Jazyk DAX obsahuje celú jednu sadu funkcií, ktoré sa často používajú pri výpočtoch, ale užívatelia im nie vždy rozumejú správne. Sú to tzv. X-kové funkcie, a používajú sa dosť často v pokročilejšej analytike. Takisto sa používajú vtedy, keď klasické funkcie ako SUM alebo COUNT nechcú zobrať na vstupe to, čo by užívateľ chcel. Pozrieme sa teraz teda na to, ako pracujú, a čo počítajú.
X-kové funkcie všeobecne
X-kové funkcie sú funkcie ako SUMX či COUNTX, ktoré obsahujú písmeno X na konci svojho názvu. Teda až na pár výnimiek ako napr. VARX.P, ktoré obsahujú X pred bodkou. Prečo to takto v MS navrhli, sa spýtajte ich mágov 🙂
X-kové funkcie sú funkcie, ktoré vykonávajú výpočty nad zadanou tabuľkou. Sú väčšinou párovými funkciami ku klasickým sumarizačným funkciám ako SUM, COUNT, MIN, MAX a pod.. Čiže máme SUMX, COUNTX, MINX, MAXX a pod.. Na rozdiel od klasických sumarizačných funkcií ako SUM, ktoré berú na vstupe iba odkaz na stĺpec, tieto x-kové funkcie berú na vstupe tabuľku a vzorec. A v tom vzorci môžete použiť nielen stĺpce, ale aj merítka. Vďaka tomu sa tieto funkcie používajú nielen ako náhrada pre klasické sumarizačné funkcie, keď „to nejde“, ale aj ako náhrada klasických excelovských funkcií ako SUMIF, SUMIFS, COUNTIF, COUNTIFS a pod..
Syntax
Všeobecná syntax týchto funkcií je nasledovná:
funkciaX(tabuľka; vzorec)
…kde tabuľka je fyzická tabuľka alebo daxový vzorec vracajúci tabuľku, nad ktorou bude prebiehať výpočet. A vzorec je daxový vzorec, ktorý sa vyhodnotí pre každý riadok tejto tabuľky, a jednotlivé výsledky sa zosumujú tou funkciou, ktorá je uvedená pred písmenom X. V tom vzorci v 2. parametri x-kových funkcií môžete použiť ľubovoľný daxový vzorec, vrátane merítok.
X-kové funkcie sú iterátory. Čiže funkcie, ktoré spravia niečo pre každý riadok zadanej tabuľky, alebo počítajú niečo riadok po riadku v zadanej tabuľke. Kvôli tomu vznikol na internete mýtus, že musia byť pomalé, ale nemusí to byť pravda. Dokým si to nevyskúšate, neodmeriate a neoddebugujete, napr. cez DAX Studio, tak sa to dopredu vo všeobecnosti nedá povedať, či to bude rýchle alebo pomalé. O tom rozhoduje interný PowerPivot a jeho enginy, ktoré to spracúvajú. A tie sa niekedy aj každý mesiac menia, a sú čoraz inteligentnejšie.
Navyše tým, že sú to iterátory, tak pri vyhodnocovaní daného riadku tabuľky vidia iba na daný riadok v danej tabuľke. Ak chcete, aby videli aj na iné tabuľky, tak musíte zmeniť kontext výpočtu, alebo použiť pravidlá pre cestovanie medzi tabuľkami – pomocou funkcií RELATED a RELATEDTABLE.
Nahradenie SUM, COUNT a vypočítaných stĺpcov
Jednoduché použitie X-kových funkcií si ukážeme opäť na našom vzorovom súbore PowerPivotu, resp. Power BI. Keď sa pozriete do tabuľky Objednávky, tak v ňom nájdete stĺpec „Cena objednávky“:
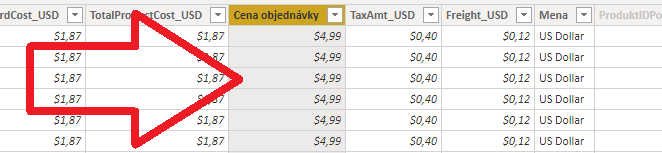
Toto prehlásime za cenu bez DPH. Keď teraz chceme vypočítať DPH-čku, napr. s fixnou sadzbou 20%, tak by sme to chceli spraviť takýmto merítkom:
Cena DPH test := SUM(ROUND('Objednávky'[Cena objednávky] * 0,2; 2))
To nám však vráti nasledovnú chybu:

Je to preto, že klasické funkcie akceptujú za svoj parameter iba odkaz na čistý stĺpec, a nič viac. A my sme dali do parametra vzorec ROUND(…), čo nie je povolené.
Kvôli tomu sa to zvykne obchádzať tak, že sa do príslušnej tabuľky vytvorí vypočítaný stĺpec s týmto vzorcom, ktorý sa neskôr v kontingenčke zosumuje:
Cena DPH = ROUND('Objednávky'[Cena objednávky] * 0,2; 2)
To vyrobí takýto stĺpec v tabuľke:

Výpočet je správny, ale má to drobnú chybičku krásy. Každý vypočítaný stĺpec zaberá miesto v pamäti, zväčšuje dátový model, a keď si nedáte pozor, tak už po zopár vypočítaných stĺpcoch môžete mať dátový model niekoľko násobne väčší ako predtým. Pritom takéto výpočty nemusíte zmaterializovávať do stĺpcov, ale viete ich vypočítať aj cez merítka. S tým bonusom, že merítka nezväčšujú veľkosť dátového modelu, počítajú sa za behu len vtedy keď je to potrebné, a vedia dynamicky reagovať aj na užívateľské akcie v reporte.
X-kové funkcie a merítka
Hore uvedený vzorec sa dá napísať cez X-kové funkcie a merítko nasledovne:
Cena DPH cez merítko :=
SUMX('Objednávky'; ROUND('Objednávky'[Cena objednávky] * 0,2; 2))
Predpokladáme, že užívateľ bude chcieť ten pôvodný stĺpec „Cena DPH“ sumovať, a teda použijeme funkciu SUMX. Do prvého parametra zadáme tabuľku Objednávky, pretože chceme prechádzať objednávky jednu po druhej, a pre každú z nich vypočítať DPH-čku. Ten výpočet dáme do druhého parametra, a použijeme rovnaký vzorec aký sme použili pre vypočítaný stĺpec vyššie.
Táto funkcia SUMX pôjde teraz riadok po riadku každej objednávky, a pre každý riadok vyhodnotí vzorec v 2. parametri. Jeho výsledok si uloží ako keby do dočasného skrytého stĺpca, pre každý riadok. Keď ukončí výpočet riadok po riadku, tak tento skrytý stĺpec zosumuje funkciou SUM (lebo sme použili SUMX) a vráti výsledok.
Keď si teraz poskladáme napr. takúto kontingenčku, že:
- do oblasti hodnôt dáme z tabuľky Objednávky merítko Obrat, stĺpec „Cena DPH“ a merítko „Cena DPH cez merítko“,
- do oblasti riadkov dáme stĺpec CalendarYear z tabuľky Čas.
…tak vo výslednej kontinenčke uvidíme, že čísla pre zosumovaný stĺpec „Cena DPH“ a pre merítko „Cena DPH cez merítko“ sú identické:
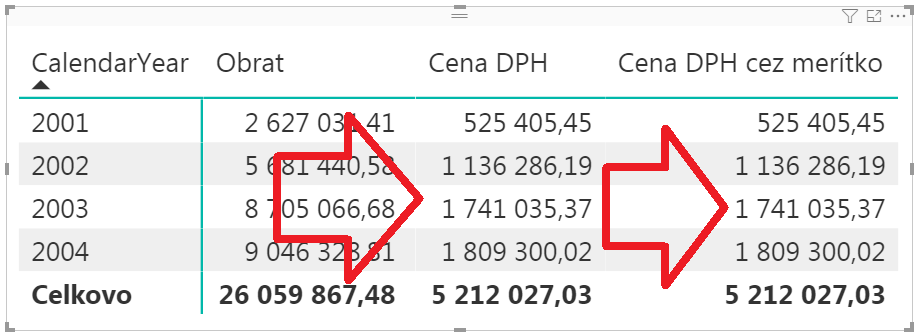
Odkaz na tabuľku Objednávky vo vzorci so SUMX pritom neodkazoval na všetky objednávky z tej podkladovej tabuľky, ale len na tie objednávky, ktoré sú viditeľné v aktuálnom kontexte výpočtu. Čiže len na tie objednávky, na ktoré vidí aktuálne počítaná bunka reportu. Napríklad bunka pre rok 2002 vidí len na objednávky z roku 2002, a bunka pre rok 2003 vidí len na objednávky za rok 2003. Je to zjednodušene tým, že vzorec merítka sa spúšťa pre každú bunku reportu osobitne, a štandardne vidí iba na tie riadky, ktoré prislúchajú hodnotám/filtrom na osi vizuálu – čiže v našom prípade jednotlivým rokom. Preto nemusíme vo funkcii SUMX hovoriť, ktoré objednávky chceme, ale stačí uviesť iba odkaz na tabuľku Objednávky, a DAX si to už sám „spáruje“.
Náhrada SUMIF, COUNTIF a podobne v jazyku DAX
Druhá častá oblasť, kde sa používajú X-kové funkcie, je náhrada excelovských funkcií SUMIF, SUMIFS, COUNTIF, COUNTIFS a podobne, ktoré v jazyku DAX nemáme, ale za to sa dajú zapísať elegantnejšie hneď niekoľkými spôsobmi. A pre bežného excelistu je najjednoduchší zápis cez X-kové funkcie.
V staršom článku som sa už venoval jednému možnému zápisu funkcie SUMIF v DAX-e pre vypočítané stĺpce. Nie je síce elegantný, ale nájdete ho na tomto odkaze.
My si ukážeme ešte ďalší príklad, tentokrát ako to použiť v merítku. Povedzme, že by sme chceli vypočítať obrat iba za veľké objednávky. Čiže sumu objednávok, ktorých cena v stĺpci „Cena objednávky“ je väčšia ako 5000. To vieme spraviť takto ľahko:
Obrat za veľké objednávky :=
SUMX('Objednávky';
IF('Objednávky'[Cena objednávky] > 5000; 'Objednávky'[Cena objednávky]; 0)
)
V tomto vzorci znova použijeme funkciu SUMX. V ňom budeme prechádzať znova cez riadky tabuľky Objednávky. A pre každý riadok spustíme funkciu IF, ktorou otestujeme, či je „Cena objednávky“ väčšia ako 5000. Ak áno, tak pre daný riadok vrátime cenu objednávky, inak vrátime nulu. Vo výsledku tá funkcia IF vráti ceny iba tých objednávok, ktoré sú nad 5000, a pre všetky ostatné vráti nulu, a to sa uloží do toho ako keby skrytého dočasného stĺpca. Zosumovaním takéhoto stĺpca funkciou SUM – keďže sme použili SUMX – dostaneme sumu, resp. obrat za veľké objednávky:

DAX-ová logika vs. excelovská logika
Tento výpočet je správny, ale na miliónoch riadkov už bude pomalý. Dôvodom je to, ako interne fungujú výpočty v PowerPivote aj Power BI, ako učím napr. na Jedi Master kurze. Hlavným dôvodom je ale to, že je to napísané excelovskou logikou, a nie daxovou logikou. V jazyku DAX sa po správnosti rozmýšľa úplne inak, a rovnaký výsledok dostanete týmto bleskurýchlym a zároveň oveľa jednoduchším vzorcom, ktorý sa bude počítať okamžite aj na desiatkach miliónov riadkov:
Obrat za veľké objednávky Pro :=
CALCULATE([Obrat]; 'Objednávky'[Cena objednávky] > 5000) + 0
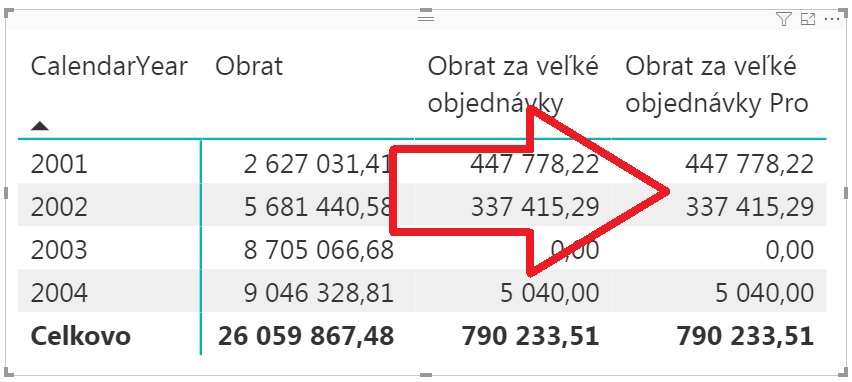
Detailné vysvetlenie máte v článkoch o kontexte výpočtu a indickom zápise filtrov, takže to tu už nebudem znova rozpisovať. Podstatné je to, že takto sa správne rozmýšľa v jazyku DAX, a preto to aj bude počítať podstatne rýchlejšie. Chyba pritom nebola vo funkcii SUMX, ale v tom, čo a ako sme použili, v spolupráci s tým, ako interne fungujú výpočty. Ale to by už bolo na veľmi dlho 🙂 Správnosť výpočtu oproti predchádzajúcemu spôsobu si overíte po pridaní tohto merítka do kontingenčky:
Takto sa teda základne používajú X-kové funkcie v jazyku DAX. Na mnohé výpočty sú nenahraditeľné, a v pokročilej analytike sa bez nich nezaobídete. O to viac ich však oceníte, keď si na ne zvyknete a začnete ich používať. Po čase zistíte, že to až tak nebolelo, a najmä že znova posuniete svoje schopnosti v DAX-e o niečo ďalej 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.