobíme teda takéto jednoduché merítko, ktoré nám vypočíta skóre predajnosti produktu:
Skóre predajnosti := RANKX(ALL(Produkty[ProductName]); [Obrat]; [Obrat]; DESC; Dense)
Do prvého parametra sme dali tabuľku so zoznamom všetkých produktov. Do druhého parametra sme dali merítko Obrat, čo nám k tabuľke so zoznamom všetkých produktov dočasne „pridá“ ďalší stĺpec s obratom za daný produkt. V treťom parametri je skórovaná hodnota, kde opäť zadáme merítko Obrat. V tej kontingenčke vyššie to bude znamenať, že ako skórovanú hodnotu chceme použiť obrat za aktuálne počítaný produkt. Vo štvrtom parametri použijeme hodnotu DESC, pretože chceme skórovať od najvyššej hodnoty Obratu po najmenšiu. A v poslednom parametri použijeme hodnotu DENSE, pretože chceme súvislo oskórovať všetky produkty, bez vynechávania miest, aj keby viacero z nich malo rovnaký obrat.
Po pridaní merítka do kontingenčky to bude vyzerať takto:
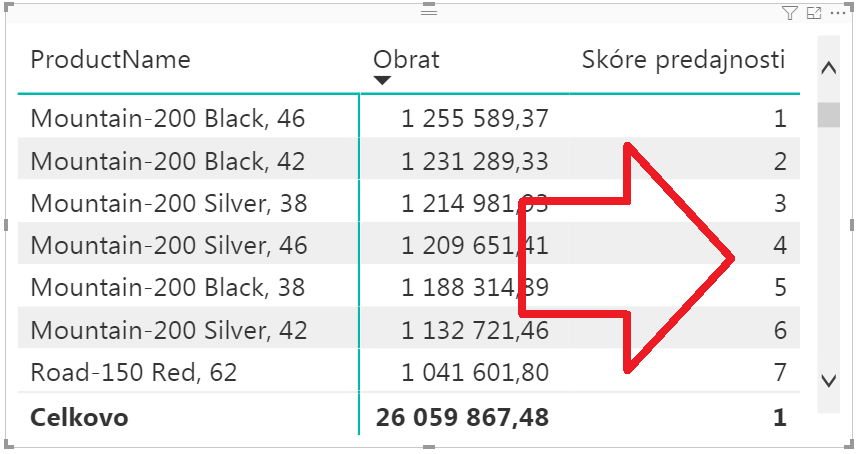
Tam vidíte, že najpredávanejší produkt má skóre 1, druhý má 2-ku, a tak ďalej.
Skórovanie voči skupine
Teraz by sme chceli vypočítať takéto skóre aj pre skupinu, resp. nadskupinu. Do našej kontingenčky pridáme napríklad stĺpec Krajina z tabuľky Regióny, do oblasti riadkov na prvú pozíciu, a rozbalíme všetky krajiny:
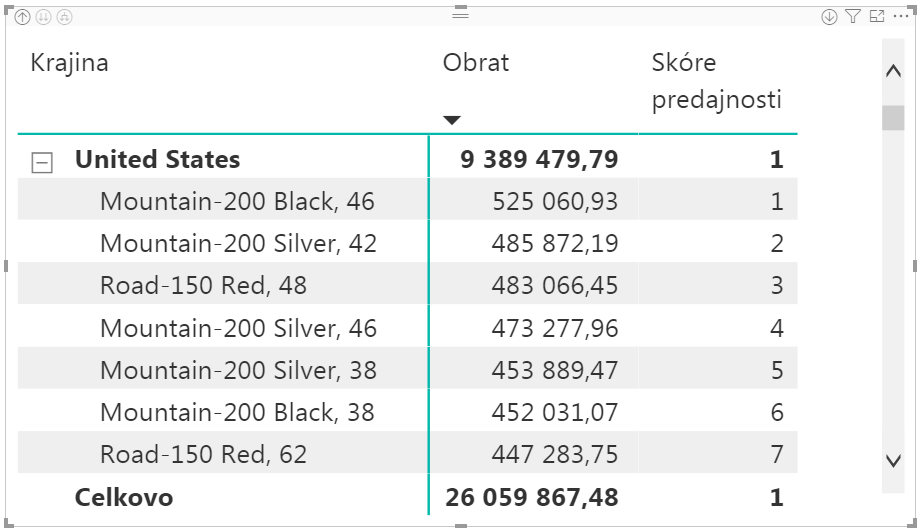
Ako vidíte, funguje to bez akéhokoľvek zásahu aj v tomto prípade. Potiaľto fajn.
Teraz by sme však chceli skombinovať obe kontingenčky dokopy. Čiže vedľa skóre predajnosti produktu v danej krajine, by sme chceli mať aj skóre toho istého produktu v celkovej predajnosti. Čiže by sme chceli spraviť klasické skórovanie voči skupine vs. celku. Po troche zamyslenia sa nad kontextom výpočtu, jeho filtrami a štruktúrou vzorca, nám stačí vytvoriť takéto jednoduché merítko:
Skóre predajnosti celkovo :=
CALCULATE([Skóre predajnosti]; ALL('Regióny'[Krajina]))
…a po pridaní do kontingenčky nám to vypočíta to, čo sme chceli:
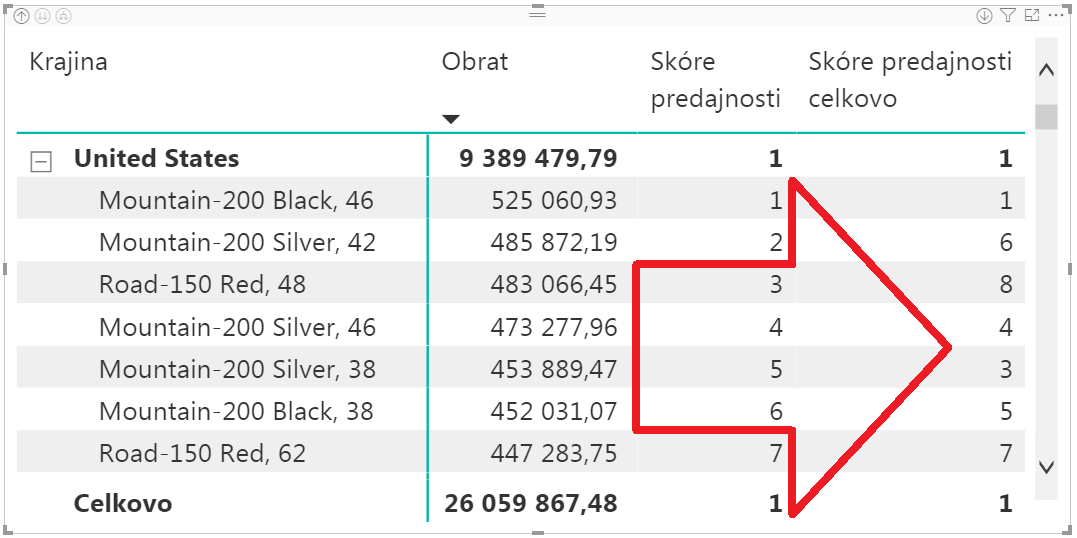
Princíp riešenia je jednoduchý – zmenili sme kontext výpočtu tak, že sme odstránili filter nad stĺpcom Krajina, a v takomto novom kontexte výpočtu sme vypočítali merítko „Skóre predajnosti“. Nemuseli sme znova písať iný RANKX, len sme opätovne využili už existujúce merítko a základné vlastnosti kontextu výpočtu.
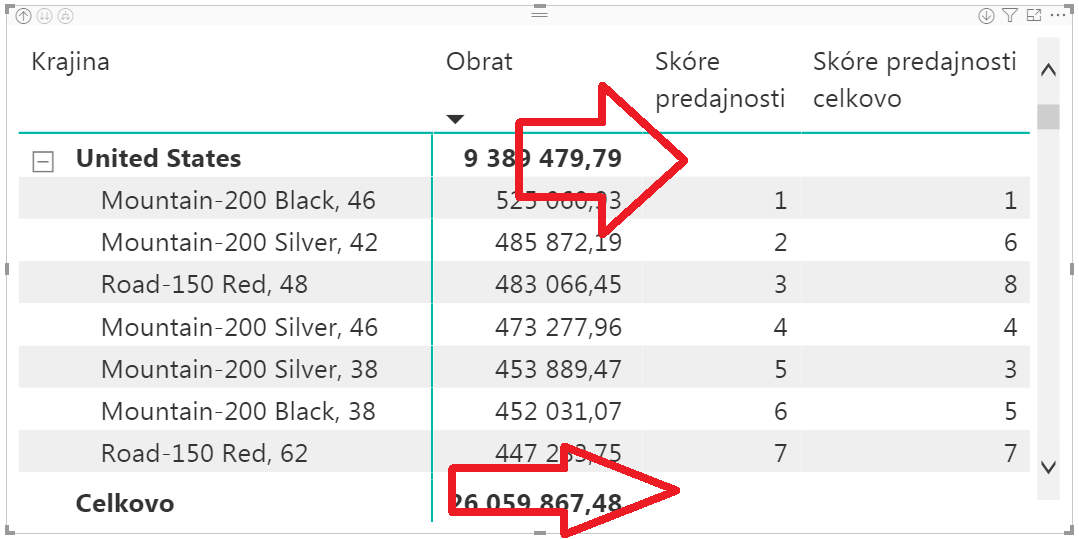
V tejto kontingenčke vidíte napríklad to, že produkt s názvom „Mountain-200 Silver, 42“ je v USA 2. najpredávanejší produkt, ale celkovo je až 6. najpredávanejší produkt. Rovnako, ako ste to videli v pôvodnej kontingenčke bez krajín.
Doladenie do dokonalosti
Toto riešenie počíta výsledky správne, ale má ešte 2 drobné muchy, ktoré môžete, ale nemusíte odstrániť, ak to chcete doladiť k dokonalosti.
Prvá drobnosť je to, že skóre to počíta aj v celkových súčtoch aj medzisúčtoch, kde to nemá zmysel. To opravíme tak, že v pôvodnom merítku „Skóre predajnosti“ pridáme test, či sme na úrovni produktu alebo nie, a skóre budeme počítať iba vtedy, keď sme na úrovni produktu:
Skóre predajnosti := IF(ISINSCOPE(Produkty[ProductName]); RANKX(ALL(Produkty[ProductName]); [Obrat]; [Obrat]; DESC; Dense))
To spoľahlivo prestane počítať obe skórovacie merítka, ak sme na inej úrovni, ako na úrovni produktu:
Druhou drobnosťou je to, že toto skóre sa počíta aj pre produkty, ktoré sa nikdy nepredali:
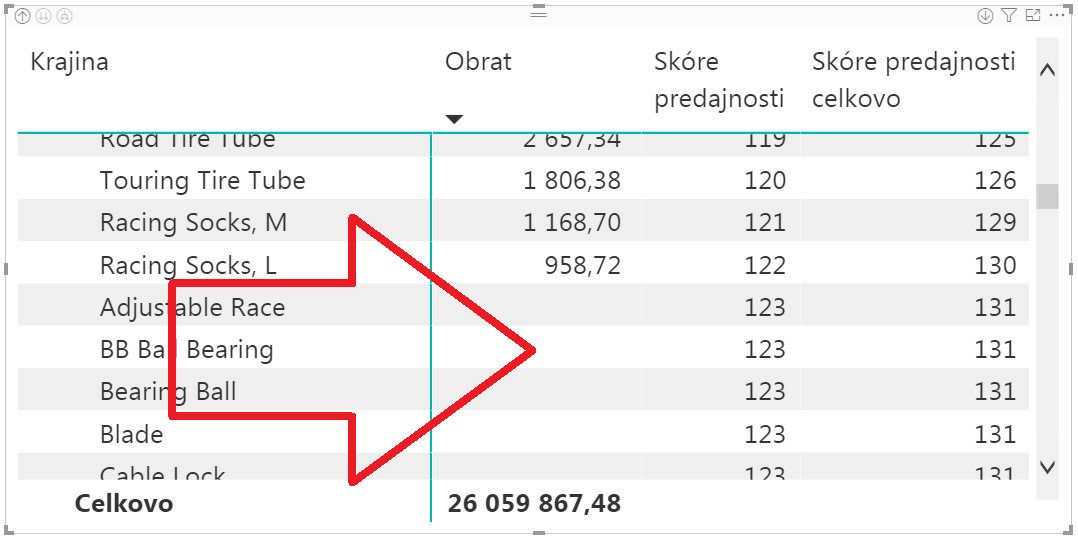
Pretože aj také produkty sú v našej databáze, a prázdna hodnota sa berie ako skórovacia hodnota nula. Preto pridáme do vzorca vyššie ešte test na neprázdny Obrat, podobne ako sme o tom písali v článku o tom, ako vypočítať ukazovateľ v závislosti od existencie/neexistencie hodnoty iného ukazovateľa:
Skóre predajnosti := IF(ISINSCOPE(Produkty[ProductName]) && [Obrat] <> BLANK(); RANKX(ALL(Produkty[ProductName]); [Obrat]; [Obrat]; DESC; Dense))
…a to nám opraví aj túto drobnosť:
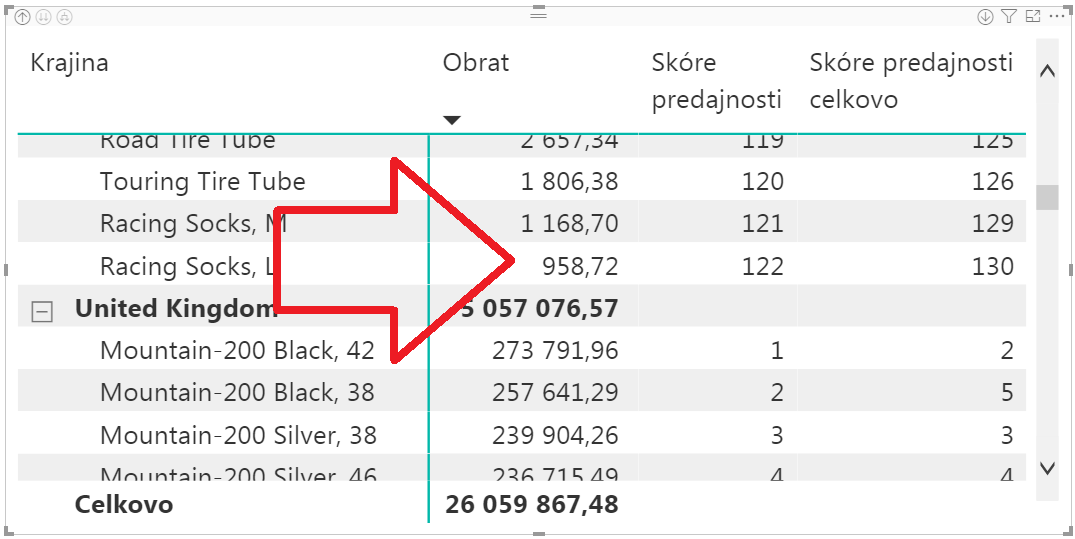
Takto teda viete vypočítať nielen jednoduché skóre, ale robiť aj plnohodnotné skórovanie voči skupine vs. celku v jazyku DAX. Funguje to rovnako v excelovskom PowerPivote aj Power BI, pretože to používa klasické DAX-ové funkcie. Teda okrem posledných 2 vzorcov, ktoré fungujú iba v Power BI, a pre PowerPivot v nich potrebujete nahradiť funkciu ISINSCOPE inými funkciami. A najmä, takto je skórovanie voči rôznym skupinám, podskupinám aj celku naozaj hračka 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.